我们上篇文章了解了一下NIN ,接下来我们来了解一下VGGNet,可以说是另一波的跪舔和膜拜。VGGNet主要是分为两篇文章,第一篇文章来分享一下VGGNet的网络结构还有训练环节,第二篇文章是分享VGGNet做的分类实验和总结。此为第一篇。
文章目录
1. VGGNet之旅
1.1 作者介绍

1.2 对VGGNet的跪拜_(:3 J Z)_
作者对六个网络的实验结果在深度对模型影响方面,进行了感性分析(越深越好),实验结果是16和19层的VGGNet(VGG代表了牛津大学的Oxford Visual Geometry Group,该小组隶属于1985年成立的Robotics Research Group,该Group研究范围包括了机器学习到移动机器人)分类和localization的效果好(作者斩获2014年分类第二,localization第一,分类第一是当年的GoogLeNet.)下面是来自一段(摘自知乎)对同年的GoogLeNet和VGG的描述:
GoogLeNet和VGG的Classification模型从原理上并没有与传统的CNN模型有太大不同。大家所用的Pipeline也都是:训练时候:各种数据Augmentation(剪裁,不同大小,调亮度,饱和度,对比度,偏色),剪裁送入CNN模型,Softmax,Backprop。测试时候:尽量把测试数据又各种Augmenting(剪裁,不同大小),把测试数据各种Augmenting后在训练的不同模型上的结果再继续Averaging出最后的结果.
1.3 前情提要

1.4 作者干了啥:
- 卷积核变小,只有更小没有最小 (ZFNet+OverFeat+NIN);多尺度==(Overfeat)==
- 层数更深,卷积层更宽
- 池化核变小且为偶数,减小信息损失
- 测试阶段将三个全连接替换为卷积:思想来自OverFeat,1×1的卷积思想则来自NIN,优点在于全卷积网络可以接收任意尺度的输入(这个任意也是有前提的,长和宽都要满足:(2**n),n是卷积与池化做stride=2的下采样的次数)
- 打了很多比赛,头够铁
2. VGGNet网络结构
2.1网络结构简述
- 输入: 在训练的过程中,输入我们卷积层(们)的图像是固定的尺寸224X224的RGB图像。
- 预处理: 唯一的对于训练集的预处理是整张图片的每个像素减去RGB的平均值。
- 卷积层:
输入图像通过一堆的卷积层,卷积层中使用的卷积核是3X3的(最小的用来捕获左右、上下特征的卷积核,如果是1X1就没有方向的概念)。 - 池化层:
池化是由五个最大池化层执行的
最大池化层的核是2X2的,步长为2. - 全连接层:
照例跟在一堆卷积层后面,前两个全连接层每个都有4096个通道,第三层包含1000个通道,每个通道对应一个类别,最终层同样是softmax层。还同时借鉴了AlexNet训练时去除最后一层,对比语义特征的L2的方法进行训练。在测试时被换成卷积了,这样使得计算结果更准确! 全连接网络的配置都是相同的。 - ReLU层:
每个隐藏层都跟有ReLU层。 - LRN层:
没有用 ,这种正则化对模型在ILSVRC数据集上没有任何改善(作者真严谨 = =),但是占用了大量的内存,浪费时间。如果你觉得应该使用就去用AlexNet的参数自己玩自己,但是AlexNet是真的很厉害啊(解读作者原话)。
2.2 配置
所有的配置遵循前人配置,只在深度上稍有所不同:从A网络中的8层卷积+3个全连接到E网络的16卷积层+3全连接层。卷积层的宽度相对较小从第一层的64,每次经过最大池化层后涨至2倍,直奔512去。

除了网络很深,VGG网络的权重数不会比更浅层的、具有更大卷积层和卷积核的网络的权重数。(这里作者提及OverFeat的权重为144M)(白话:VGGNet的每层的权重数都刚刚好,多了少了都不合适,也不多占内存)
2.3 讨论
- 小卷积核的好处
作者首先对比了第一卷积层使用大卷积核(感受野大)的网络:AlexNet用11X11,步长4;ZFNet和OverFeat使用7X7,步长2;VGGNet使用3X3,步长为1.
在没有最大池化层和ReLU层的情况下,两个3X3的卷积核组成的卷积层组合起来相当于一个5X5的卷积核的卷积层;三个3X3的卷积核组成的卷积层组合起来相当与一个7X7 的卷积核的卷积层。
所以使用一堆3X3的卷积核相对比直接用7X7的卷积核的好处在哪啊?
在——
1.融合三个非线性ReLU而不是只有一个可以让决策函数更有区分性。(不断取正,不断分开重要特征与背景信息);
2.缩减参数量:上文提到三个3X3卷积核的卷积层相当于一个7X7的卷积层,假设输入输出的通道数都是C,第一种卷积层的组合有3X(32)X(C2)=27C2个参数;第二中卷积层组合有(72)X(C2)=49C2个参数,多了81%。(觉得作者贼聪明!)
这可以看做是7X7卷积核进行正则化并且降维到3X3卷积核(两个卷积核间还有ReLU)。(将高维向量特征用三个低维向量特征表示)
1X1卷积的融合在没有影响卷积层卷积核的情况下,增加了决策函数的非线性。为啥呢?这个卷积后跟了ReLU层,增大了非线性的效果。(觉得作者是天才!)
总结整个网络的工作:先将local信息压缩,并分摊到channel层级,然后无视channel和local,通过fc这个变换再进一步压缩为稠密的feature map
3.训练和测试(分类任务)
3.1训练
训练的大体过程通过小批量图像的(带动量的)梯度下降进行优化多项式的逻辑回归目标函数进行的。
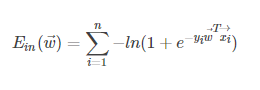
- 参数设置
1.批量尺寸(batch size)设为256,动量设为0.9。
2.训练的正则项有两个:1.权重衰减:惩罚乘子:0.0005;2.丢失率:dropout = 0.5(只在前两个全连接层存在)
3.学习率初始化为0.01,并且在验证集的准确率不再上升时每次除以10。总的来说,学习率会衰减3次,在370,000,000后(训练74轮epoch)停止学习。
推断:对比AlexNet,VGGNet具有更多参数和更深的结构,造成更快收敛(Alex的训练次数:训练了90轮)的原因如下:1.(更深的网络和更小的卷积核)所施加在权重上的明确的正则化项(dropout和小卷积核的使用);2.某些层的预初始化
- 预初始化
初始化很重要啊!不好的初始化可以引起深层网络的梯度不稳定,从而延缓学习(好有道理啊! 比如权重是0,0,0,0,0,0,0,0,0,0.1,梯度时有时没有的),为了规避这个问题(新学了一个词呢:规避——circumvent),首先从A网络开始配置,A网络很浅,比较适合随机初始化。当训练更深的结构时,就用网络A可以初始化前4个卷积层和后3个全连接层(中间层随机初始化)。在预训练层中不进行学习率的衰减,但是允许学习率变化。对于中间层的随机初始化,权重的数值是在均值为0,方差为0.01的分布中采样获得。偏置初始化为0.。

在交完论文之后,作者发现可能可以不用预训练而通过Understanding的随机初始化过程进行初始化权重。(但是似乎并没有用上)。为了获得固定的224X224的卷积层输入图像,随机从重新调整的训练图像中剪裁(一次SGD迭代,每张图像裁剪一次)。为了进一步增加训练集,剪裁前经历水平翻转,随机RGB颜色偏移(借鉴AlexNet)。训练图像重新调整在下面提及。
训练图像的尺寸: 就是S是最小的训练图像的最小边尺寸 (这里有一个词isotropically-rescaled->这意味着沿宽度和高度应用相同的缩放系数,因此图像不会沿一个轴变形,所以S取最小边), 剪裁最终得到的尺寸是224X224,而S>=224.大于的时候取图像中的一部分,等于的时候取整张图像。
两种设定训练尺寸S的方法:
第一种是固定S,对应于单尺寸的训练 (这里有一句很贝叶斯感觉的话:采样剪裁的图像内容可以表示多尺度图像的统计信息,怎么样,是不是很贝叶斯)。 VGGNet文章的实验中使用两种固定尺寸:256,384(256 在Alex,ZF,OverFeat中用到了).对于卷积网络的初始化配置,首先使用S=256进行训练。为了加速S=384的网络,将网络的权重初始化为S=256预训练的权重,并使用更小的初始化学习率0.001.
第二种是多尺度训练来设定S,每个训练图像的尺度是从[Smin,Smax]中采样一个特定值(VGGNet中Smin=256,Smax=512)。由于目标在图像中是不同尺寸的,所以这么做有利于训练。这也可以被视为通过尺度抖动的训练集增强。(这句话我觉得很有道理!)为了加速,我们通过使用相同配置微调单级模型的所有层,来训练多尺度模型,所以使用固定的S = 384进行预训练。

3.2测试
在测试时,首先,将图像各向同性重新调整为预设最小图像边Q(测试尺度)的大小,Q不必和S相等(在第四部分会看到,对于每个S(训练尺度)多使用几个不同的Q(测试尺度)有利于性能的改善)。 对于重新调整的图像,使用卷积网络的方法和OverFeat一样,即,全连接网络首先转换为卷积层 (第一个全连接转换为7X7的卷积层,后两个全连接网络转换为1X1的卷积网络)。

全卷积网络的输入可以是整张图片 (未被切割过的)。(作者在测试阶段把网络中原本的三个全连接层依次变为 1 个conv7x7,2 个 conv1x1,也就是三个卷积层。改变之后,整个网络由于没有了全连接层,网络中间的feature map不会固定,所以网络对任意大小的输入都可以处理)

结果是一个类别分数图像,这个图像的通道数等于需要分类的类别的数量(由于输入图像的尺寸,还有变化的空间分辨率)。最终为了获得相对于图像类别的固定尺寸向量,类分数图要通过空间平均(池化和),(假设输入的图是384x384x3,得到最终输出为 6x6x1000 的 feature map,进行空间平均,取池化和,得到1x1x1000,再进行softmax)。VGGNet同样通过水平翻转来增强图像测试集,将原始图像和翻转图像的类分数图进行soft-max得到类后验平均化以获得图像的最终分数(正图和反图都是这个类,那就是这个类)。
由于全卷积网络被运用于整张图片,这就不必在测试时进行采集多个切割图像(这种行为是什么呢,低效且浪费计算资源)。同时,使用大量的切割图可以改善准确率,因为与完全卷积网相比,它可以对输入图像进行更精细的采样。此外,由于不同的卷积边界条件,多切割图评估是对密集评估的补充(作者就是夸夸crops的好处吧):
当将一个卷积网络运用到切割图上,卷积特征图被零填充,而在密集估计的情况下,同一切割图的填充自然来自图像的相邻部分(由于卷积和空间池化的需要),这大大增加了整个网络接收领域,因此捕获了更多的上下文信息。(我觉得就是通过切割的填充和卷积、池化、再填充、卷积、池化,这个过程中相当于增大了感受野,捕获了更多的信息)。
虽然作者认为实际上多种crop的计算时间增加并不能证明准确性的潜在增益,(这话有点前后矛盾)但作为参考,作者还使用每个规模50个crop(5×5个网格,2个翻转)评估网络,总共150个 3种尺度的切割图,与Googlenet使用的4种尺度的144种切割图相当。这是下周的googlenet。
3.3执行细节
VGGNet的执行是在开源的改进版的C++Caffe工具上进行的,是在装在同一个系统上的4个GPU上执行的,在训练过程中进行了剪切和未剪切的图像的训练和评估。多GPU训练利用数据并行性,并通过将每批训练图像分成几个GPU批次来执行,并在每个GPU上并行处理。在GPU的批量梯度被计算出来后,进行平均(我认为是各个GPU的结果都拿出来进行平均得到一个梯度,相当于一个GPU计算结果,但是比一个GPU快3.75倍)获得整个批次的梯度。梯度计算在GPU之间是同步的,因此结果与在单个GPU上进行训练时的结果完全相同。
VGGNet概念上更简明的策略使用现有的4GPU系统相对于单GPU已经加速了3.75倍。在配备四个NVIDIA Titan Black GPU的系统上,根据架构的不同,培训一个网络需要2-3周(此时可以想象作者开心得手舞足蹈的样子~)
最后的最后,因为我们还是机器学习刚入门的小学生,有些理解不到位的地方还请大大们指出。博客最近两个月会每周都至少更新一篇深度学习网络篇的理解(下一篇是VGGNet的第二篇哦~),还请大家多多支持!蟹蟹!!!