在深度学习的路上,从头开始了解一下各项技术。本人是DL小白,连续记录我自己看的一些东西,大家可以互相交流。
本文参考:https://blog.csdn.net/u013378306/article/details/65954965 (MFCC)
https://zhuanlan.zhihu.com/p/19763358(傅立叶变换理解)
https://blog.csdn.net/xiaoding133/article/details/8106672(预处理)
一、前言
在任何一个语音识别系统中,第一步就是提取特征,将一段声音转化为计算机可以识别的数字序列或向量。我们需要把音频信号中,具有辨识度的成分提取出来,去除其他不需要的信息,比如背景噪音、情绪等等。
MFCC(Mel frequency Cepstral Coefficients)梅尔频率倒谱系数,是一种在自动语音和说话人识别中广泛使用的特征。1980年,由Davis和Mermelstein提出。
本文分为两个部分,分别阐述MFCC的理论理解,以及MFCC的提取过程。
二、声谱图(Spectrogram)与频谱图(Spectrum)
声谱图是我们用于描述语音信号的一种方式。其中,横轴为时间(Time-s),竖轴为振幅(Amplitude-dB)。(下图上半部分)

在声谱图中,我们将横轴时间切分为很多帧,其中每帧语音都对应与一个频谱(通过短时FFT计算)。
频谱图,表示频率与能量的关系,横轴为频率(Frequency-Hz),竖轴为振幅(Amplitude-dB)。(下图左1)
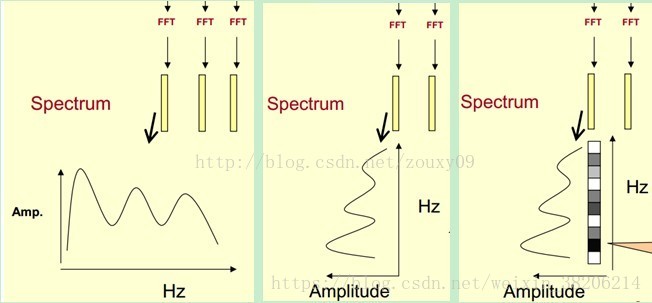
在对声谱图做FFT计算得到频谱图之后,我们先将其中一帧语音的频谱图通过坐标表示(左1)。我们首先将频谱图逆时针旋转90度,得到左2。然后将振幅映射到一个灰度级表示(可以理解是将连续的振幅量化为256个量化值)。其中0为黑,255为白,振幅越大,对应区域越黑,反之亦然,得到图左3。之后我们将每一帧的频谱图结合,即可得到该声谱图对应的,随时间变化的声谱图(下图)。
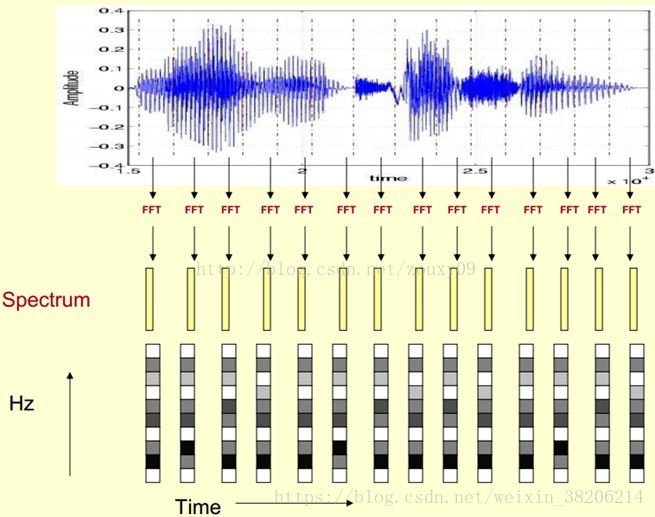
该部分由于涉及到FFT变化以及时域到频域的变化,如有难理解的地方,可以了解一下傅立叶变换的逻辑,见链接
https://zhuanlan.zhihu.com/p/19763358
三、倒谱分析(Cepstrum Analysis)
倒谱分析是对频谱图的处理分析过程,其中运用了同态信号处理。它的目的是将非线性问题转化为线性问题的处理方法。原来的语音信号,实际上是一个卷性信号。
第一步通过卷积将其转换为乘性信号(时域的卷积等于频域的乘积,即从声谱图转变为频谱图)。
第二步通过取对数,将乘性信号转化为加性信号(运用log的运算性质:logMN = logM + logN)。
第三步进行逆傅立叶变换,将加性信号恢复为卷性信号。
接下来,我们对整个倒谱分析做一个具体的解释。
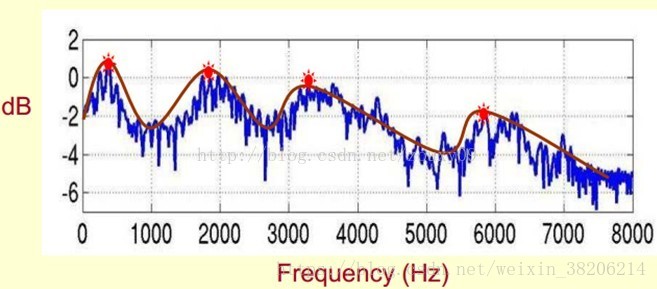
首先,对于一个语音的频谱图,其峰值就表示语音的主要频率成分,我们将其峰值称为共振峰(formants),而共振峰就是携带声音辨识属性的元素,对于我们识别不同声音很重要。

我们在提取共振峰的时候,不仅仅要提取共振峰的位置,同时还需要提取到它转变的过程,所以我们提取的是频谱的包络(Spectral Envelope),包络是一条链接这些共振峰点的平滑曲线(下图)。
那么,我们可以理解为,将原始的频谱分为两个部分,包络和频谱的细节(其他部分)。我们将其分开,即得到下图。我们将包络设定为log X[k],频谱的细节设定为log H[k]。
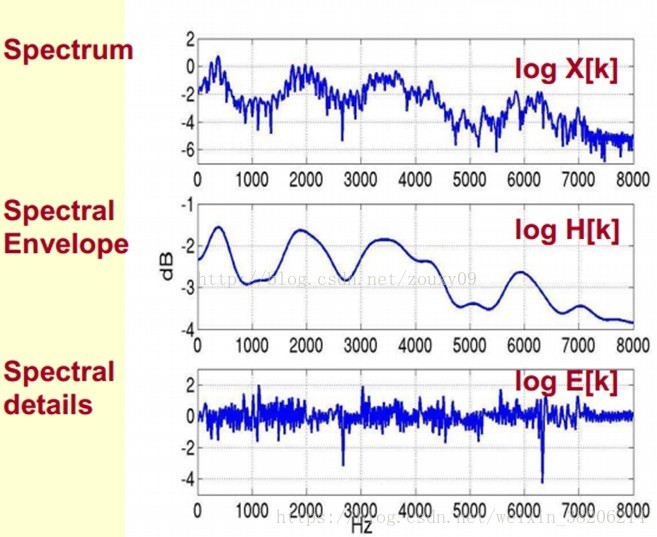
其中,我们已知频谱log X[k],所以我们需要求得log H[k]和log E[k],使其满足log X[k] = log H[k] + log E[k]。
接下来,我们需要对频谱做一个数学转化,即为对频谱做FFT。因为我们从声谱图做FFT转化为频谱图,所以对频谱做FFT可以理解是逆傅立叶变换IFFT(Inverse FFT)。
由下图可见,我们在给频谱做IFFT时,包络主要是低频部分,而频谱的细节部分主要是高谱部分。

将IFFT逆转之后的部分,叠加起来,即可得到原来的频谱信号。
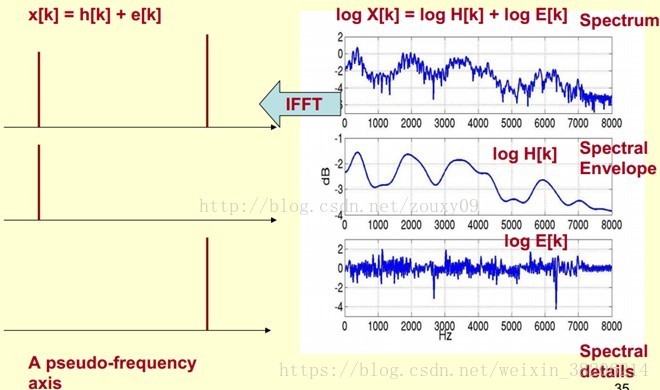
在实际运算过程中,我们已知log X[k],所以可以求得x[k]。由上图可知,x[k]的低频部分是h[k]。将x[k]通过一个低通滤波器就可以获得h[k]。也就是频谱的包络。
总结下, x[k]实际上就是倒谱(cepstrum),而我们关心的h[k]就是倒谱的低频部分,描述了频谱的包络,也是语音识别中被广泛应用于描述特征。整个倒谱(cepstrum)就是一种信号的傅立叶变换,经对数运算后,再进行逆傅立叶变换得到的谱,计算过程如下:

公式如下:
1)将原语音信号经过傅里叶变换得到频谱:X[k]=H[k]E[k](只考虑幅度就是:|X[k] |=|H[k]||E[k] |);
2)我们在两边取对数:log||X[k] ||= log ||H[k] ||+ log ||E[k] ||。
3)再在两边取逆傅里叶变换得到:x[k]=h[k]+e[k]。
四、Mel频率分析(Mel-Frequency Analysis)
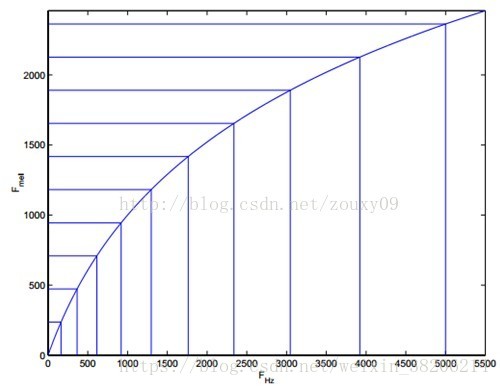
以上,即为倒谱分析。即我们从一段语音,提出得到它的频谱包络,但是从人类听觉实验表明,人类听觉仅仅聚焦在某些特定的区域,而不是整个频谱包络。根据Mel频率分析,我们发现人耳类似于一个滤波组,只关注特定的频率分量。并且这些滤波器在频率坐标轴上,并不是统一分布的,在低频区域有很多的滤波器,分布比较密集,在高频区域,滤波器的数目会比较少,分布很稀疏(如下图)。
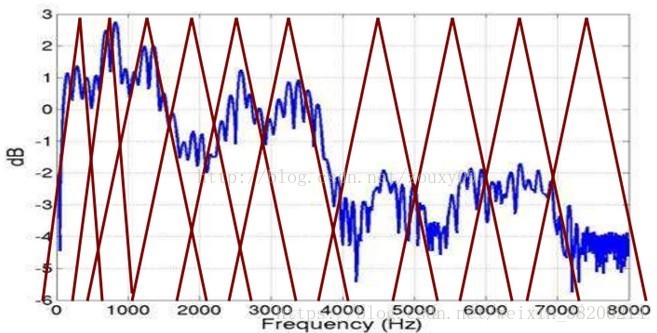
MFCC(梅尔频率倒谱系数)考虑到了人类听觉特征,过程是先将线性频谱映射到基于听觉感知的Mel非线性频谱中,然后转换到倒谱上。
其中将普通频率转化到Mel频率的公式是:
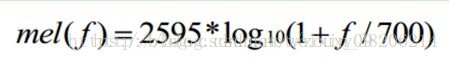
公式图像为:
五、Mel频率倒谱系数(Mel-Frequency Cepstral Coefficients)
我们将频谱通过一组Mel滤波器就可以得到Mel频谱。其公式表示为:
log X[k] = log(Mel-Spectrum)
这时候,我们可以在log X[k]上进行倒谱分析:
1> 取对数:log X[k] = log H[k] + log E[k]
2>进行逆变换: x[k] = h[k] + e[k]
在Mel频谱上面倒谱分析获得的包络h[k],就称为Mel频率倒谱系数(MFCC)。
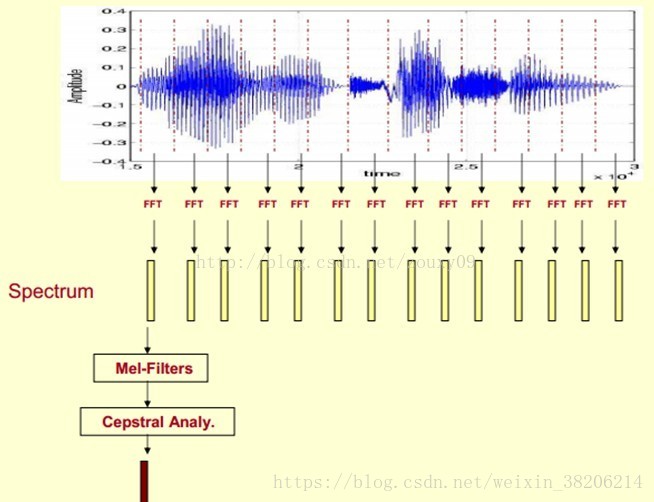
总结而言,提取MFCC特征的过程:
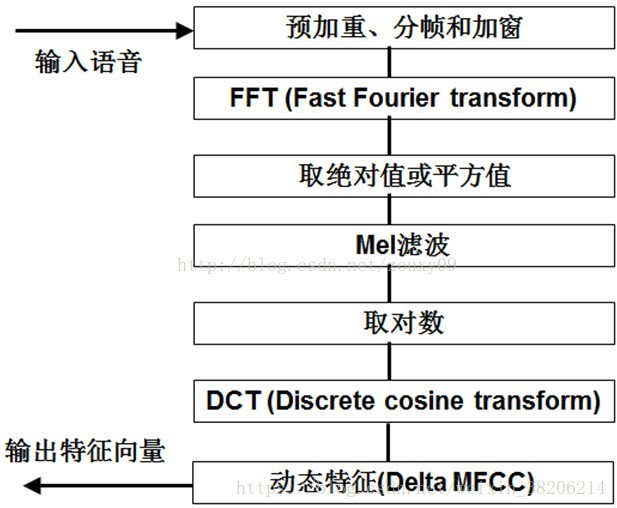
1> 先对语音进行预加重、分帧和加窗;
2>对于每一个短时分析窗(即分出的每一帧),通过FFT得到对应的频谱;
3>将上面计算得到的频谱通过Mel滤波器组,得到Mel频谱;
4>在Mel频谱上进行倒谱分析(取对数、逆变换(见ps)),获得Mel频谱倒谱系数MFCC,这个MFCC就是这帧语音的特征。
ps.在Mel倒谱分析过程中,实际的逆变换一般是通过DCT离散余弦变化。取DCT之后的第2个到第13个系数,作为MFCC系数。
ps.对语音进行预加重、分帧和加窗,实际上是对语音的类似于正则化和分帧的过程,具体可以参考博客
https://blog.csdn.net/xiaoding133/article/details/8106672