上篇文章中我们介绍了ZFNet的发展历程和一些算法小心机,在这篇文章中我们将分享一下ZFNet的训练细节!Come on!!!Baby!!!
一、ZFNet训练细节
【AlexNet和ZFNet的区别】
1.AlexNet中使用2个GPU运的稀疏连接;在ZFNet中被单GPU密集连接替换;
2.将AlexNet第一层卷积核由11变成7,步长由4变为2(预告一波);
【ZFNet的训练】
------(预处理)该模型在ImageNet 2012培训集上进行了培训(130万张图像,分布在1000多个不同的类别)。
------每个RGB图像都经过预处理,方法是将最小尺寸调整为256,裁剪图片中间的256x256区域,然后减去整张图像每个像素的颜色均值,然后用10个不同224x224窗口对原图像进行裁剪(中间区域加上四个角落,及水平翻转图像)。
------进行随机梯度下降法,对128个图片组成的块来更新参数。
------起始学习率为0.01,动量系数为0.9。当验证集误差趋近于收敛时,手动调整学习率。
------在全连接网络中使用系数为0.5的dropout(Hinton等,2012),且所有权值都初始化为0.01,偏置设为0。
------高训练集的大小。
------我们在70个迭代之后停止了训练,在单个GTX580 GPU上花了大约12天,基于(Krizhevsky等,2012)的实现。
【网络遇到的小问题】
训练期间第一层卷积核的可视化显示,其中一些核数值过大,导致一些因素占主导位置。解决办法:为了解决这个问题,我们将RMS均方根值超过固定半径0.01的卷积核重新归一化,使其均方根到为0.1。这步骤是至关重要的,特别是在模型的第一层,输入图像大致在[-128,128]范围内。

二、卷积网络可视化
使用刚刚讲的模型,使用反卷积网络,可视化ImageNet验证集上的特征激活,展示反向生成的刺激。
1.特征可视化
1)展示了训练结束后,我们模型的特征可视化,将模型各个隐含层提取了特征。
------显示前9个最强的激活。
2)将这些计算所得的特征,投影在像素空间显示时,可以清晰的看到:输入存在一定畸变时,网络的输出结果保持不变,即:其对输入内容具备变形的不变性。
3)显示的图patch。 仅关注每个patch内的判别结构(和重构特征相比,输入图像间差异很大,而重构特征只包含那些具有判别能力的纹理结构)。
例如,在第5层第1行第2列的九张输入图片中,各不相同,差异很大,而对应的重构输入特征似乎没有什么共同之处,但可视化显示此特定要素图聚焦于背景中的草,而不是前景对象。
【每层的投影(可视化结果),显示了网络的层次化特点】
1)第2层展示了物体的边缘和其他轮廓,以及与颜色的组合。
2)第3层具有更复杂的不变性,主要展示相似的纹理(例如网格图案(R1,C1);(R2,C4))。
3)第4层显示出显著的变化,更具有类别特征,开始展现类与类之间的差异:狗的脸(R1,C1);鸟的腿(R4,C2)。
4)第5层显示具有显著差异的一类物体,还可以对物体进行定位,例如,键盘(R1,C11)和狗(R4)

可视化训练好的模型中的特征!
对于2-5层反卷积计算后,我们在验证数据集的特征映射的随机子集中显示前9个激活,使用我们的反卷积网络方法向下投影到像素空间。
我们的重建不是通过对模型采样得到的,他们是固定由特定的输出特征反卷积计算产生的:它们是来自验证集的重建模式,其在给定特征图中引起高激活。
对于每个特征映射,我们还会显示相应的图像patch。
注意:
(i)每个特征图内的强关联性
(ii)层次越高,不变性越强
(iii)原始输入图像的强辨识度部分的夸大展现,例如,狗的眼睛、鼻子(第4层,第1行,第1列)。
2.训练时的特征演变
1)在训练过程中,由输出特征的反向卷积,所获得的最强重构特征的演化。
2)当输入图片中最强的刺激源发生变化时,对应的输出特征的轮廓发生跳变。
3)可以看到:模型的较低层,在一定次数的迭代就收敛。
4)然而,上层仅在相当多的迭代后(约40-50周期)才可以收敛,证明需要让模型训练到所有的层完全收敛。

【上图解读】通过训练模型特征的随机选择的子集的演变。每个图层的特征都显示:在不同的块中(模型特征逐层演化过程)。在每个区块内,我们在迭代[1,2,5,10,20,30,40,64]次时,显示随机选择的特征子集。可视化显示给定特征图的最强激活(在所有训练示例中),使用我们的反卷积网络的方法向下投影到像素空间。色彩对比是人为增强的。
3.特征不变性
1)展出了5个样本图像被平移,旋转和缩放,同时查看来自模型的顶层和底层的特征向量相对于未变换特征的变化。
------在模型的第一层中,小的变化具有显着效果;
------但在顶部特征层中,具有较小的影响
2)对于平移和缩放是准线性的,网络输出对平移和缩放是稳定的。
3)除了具有旋转对称性的物体之外,卷积网络无法对旋转操作产生不变性。
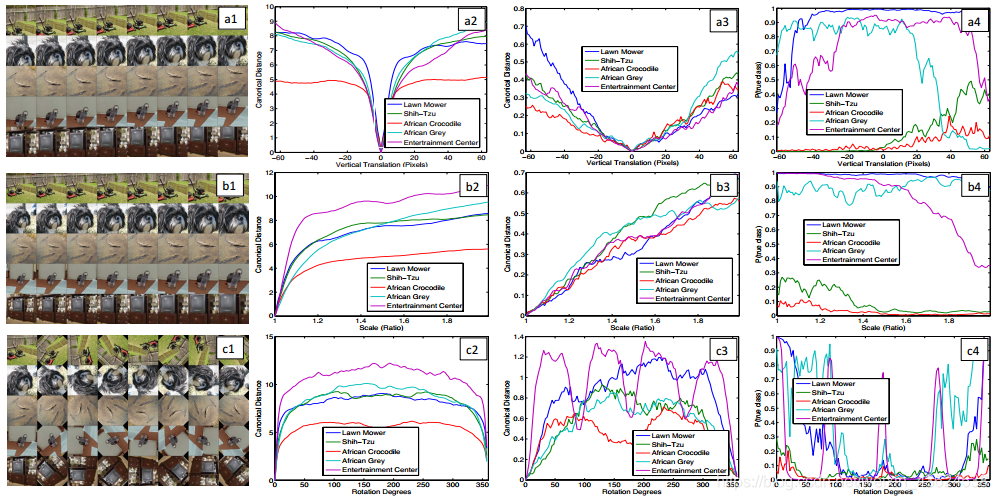
【上图解读】
行:1)垂直平移(a),旋转(b)和尺度变化(c)2)用于在卷积网络模型中,相应的特征不变性。
列:1)列 1:5个经历各种转换的原始图像。2)第2和第3列:分别来自第1层&第7层中的原始图像和变换图像的特征向量之间的欧几里德距离。3)第4列:当图像被转换时,真实类别在输出中的概率。
4.Architecture Selection结构选取
1.训练模型的可视化
------深入了解内部操作
------帮助我们选择更好的架构
2.可视化Krizhevsky等人的第一层和第二层的架构,问题很明显。
------第一层卷积核后,是高频信息和低频信息的混合,几乎没有中频信息。
------第二层可视化显示由第一层卷积中使用的4为步长,引起的混叠伪像,产生了混乱无用的特征。
3.为了解决这些问题,我们(刚刚预告的)
------将第一层卷积核尺寸从11x11减小到7x7
------步幅减小为2而不是4。
4.这种新架构在第1层和第2层功能中保留了更多信息, 还提高了分类性能。

【上图解读】a) 第一层输出的特征,没有经过尺度的约束操作。 可以看到一个特征,会占主导地位。
b) (Krizhevsky等,2012)第一层特征
c) 我们ZFNet第一层的特征。 较小的步幅(2 VS 4)和卷积核尺寸(77对1111)导致更具辨识度的特征和更少的无用特征。
d) (Krizhevsky等,2012)第二层特征的可视化
e) 我们ZFNet的第二层特征的可视化。这些更清晰,没有(d)中可见的模糊特征。
------b,d Krizhevsky等人的第一层和第二层的架构各种问题都很明显。
------c,e 新架构在第1层和第2层功能中保留了更多信息,它还提高了分类性能
【因而得到我们的ZFNet!】
三、ZFNet网络
1.ZFNet的网络结构
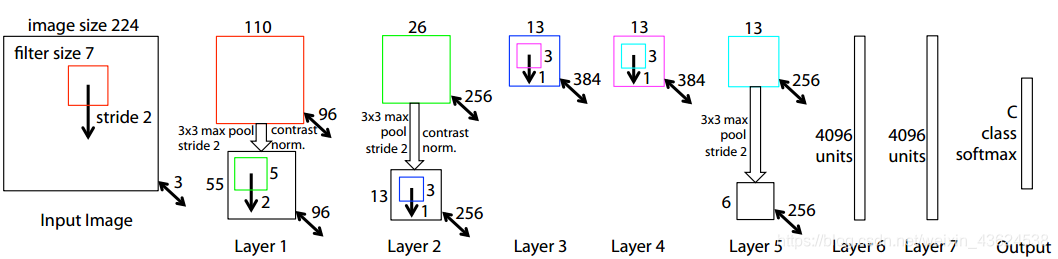
1.8层卷积网络模型的架构
2.ZFNet=(conv+relu+maxpooling)×2+(conv+relu)×3+fc×2+softmax
3.224×224个图像(具有3个通道的GRB图像)作为输入
4.与AlexNet相比,网络结构没什么改进,
1)第一层
------卷积核由11变成7,步长由4变为2
------通过矫正函数,使所有的卷积值均不小于(图中未示出),
------最大池化(33的区域内,步幅为2)
------在特征图之间归一化的对比度,得到96个不同的5555个元素特征映射
2)层2,3,4,5中重复类似的操作。
------第3,4,5卷积层转变为384,384,256512,1024,512。
3)在最后两层使用全连接,将上步卷积层的特征作为矢量形式的输入(第五层的输出为:66256 = 9216维)。
4)最后一层是C类softmax函数,C是类的数量。
2.Occlusion Sensitivity 遮挡敏感性
1)图像分类时,一个自然的问题是:模型如何做到的分类?
------真实地识别图像中对象的位置,
------或者仅仅使用对象周围的上下文
2)通过用灰色方块,系统地遮挡输入图像的不同部分,并测试在不同的遮挡情况下,分类器的输出结果。
表明:
模型正在定位场景中的对象,因为当对象被遮挡时,正确类的概率(分类器的性能)会显着下降。
3)展示出了最上层卷积层的最强响应特征,展示了遮挡位置和响应强度之间的关系。当遮挡物覆盖关键物体出现的区域时,我们会看到响应在强度急剧下降。
表明:
------可视化真实地对应于刺激该特征图的图像结构,因此验证了图4和图2中所示的其他可视化。
------真实反映了输入什么样的刺激,会促使系统产生某个特定的输出特征,
------用这种方法可以一一查找出图2和图4中特定特征的最佳刺激。
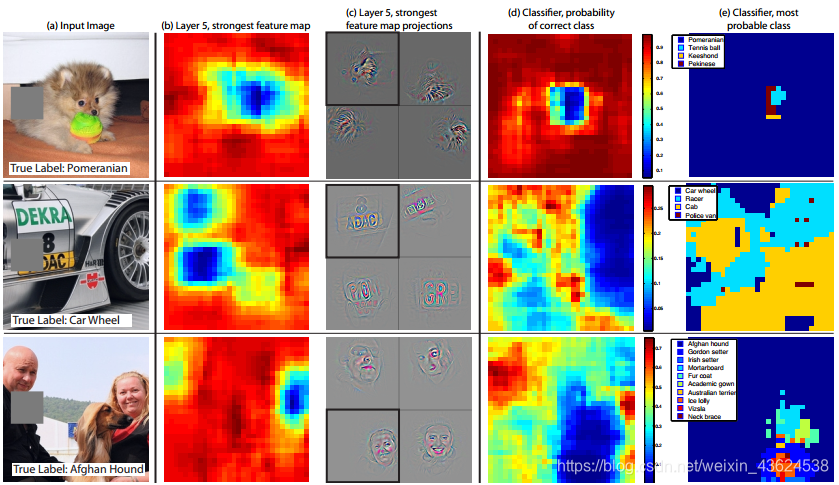
【上图解读】
1)图7:对三个不同的测试图片的不同位置用灰色小方块进行掩盖后(参见第1列),观测分类输出的改变情况【第5层的输出强度产生影响(b)和(c)和分类结果输出(d)和(e)的变化】。
2)(b):某个区域被灰色小方块掩盖后的网络结构中,第五层的特征图
3)(c)将第五层的特征图,投影到像素空间的情境(带黑框的),第一行展示了狗狗图片产生的最强特征。当存在遮挡时,对应输入图片对特征产生的刺激强度降低(蓝色区域表示降低)
4)(d)正确分类对应的概率,是关于遮挡位置的函数,当小狗面部发生遮挡时,小狗分类作为输出的概率急剧降低
5)(e)最有可能的类的标签。也是一个关于遮挡位置的函数。
例如:第一行表明最强烈的特征表现在狗狗的面部区域,只要遮挡区域不在狗狗面部,输出都是波希米亚小狗,当遮挡区域发生在狗狗面部,但又没有遮挡网球时,输出结果是网球。在第二行中,车上的文字是第五层卷积网络的最强输出特征,但也很容易被误判为车辆。第三行包含了多个物体,第五层卷积网络对应的最强输出特征是人脸,但分类器对于“狗”十分敏感(d中的蓝色区域)原因是softmax分类器使用了多组特征(既有人的特征,也有狗的特征)
3.Correspondence Analysis图片相关性分析
1.没有一套明确的定位机制(例如,如何解释人脸眼睛和鼻子在空间位置上的关系)。
2.可能:深度网络模型隐式(非显式)计算它们。
3.为了探索,本文随机选择了5个狗狗正面姿势的图像,并且系统地掩盖每个图像中的狗狗的脸部的相同部分(例如,所有左眼,参见图8)。
4.对于每个图像i,我们计算 : 分别表示原始图像和被遮挡图像的第l层的特征向量。然后,我们测量所有相关图像对(i; j)的误差向量ε的一致性: ,其中H是汉明距离。 较低的值表示由遮挡操作引起的变化的更大一致性,因此不同图像中的相同对象部分之间的更紧密的对应(即,阻挡左眼以一致的方式改变特征表示)。
5.在表1中,我们使用来自第5、7层的重构特征来比较面部(左眼,右眼和鼻子)的三个部分与对象的随机部分的Δ得分。
6.这些部分的得分相对于随机对象区域较低,说明眼睛图片和鼻子图片内部存在相关性。
7.对于第5层,鼻子和眼睛的得分差异明显,说明第5层卷积网络对于部件(鼻子,眼睛等)各个部分的相关性更为关注。
8.第七层各个部分的得分差异不大,说明第七层卷积网络开始关注更高层的信息。(狗狗的品种等)

【上图解读】用于对应实验的图像。 第1列:原始图像。 列2,3,4:分别遮挡右眼,左眼和鼻子。 其他列显示随机遮挡的示例。
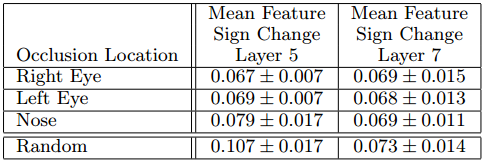
【上图解读】
1.5种不同狗图像中,不同对象部分的相关性测量。
2.第5层中,眼睛和鼻子的较低分数(与随机对象部分相比)
------表明网络已经开始产生了相关性。
3.在第7层,分数相差不大,
------可能是由于高层网络试图区分不同品种的狗,而不是局部特征。
下一篇文章将会给大家介绍ZFNet中的最后的实验细节,还请大家多多关注!我们还是深度学习刚入门的小学生,有些理解不到位的地方还请大大们指出。蟹蟹大家~