Python编程语言无疑是人工智能最重要的语言之一,但是其中语音识别是当前人工智能比较热门的方向,百度的小度机器人、阿里的天猫精灵等其他各大公司都推出了各自的语音助手机器人,其识别算法主要是由RNN、LSTM、DNN-HMM等机器学习和深度学习技术做支撑。但训练这些模型的第一步就是将音频文件数据化,提取当中的语音特征。
MP3文件转化为WAV文件
录制音频文件的软件大多数都是以mp3格式输出的,但mp3格式文件对语音的压缩比例较重,因此首先利用ffmpeg将转化为wav原始文件有利于语音特征的提取。其转化代码如下: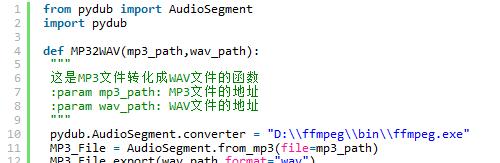
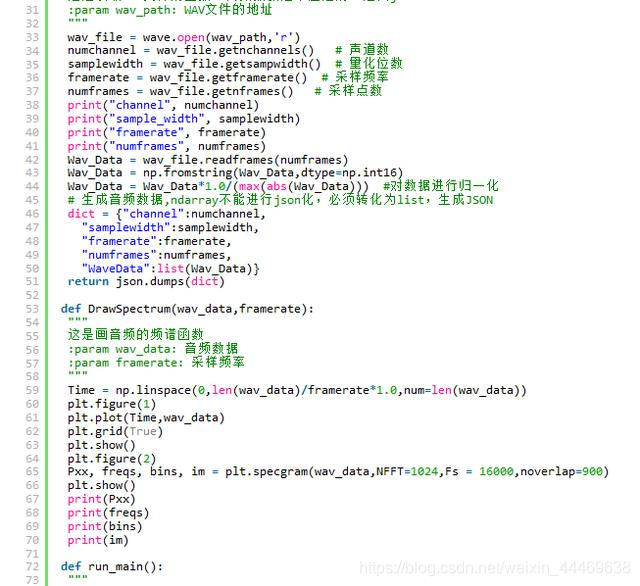
读取WAV语音文件,对语音进行采样
利用wave库对语音文件进行采样。
代码如下: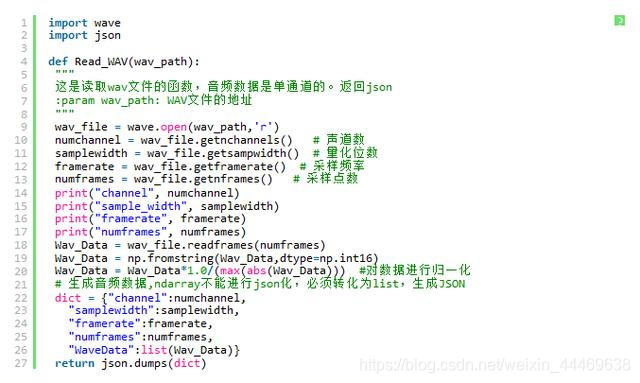
绘制声波折线图与频谱图
代码如下: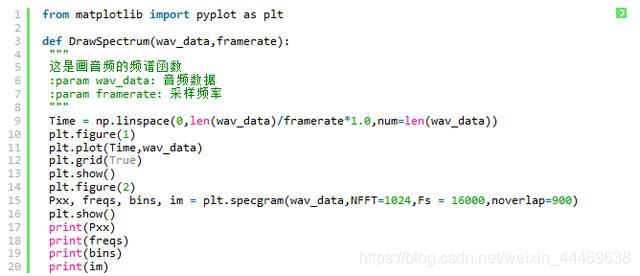
首先利用百度AI开发平台的语音合API生成的MP3文件进行上述过程的结果。
声波折线图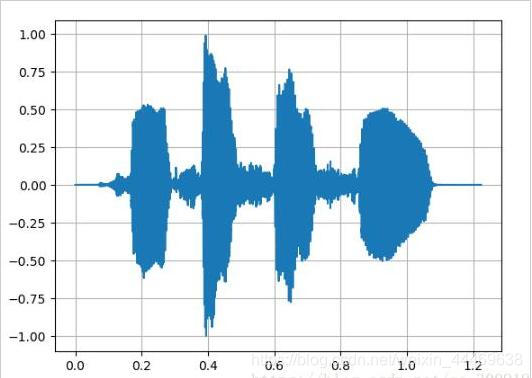
频谱图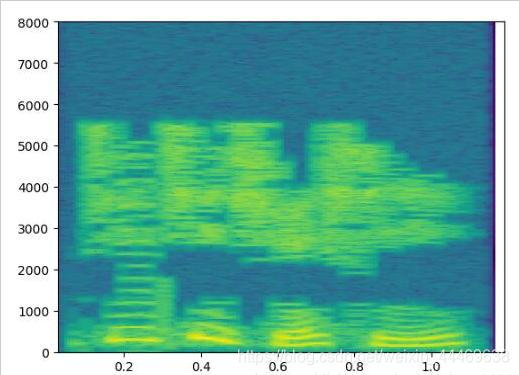
全部代码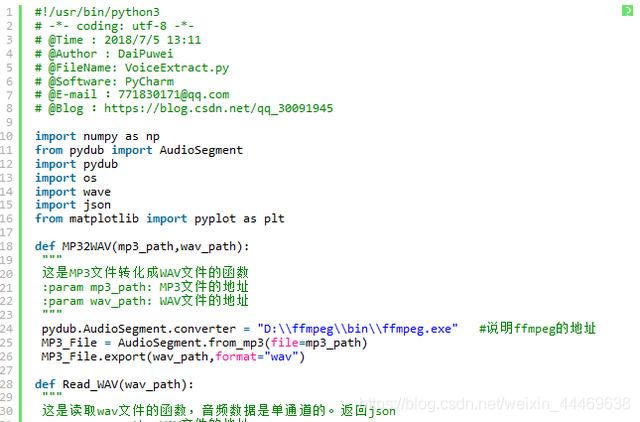

以上这篇就是小编分享的使用python实现语音文件的特征提取方法。