上周为了从网络上搜寻一些数据而接触到了爬虫,由于时间紧迫,不能从头开始学习,就想从网上找一些现成的爬虫工具直接使用,百度搜素得到的结果有这么几种:LoalaSam_Beta、火车头、集搜客、八爪鱼、沙漠之鹰等,第一个是外国的软件,据说爬取国内的数据好像不好用;火车头、集搜客、八爪鱼这几个软件大同小异,都是不用写代码,用可视化的方法完成网页上数据的采集,当然了,要自己制定一些采集规则,也就是设计流程图。由于八爪鱼这个软件官方提供的学习资料和视频课程比较多,而且也有免费版本,所以就用了1天时间学习这个软件的使用并抓取到了一些数据。
遗憾的是,八爪鱼只能直接采集到网页上的文本信息和图片的链接,并不能直接将想要的图片下载下来,如果要将图片下载下来,就需要先用制定好的规则采集到图片的URL,并将这些URL存储到EXCEL中,在EXCEL中进行预处理后,在用八爪鱼提供的某个图片下载工具将URL对应的图片下载下来。然而经过尝试,八爪鱼交流群里下载到的那个图片转换工具貌似并不是他们自己公司开发的,而且我下载图片并不能成功,只是简单的生成了图片的缩略图,但是图片内容一个都没有,根本就没有什么卵用。
后来没办法,觉得这个工具应该也没有多高深,就抱着试试看的态度自己用python写一个吧。要写这样个工具,首先要明确这个工具的目的是什么,下面这张EXCEL表中存放的是要下载的图片名称、图片的URL和图片要保存在本地的路径。如下图:
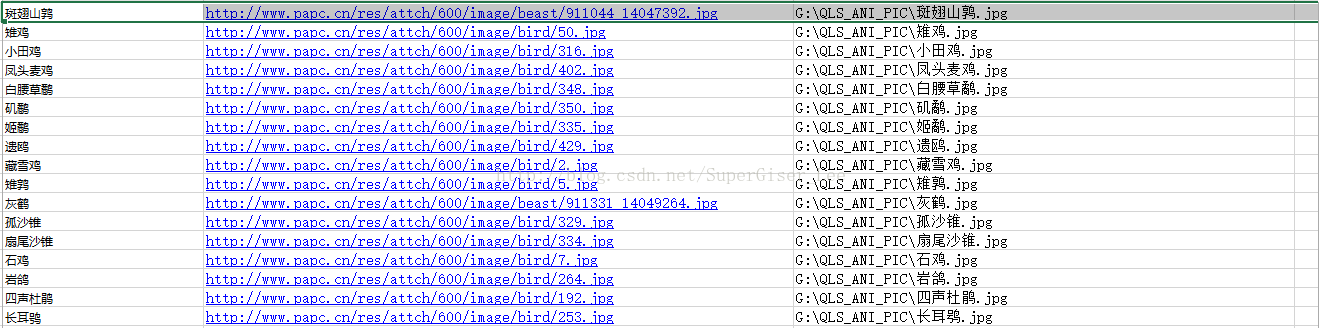
这张表里,前两列分别存放了要下载的图片的名称、图片的URL,这两列数据是用八爪鱼从网页上上爬来的,第三列中的图片保存路径就是自己设定的了,这个如果量比较大的话,当然在EXCEL里用函数是很好完成的了,先在C1单元格里写上图片要存放的那个文件夹的路径,并在末尾加上“\”,然后自动填充,使这列中的文件路径相同;再在D1单元格中写上“.jpg”,写完后也自动填充该列;然后在E1单元中输入公式“=C1&A1&D1”,写完敲回车,就出了要存放的图片的包含名称和后缀的全路径,然后自动填充这列;最后,选中E列并将这列内容复制粘贴到F列中,然后删除掉C、D、E三列并保存该EXCEL表,这样,数据预处理的工作就完成了。下面介绍python写爬虫工具的过程:
想要的工具应该具有这样的功能,它能自动读取上面EXCEL文件中的B列内容并作为URL来访问网络,然后下载到对应的目标文件并保存到C列中对应的路径下生成此目标文件。这其实就涉及到两方面的内容,一个是用python读取EXCEL的操作,另一个就是用python下载文件的操作。我们先解决用python下载文件到本地的操作。
网上百度一下,说是有三种方法可以实现,
第一种:
import urllib
import urllib2
import requests
print "downloading with urllib"
url = "http://www.pythontab.com/test/demo.zip"
print "downloading with urllib"
urllib.urlretrieve(url,"demo.zip")
第二种:
import urllib2
print "donloading with urllib2"
url = "http://www.pythontab.com/test/demo.zip"
f = urllib2.urlope(url)
data = f.read()
with open("demo2.zip","web") as code:
code.write(data)
第三种:
import request
print "downloading with requests"
url = "http://www.pythontab.com/test/demo.zip"
r = requests.get(url)
with open("demo3.zip","wb") as code:
code.write(r.content)
第一种和第三种没试过,直接用的第二种,url就用的B1单元格里的URL,demo2.zip处就是用的C1单元格里的内容替换的,测试一下,制定的路径下果然生成了想要的那张图片,这说明,用Python实现下载图片的内容已经得到解决,下面的问题就是要解决批量下载了,那就得让python去读EXCEL文件,遍历并记录B、C两列的内容。百度一下python读取EXCEL的方法,网上很多,比如这个链接里讲的,很简练:http://www.cnblogs.com/lhj588/archive/2012/01/06/2314181.html,
1、导入模块:import xlrd
2、打开EXCEL文件读取数据:data = xlrd.open_workbook('excelFile.xls')
3、获取一个工作表:(通过名称获取)table= data.sheet_by_name(u'Sheet1')
(通过索引顺序获取)table= data.sheet()[0]
(通过索引顺序获取)table = data.sheet_by_index(0)
4、获取整行和整列的值(数组):table.row_values(i)
table.col_values(i)
5、获取行数和列数:nrows = table.nrows
ncols = table.ncols
6、循环行列表数据:for i in range(nrows):
print table.row_values(i)
7、单元格:cell_A1 = table.cell(0,0).value
cell_C4 = table.cell(2,3).value
8.使用行列索引:cell_A1 = table.row(0)[0].value
cell_A2 = table.col(1)[0].value
这些操作怎么用都要去试,1、2、3步是肯定都要写的,后面的步骤就要选择性使用。现在我们想一行一行的遍历Sheet1中的数据,然后将每行读到的数据按A、B、C分成三部分,将B部分对应的值赋给URL,将C部分中对应的值赋给demo2.zip位置的变量。然后第一行就进行上面讲到的python下载文件操作,第一行下完存储后开始第二行同样的操作,然后是后面的每行,执行同样的操作,直到遍历完成所有的行,程序就结束了,也就下载完成所有的图片并完成存储。思路有了,下面开始实现:
import xlrd
import urllib.request
data = xlrd.open_workbook(r"C:\Users\85196\Desktop\PROT_AIN\AX_AIN.xlsx")
table = data.sheet_by_name(r"Sheet1")
for i in range(table.nrows):
parrentrow = table.row_values(i) #可以print parrentrow用来测试返回的数据结构,发现返回的是一个列表,里面存放了A1、B1、C1单元格里的三个元素
ainmal = parrentrow[0] #取出这行(当前行)第一个元素,取名为ainmal
url = parrentrow[1] #取出当前行第二个元素,取名为url
savepath = parrentrow[2] #取出当前行第三个元素,取名为savepath
f = urllib.request.urlopen(url) #访问并打开B1中的URL
data = f.read() #读到的东西取名叫data
with open(save,path,"wb") as code: #在C1路径下写入data的内容,如果没有这个文件即时创建一个
code.write(data)
上面这段代码测试一下,发现C1路径下那个文件夹下不断自动生成想要的图片,这说明程序写成功了。但是问题是,这样并不知道有多少张片要下载,也不知道下载进度,即当前下载的是第几张、还剩多少张、什么时候下载完成等等,这样程序要是中途卡了或者崩了都没有提示,这个软件就不好用。那就思考添加这些提示。
首先,想知道有多少张图片要下载很容易,因为Sheet1中每一行就对应一张图片,有多少行就有多少张图片,所以只要获取Sheet1的行数就行了,一句话 : print table.nrows.
为了让提示更人性化,这样写:
print "The total number of the picture to download is" + str(table.nrows) #table.nrows是整型,要和前面连接先强转成字符串型
下面就是提示还剩多少张没下载,这个怎么弄呢?想一下,比如我们执行到第一行时候,肯定还剩 (table.nrows - 1)行没执行,就是还剩这么些图片待下载;当我们执行到第8行时,就还剩(table.nrows - 8)多张没下载;那用一个变量表示当前执行到的行数就行了, 我们上面的程序里,i 这个变量,就和行数有关,它就表示Sheet1中的每一行,但是 i 得起始值是0,就是当下载第一张是,i = 0; 当下载第二张时,i = 1; 可知 i = 行数 - 1,所以直接用 (table.nrows - i )得到的值就比 (table.nrows - 当前行数)的到的值少减了一个,那要用i表示正确的剩余行数, 只需 再多减一个数,即用 (table.nrows - i - 1)来表示就行了。我们让程序执行到每次打开URL的时候提示出剩余图片的数目就行了。一句话:
print “The parent picture beeing download is ” + animal + " , and " + str(table.nrows - i -1 ) + "pictures are rest!" #提示当前下载的是那张图片,还剩多少张没下载
再试一下,果然好使多了,但是还有一个问题,程序每次下载到一半不能进行了,重启以后前面已经得到的图片还要被重新下载而覆盖,重新下载和替换的过程也是要花费时间的,那就有可能100张图片永远也下载不晚。我们想实现这样的功能,每次程序重启之后,自动识别一下目标路径下是否已经存在同名的目标文件,是的话就忽略掉重新下载它们的步骤,提示这张图片已经存在,还剩多少张没下载并直接从它们后面开始执行,并提示当前下载的图片名称和下载进度。要实现这样的效果,我们肯定要做一个 if / else 的判断,判断的条件就是目标路径下是否存在目标文件,这可以用系统库里面的exists 函数来实现:os.path.exists(savepath), 这个函数返回的值是True 或 Flase , 如果返回True ,那就让它忽略掉上面的下载步骤,直接提示那些文件已存在; 如果返回Flase ,再让它开始下载过程,并提示下载文件名称和进度,这样就实现了这个功能。下面上完整的代码,python 版本是3.5, 对中文注释支持不好,注释都用英文。代码如下:
测试一下,很好用,见如下效果:

右边交互窗口会提示下载进度,要是程序卡住,半天不响应,就重启程序,让它从后面开始下载,也可以多重启几次直到全部下载完成。