台风来临前的夜晚,有点激动不想睡觉,看了几个电影,日本恐怖片,台风雨夜,非常不错,P2P很流畅,观察IP地址大量也是附近的,江浙沪,难道也都在迎台风看电影?
大家都知道使用P2P模式下载速度会非常快,原理其实也并不难,毕竟P2P没有中心瓶颈,每个节点既是下载方又是上传方,一起接力努力的模型总比C/S模式对中心带宽的争抢要好吧,但是这背后有没有什么理论根据呢?本文就是描述这个理论根据的,我不会大段的贴数学公式,但是会贴一些,不算难,都懂的。在理解了这个基本原理之后,你也就可以回答第二个问题了,为什么P2P下载伤害硬盘。
声明:本文只是一篇普通的科普,真正的P2P涉及的算法要复杂的多,本文不属于这个范畴,较真儿者请慎重。
真的有必要每一个数据包发送N次吗?如果建立客户端之间的关联,会怎样?联通带来收益,这就是P2P网络要做的事,我们看一下P2P是怎样带来时间收益的。
既然所有的成员都在向我发送文件,那么我真的需要那么多吗?答案是,所有的成员为我发送文件的不同部分,这样对于我而言,我只需要在本地将这些文件片断组合起来,它就是一个完整的文件了!一个大文件不再作为一个整体在网络上重复发送给所有的需要下载者,而是分成小的片段,在所有成员之间自由平等地进行增量交换,这有点像OSPF协议,大意是”你只给我发我需要的即可,我会给你你需要的,我保证我发给你的片段你没有!“
理解了以上的流程,我们就可以把P2P下载分为两个过程了:
如果你仔细计算,会发现整个时间为:
然而未竟全功!
我们已经看到了分割文件的好处,但是上述方案中,只是分了两步。第一步,N0将各个文件片断发给N1到Nn,第二步就没有N0什么事了,全部是N1到Nn这N个节点在交换文件,虽然这达到了好的效果,但是粒度太粗,没有看到全部N+1个节点分分钟都在忙碌着”人人为我,我为人人“。于是干脆进行片断再细分,这么做的依据在于拿宽度换长度,我们把忙碌的节点数量看作是宽度,时间自然就是长度了。如下图所示:
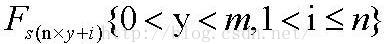 片断给节点Ni,这个Tx等于:
片断给节点Ni,这个Tx等于:
 ,N0发生的事情是:
,N0发生的事情是:
再接下去的 T2,N0上发生的情况是:
于是,我们可以得到一个总的时间:
不但整个文件分了N段,而且每一个片段中又细分了m个子段,这样虽然第一个Tx时间是N0在唱独角戏,最后一个Tx时间是N1到Nn在合唱,但是这确实是一个无极变速,如果Tx特别小,这两次Tx的时间在总的时间阶段中就可以忽略不计了,形成一个全P2P网络相互交换自己没有的部分的局面,如果想让Tx足够小,很简单,片断足够小即可。
从最初的一次性下载到分两步交换,变成了如今的m+1步,这就是不断细分文件的效果。好了,现在已经度过了初始构建阶段,现在所有的N+1个节点上都有了完整的文件F,在描述稳定阶段前,先来考虑一个问题,那就是片断的交换是不是也可以这样做呢?
片断交换的递归
P2P网络传输的一个效果就是消除数据重复传输,即消除了冗余。然而你会发现,上面描述的片断交换过程中,文件片断在N1到Nn之间的交换都是冗余传输的,比如N1要把它所拥有的片断发给其它所有的节点,所用时间为Tx。为了消除这个冗余,也可以递归按照文件F从N0传输到N1至Nn的过程一样。此时传输的已经不是一个文件了,而是一个文件片断。按照刚才的论述,它所用的时间相对于Tx具有N-1倍的加速比(因为无需传输给N0)。如果说这么连文件片断也继续细分子片断,子子片断,最终的终点就是bit了,虽然这种情况的发生是极不明智的(这是不是就是BT中Bit的成因??)。
现在节点总数为N+2,文件可以分为N+1份片断,由N0到Nn分别传输给Nn+1。当然,真正的P2P传输是很复杂的,涉及到P2P地图的构建,你要知道整个P2P网络的信息,比如有多少节点,你要从哪个节点获取文件的哪个部分等等,还要处理节点退出以及新节点加入等动态问题。后面的世界很精彩,但已经超出了本文以及本人的能力范围。
最终的结论是,下载文件的恒定加速比为N,N为除了自己之外的节点数量。理解它很简单,原来是1个节点给你传文件,时间是S/W,现在N个节点一起给你传文件,每一个传输1/N大小,时间当然是原来的1/N了。
正确的做法是,如果内存够大,就先创建一个内存盘,专门进行P2P下载,然后完毕后统一写到真实的硬盘。
大家都知道使用P2P模式下载速度会非常快,原理其实也并不难,毕竟P2P没有中心瓶颈,每个节点既是下载方又是上传方,一起接力努力的模型总比C/S模式对中心带宽的争抢要好吧,但是这背后有没有什么理论根据呢?本文就是描述这个理论根据的,我不会大段的贴数学公式,但是会贴一些,不算难,都懂的。在理解了这个基本原理之后,你也就可以回答第二个问题了,为什么P2P下载伤害硬盘。
声明:本文只是一篇普通的科普,真正的P2P涉及的算法要复杂的多,本文不属于这个范畴,较真儿者请慎重。
1.C/S模式下载
由于大家都要从同一个中心服务器去下载同一个文件,彼此之间没有关联,因此这些下载客户端会共享中心服务器的总出口带宽,假设有N个客户端下载,即便服务器的总带宽达到客户端带宽的N倍,充其量也只是跑满速而已,更何况,这是不可能的,目前骨干上的带宽OC-768算是还好了,40Gbps看看能撑住多少客户端下载高情电影。1.1.统计复用的分组交换网的公平带宽争抢
争抢是不可避免的结局。好消息是互联网的带宽争抢模型非常公平,它是以统计复用的排队论为理论基础的,总的来讲就是将文件分割成一个个的小数据包,然后分别发送,这些数据包片断在路上见缝插针,加塞,变道,有的还会迷路,坠崖什么的,十分悲惨。1.2.C/S模式下载的冗余数据
我们看看服务器出口那里都有什么数据包被发出去了,比如一个文件分割成了m个IP数据报文,记为M1,M2,M3...Mm,一共有N个客户端下载,那么服务器需要发送M1数据包N次,M2数据包N次,M3数据包N次...每一个数据包都要发N次,客户端下载一个大小为K的文件,需要的时间为K/MinBand,MinBand基本就是客户端的带宽了。真的有必要每一个数据包发送N次吗?如果建立客户端之间的关联,会怎样?联通带来收益,这就是P2P网络要做的事,我们看一下P2P是怎样带来时间收益的。
2.P2P网络
典型的P2P网络是一个全互联的网络,意思是每一对节点间都有一个双向连接,但是实际上,这个连接是逻辑上的,并非物理连接,在当前的互联网上,它指的是TCP/IP的网络连通性,而不是指实际存在全互联的网线,那样的话,世界真的成了19世纪末电话线那样的蜘蛛网了。P2P的逻辑拓扑如下图所示: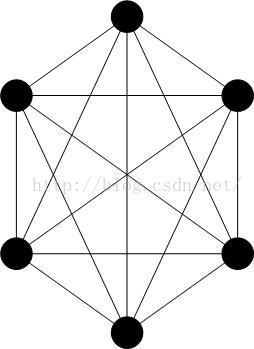
3.P2P下载模型
P2P网络既然是全部互联的,那么你就会有以下的期望,那就是所有的节点都在向我发送数据,而不仅仅是C/S模式下的单一下载源,然而这么做有个前提,你既然这么要求,那别人也会这么要求,你只是P2P网络中的与众人平等的普通一员,这是一种典型的我喜欢的”人人为我,我为人人的“基督教会模式。既然所有的成员都在向我发送文件,那么我真的需要那么多吗?答案是,所有的成员为我发送文件的不同部分,这样对于我而言,我只需要在本地将这些文件片断组合起来,它就是一个完整的文件了!一个大文件不再作为一个整体在网络上重复发送给所有的需要下载者,而是分成小的片段,在所有成员之间自由平等地进行增量交换,这有点像OSPF协议,大意是”你只给我发我需要的即可,我会给你你需要的,我保证我发给你的片段你没有!“
理解了以上的流程,我们就可以把P2P下载分为两个过程了:
3.1.初始构建阶段
太初,所有的成员之间只有一个成员拥有该文件,其它的成员都没有,怎么让所有成员都拥有该文件呢?把拥有该文件的成员作为服务器,大家从它那里下载当然是一种最直接的方式,但是却不是P2P的方式,P2P会在这个阶段就将文件切分成小段,为了讨论方便,我假设P2P网络中拥有N+1个节点,从N0开始编号,最大的节点是Nn,其中N0节点在最初的时候拥有文件F,其大小为S,网络情况为理想情况,无拥塞,任意两节点之间的带宽相等且为W。我们开始切分F,最简单的方式,切成N段,如下图所示:
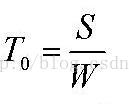

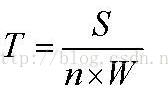
如果你仔细计算,会发现整个时间为:
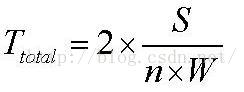
然而未竟全功!
我们已经看到了分割文件的好处,但是上述方案中,只是分了两步。第一步,N0将各个文件片断发给N1到Nn,第二步就没有N0什么事了,全部是N1到Nn这N个节点在交换文件,虽然这达到了好的效果,但是粒度太粗,没有看到全部N+1个节点分分钟都在忙碌着”人人为我,我为人人“。于是干脆进行片断再细分,这么做的依据在于拿宽度换长度,我们把忙碌的节点数量看作是宽度,时间自然就是长度了。如下图所示:
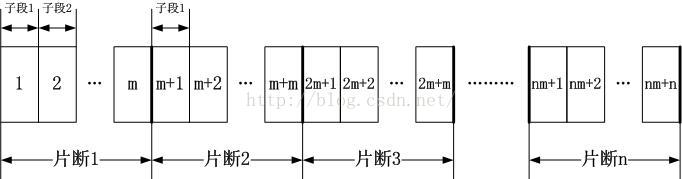 片断给节点Ni,这个Tx等于:
片断给节点Ni,这个Tx等于:
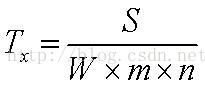 ,N0发生的事情是:
,N0发生的事情是:

再接下去的 T2,N0上发生的情况是:

于是,我们可以得到一个总的时间:
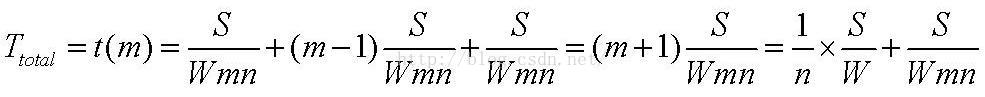
其中S,W,N都是确定的,m是变量,对其求极限,可知
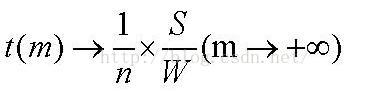
不但整个文件分了N段,而且每一个片段中又细分了m个子段,这样虽然第一个Tx时间是N0在唱独角戏,最后一个Tx时间是N1到Nn在合唱,但是这确实是一个无极变速,如果Tx特别小,这两次Tx的时间在总的时间阶段中就可以忽略不计了,形成一个全P2P网络相互交换自己没有的部分的局面,如果想让Tx足够小,很简单,片断足够小即可。
从最初的一次性下载到分两步交换,变成了如今的m+1步,这就是不断细分文件的效果。好了,现在已经度过了初始构建阶段,现在所有的N+1个节点上都有了完整的文件F,在描述稳定阶段前,先来考虑一个问题,那就是片断的交换是不是也可以这样做呢?
片断交换的递归
P2P网络传输的一个效果就是消除数据重复传输,即消除了冗余。然而你会发现,上面描述的片断交换过程中,文件片断在N1到Nn之间的交换都是冗余传输的,比如N1要把它所拥有的片断发给其它所有的节点,所用时间为Tx。为了消除这个冗余,也可以递归按照文件F从N0传输到N1至Nn的过程一样。此时传输的已经不是一个文件了,而是一个文件片断。按照刚才的论述,它所用的时间相对于Tx具有N-1倍的加速比(因为无需传输给N0)。如果说这么连文件片断也继续细分子片断,子子片断,最终的终点就是bit了,虽然这种情况的发生是极不明智的(这是不是就是BT中Bit的成因??)。
3.2.稳定阶段
经历了初始构建阶段后,所有的N+1个节点都有了完整的文件F,现在假设新加入一个节点,它也需要这个文件,就不用重复刚才的过程了。现在节点总数为N+2,文件可以分为N+1份片断,由N0到Nn分别传输给Nn+1。当然,真正的P2P传输是很复杂的,涉及到P2P地图的构建,你要知道整个P2P网络的信息,比如有多少节点,你要从哪个节点获取文件的哪个部分等等,还要处理节点退出以及新节点加入等动态问题。后面的世界很精彩,但已经超出了本文以及本人的能力范围。
最终的结论是,下载文件的恒定加速比为N,N为除了自己之外的节点数量。理解它很简单,原来是1个节点给你传文件,时间是S/W,现在N个节点一起给你传文件,每一个传输1/N大小,时间当然是原来的1/N了。
4.小片断与硬盘
理解了上述原理,就知道P2P下载基本都是片断片断下载的,而且片断不一定连续,如果是机械硬盘,那么在写入硬盘的过程中就会导致硬盘频繁的调头,前冲,急停...这会造成磁盘高速马达的损耗。因此P2P下载对机械硬盘是有损耗的。虽然一系列的算法正试图改变这个令人悲哀的局面,但是基本原理导致了它不会被根除。再说,我们不是都用SSD了么?使用SSD的问题在于如果P2P算法不好,不连续的片断持续到来会影响对时间/空间局部性的利用。正确的做法是,如果内存够大,就先创建一个内存盘,专门进行P2P下载,然后完毕后统一写到真实的硬盘。
再分享一下我老师大神的人工智能教程吧。零基础!通俗易懂!风趣幽默!还带黄段子!希望你也加入到我们人工智能的队伍中来!https://blog.csdn.net/jiangjunshow