八爪鱼是一款网页爬虫工具,可以不用编写代码快速实现网页数据的爬取。
关于其基础操作,可以在其官网的使用教程http://www.bazhuayu.com/tutorialIndex 进行查看。其中主要针对其翻页和带有验证码的登录以及xpath操作进行阐述。
特殊翻页
数字翻页
在制作采集规则时,页面没有“下一页”等翻页按钮,而是一排页码,如"1","2","3","4","5"……
如何通过数字翻页的进行处理?
解决思路:
找到一条xpath,使得在当前页(除未页外)始终能定位到下一页。
示例网址:http://stock.cngold.org/news/
常用函数:following-sibling::*
比如://span[@class=”page_curl”]/ following-sibling=a[1]
其中先找到数字页码1所在的位置为span,其class为page_url,这样就定位到了数字1所在的那个span。然后使用following-sibling找到其兄弟元素去定位下一页,找到其下一页也即是第2页所在的位置为a标签,由于后面所有同级元素的页码都是a标签,所以使用a[1]表示第1页后的第一个a标签。
“加载更多”的翻页形式
适用情况:
要采集的网页中,有“加载更多”或“再显示20条”等按钮,点击这些按钮之后需要采集的数据才会完全显示出来。
比如下列情况,需要点击“加载更多内容”,而且每点击一次多显示20条的数据:
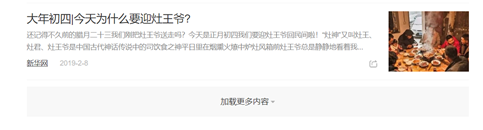
解决思路:
按照常规操作,创建翻页循环,然后将循环翻页步骤拖到循环-提取数据步骤前,让所有翻页完成之后,再进行循环提取数据步骤,不然会很多重复数据。
循环翻页的点击按钮一般是ajax加载,即点击翻页的高级选项需勾选ajax,并设置超时时间(时间长短根据数据加载快慢设置),不要勾选新标签。
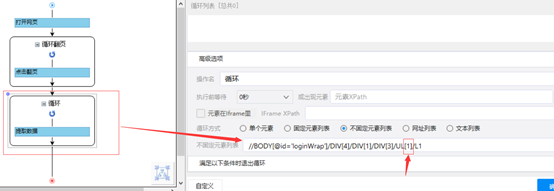
比如,针对https://weixin.sogou.com/网页,常规的是先循环点击“加载更多内容”,比如下左图,如果这样执行采集数据之后,得到的将是前20条数据的循环采集。
对于此种情况,我们需要将循环提取数据拖到循环翻页下面,如右图,这样就会先将所有的数据都加在出来,再一起执行数据的提取了。注意,有时候数据太多,它会无限制地执行加载数据,此时可以对翻页设置循环次数限制。另外,需改变循环提取数据的xpath如下图,否则只能提取前20条数据。


某几页重复循环现象
适用情况:重复采集网页中某几页的数据
现象:
采集结果出现重复,在翻看数据后发现是重复了采集网页中某几页的数据。例如,重复采集一二页的数据。
原因分析:
网页中有上一页按钮,也有下一页按钮,xpath定位不准,在某一页会定位到上一页按钮,导致重复采集某几页数据
解决思路:
修改xpath,使在当前页(末页除外),只能定位到下一页按钮
比如:有的网页在执行某一页之后的翻页时候,它的xpath会同时定位到上一页和下一页按钮,这时候需要重新修改它的xpath,使其只能定位到下一页,比如原有的xpath://a[@class=”next”],观察其源码,需要将其修改为://a[@class=”next” and text()=”下一页”]
最后一页死循环现象
适用情况:
要采集的网页,明明已经采完了最后一页的数据,但重复采集最后一页数据,不停止采集。
或者循环点击下一页后不进行翻页,一直在采集某一页的数据。
原因分析:
xpath定位不准,在最后一页还能定位到“下一页”按钮,循环翻页无法结束
解决思路:
修改xpath,使当前页是最后一页时,定位不到“下一页”按钮,而非最后一页时可以定位到“下一页”(分别观察当前页是最后一页的时候和不是最后一页的时候的下一页的定位xpath,然后修改其xpath)
其它翻页现象
1.输入页码,点击“跳转”或“确定”按钮进行翻页
示例网站:http://hotels.ctrip.com/hotel/434391.html
点击输入数字页码输入框,选择输入文字,点击确定,然后在流程中拖进去一个循环框,将输入文字拖进循环框,并将其设置为从循环选择内容,然后设置循环内容为1,2,3等的页码即可。
2.将循环翻页转换为URL循环
http://www.bazhuayu.com/tutorial/gnd
这种可以在输入网址的时候直接输入多个网址,以换行符换行,然后进行采集数据即可。
3.进行几次翻页后,直接跳到后几页(漏数据-漏几页数据未采集)
适用场景:
因点击翻页导致的某几页未采集。如,进行几次翻页后,直接跳到后几页。
示例网址:https://www.zhongtou8.cn/financing/index/page/1
解决思路:
找到一条xpath,使得在当前页(除未页外)始终能定位到下一页。
示例网站:https://www.zhongtou8.cn/financing/index/page/1/prov/0/indid/0/v/0/status/
以上方式不仅可以解决部分网站的无法翻页或翻页后容易出现采集中断问题,还可以在一定程度上避免网站的防采集措施。
登录与验证码
Cookie登录
输入账号密码登录之后打开网页步骤设置获取cookie,此时可以删除之前的输入账号密码的步骤。如果要以当前账号新建任务也可以复制打开网页的网址新建任务。注意:cookie是有生命周期的;如要更换账号,设置打开网页时清楚缓存。
验证码登陆:设置执行前等待方法
适用场景:
登录页面在输入用户名和密码后,还需做验证码识别才能正常登录,
重点针对于滑块拖动验证,点击选择某些图片或文字,拼图验证,
以及其余各种验证码识别控件不能自动识别的验证码类型。
对于此种需要验证码才能登录的场景,可以通过设置执行前等待,完成验证码识别。
做法:在输入账号密码之后的点击登录的步骤,设置执行前等待的时间,比如15s,则当采集数据的时候当到输入验证码的时候,系统会给用户留出15s的时间来输入验证码,15s之后会自动执行登录步骤。注意:只适用于本地采集,不用于云采集。
验证码登陆:控件识别方法
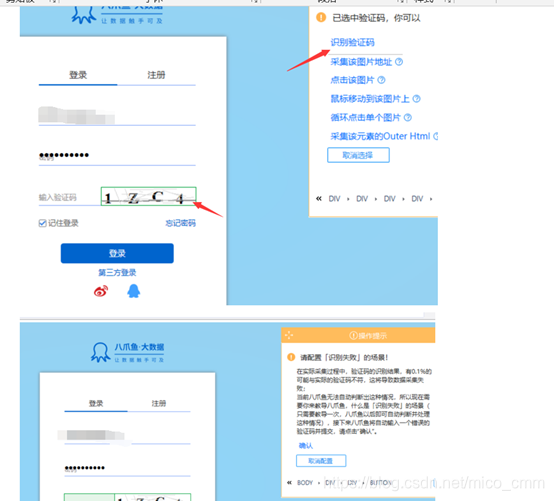
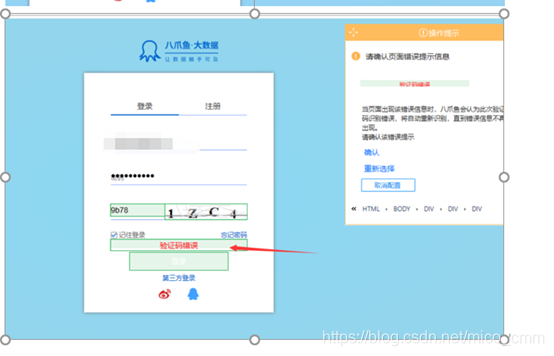
对于有验证码需要输入的情况,也可以设置控件识别。做法为:
如下图,输入账号密码后,先点击验证码图片,然后点击验证码输入框,再按照提示输入验证码识别错误和正确的配置信息即可。
Iframe框架
Iframe框架是什么:
有些网站的登录框其实是iframe的登录框,iframe即html标签,会创建包含另外一个文档的内联框架(即行内框架),含义是网页中的网页。有时候因为网页使用的是iframe框架会定位不到输入框。
如何查看网页是否使用Iframe框架:
借助火狐浏览器来查看。以具体网址来看一下,例如天猫的登录页就使用了iframe的登录框架。
1、将网页在火狐浏览器中打开
2、将鼠标移至天猫登录框,右键右击后选择“此框架”>>“在新标签页中打开框架”
八爪鱼中iframe框架的处理:
八爪鱼一般能自动识别网页中的iframe框架,并生成相应iframe框架的XPath。如遇到不能生成的,则需先在浏览器中定位到该框架,然后将iframe框架的XPath填入八爪鱼中。软件支持一层iframe框架,若网站有多层框架,则应先去除多余框架。或将在浏览器中得到的该框架的地址复制进去八爪鱼。
XPath
XPath简介
XPath是专门针对xml设计的,在复杂结构化数据中查找信息的语言,简单来说,就是利用一条路径表达式,找到我们需要的数据位置。
查看/自动生成xpath的方法
1、通过火狐浏览器里面的firebug和firepath插件生成/查看XPath
注:火狐浏览器需是55版本以下,过高的版本可能无法使用firebug和firepath插件,安装时和安装后均需禁止浏览器自动更新。
54版本火狐浏览器的下载地址:
64位火狐54:http://ftp.mozilla.org/pub/firefox/releases/54.0.1/win64/zh-CN/
32位火狐54:http://ftp.mozilla.org/pub/firefox/releases/54.0.1/win32/zh-CN/
其他版本下载地址:http://ftp.mozilla.org/pub/firefox/releases/
在火狐浏览器中的菜单中的附件管理器中搜索firebug和firepath插件进行安装,安装后需要重启即可使用。
2、通过八爪鱼采集器生成/查看XPath
八爪鱼采集器内部有一套针对html的XPath引擎,直接用XPath就能精准的查找、定位网页里面的数据,从而进行数据提取。在八爪鱼中进行规则配置的时候,会自动生成定位数据的XPath
在八爪鱼规则配置中,除了打开网页步骤没有XPath外,其他步骤都涉及到XPath定位
查找xpath方式,如下图:


XPath节点
在 XPath 中,所有事物都是节点。共有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释、文档(根)节点。
XPath语法
XPath轴:定义当前节点与其他节点间的关系。
XPath语法:使用路径表达式来选取html文档中的节点或节点集。
谓语:路径表达式的附加条件,对节点进行进一步筛选,被嵌在[ ]中,使用谓语时,我们经常会用到一些XPath函数。



应用-修改提取数据字段xpath
适用于调整XPath解决采集数据中出现的漏数据,数据错位等问题。
应用场景:
1.网页上有的信息,采集结果出现部分字段的未采集到。
2.采集结果出现部分字段数据错位,实际采集内容与字段名不对应。
原因分析:
网页结构不一致,导致原本的xpath,在某些页面无法正确定位到所需数据。
解决思路:
修改问题字段的xpath,使其在所有页面都能精准定位到所需数据。
应用-修改循环列表xpath
适用于通过修改循环列表XPath,以解决部分漏数据,出现多余项等问题。
应用场景:
点击生成的循环列表并未包含所需的全部数据,出现部分循环项遗漏。
原因分析:
网页结构特殊,导致原本的xpath未能匹配到页面中所有所需数据。
解决思路:
修改循环列表的xpath,使其能匹配到页面所有所需数据并排除掉多余循环项。