一、损失函数定义
1.经典损失函数
1)分类问题
交叉熵刻画两个概率分布之间的距离,是分类问题中使用比较广泛的一种损失函数。
2)回归问题
对于回归问题,最常用的损失函数时均方误差(MSE,mean squared error)
2.自定义损失函数
二、神经网络优化
梯度下降与反向传播:梯度下降算法主要用于优化单个参数的取值;而反向传播算法给出了一个高效的方式在所有参数上使用梯度下降算法,从而使神经网络模型在训练数据上的损失函数尽可能小。
1.梯度下降(gradient decent)
纵坐标为损失函数,目标:损失函数最小化
梯度下降算法会迭代更新参数,不断沿着梯度的反方向让参数朝着总损失更小的方向更新。

通过参数的梯度和学习率,参数更新公式为:
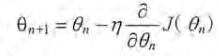
需要注意的是:
1)梯度下降算法并不能保证被优化的函数达到全局最优解。
2)梯度下降算法计算时间太长。因为要在全部训练数据上最小化损失,所以损失函数是在所有训练数据上的损失和。这样每一轮迭代中都需要计算在全部训练数据上的损失函数,在海量训练数据下,计算所有训练数据的损失函数时非常耗时的。
2.随机梯度下降(stochastic gradient descent)
为了加速训练过程,可以使用随机梯度下降算法。此算法不是在全部训练数据上的损失函数,而是在每一轮迭代中,随机优化某一条训练数据上的损失函数。这样每一轮参数更新速度就大大加快。
因为随机梯度下降算法每次优化的只是某一条数据上的损失函数,所以它的问题很明显:在某一条数据上损失函数更小并不代表在全部数据上损失函数更小。因此,使用随机梯度下降优化得到的神经网络甚至可能无法达到局部最优。
3.batch-梯度下降
综合梯度下降与随机梯度下降算法的优缺点,在实际应用中,采用上述两个算法的折中——每次计算一小部分训练数据的损失函数。这一小部分数据被称为一个batch。
通过矩阵运算,每次在一个batch上优化神经网络的参数并不会比单个数据慢太多。另一方面,每次使用一个batch可以大大减小收敛所需的迭代次数,同时可以使收敛到的结果更加接近梯度下降的效果。
三、神经网络进一步优化
1.学习率的设置(learning rate):指数衰减法
通过设置学习率控制参数更新的速度。学习率决定了参数每次更新的幅度,如果幅度过大,可能导致参数在极优值两侧来回移动;如果学习率过小,虽然可保证收敛,但大大降低优化速度。
TensorFlow提供了一种灵活的学习率设置方法:指数衰减法。指数衰减学习率,可以使用较大的学习率快速得到一个比较优的解,然后随着迭代的继续逐渐减小学习率,使得模型在训练后期更加稳定。
2.过拟合:正则化
过拟合:指当一个模型过为复杂后,可以很好地记忆每一个训练数据中随机噪音的部分而忘记了要去学习训练数据中通用的趋势。
为避免过拟合,常用的方法是正则化(regularization)。思想:在损失函数中加入刻画模型复杂程度的指标。

L1正则化:
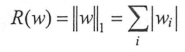
L2正则化:
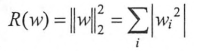
L1、L2正则化基本思想:希望通过限制权重大小,使得模型不能任意拟合训练数据中的随机噪音。
L1与L2正则化区别:
1)L1正则化会让参数变得更稀疏,L2不会。参数变得更稀疏是指会有更多的参数变为0,可以达到类似特征选择的功能;L2正则化不会让参数变得稀疏,原因是当参数很小时,如0.001,这个参数的平方基本忽略,模型不会进一步将此参数调整为0。
2)L1正则化计算公式不可导,L2正则化公式可导。优化时需要计算损失函数的偏导数,所以对含L2正则化损失函数的优化更加简洁;优化带L1正则化的损失函数更加复杂,且优化方法较多。
在实践中,也可将L1正则化与L2正则化同时使用:
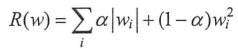
3.滑动平均模型
滑动平均模型将每一轮迭代得到的模型综合起来,从而使得最终的模型更加健壮。
采用随机梯度下降算法训练神经网络时,使用滑动平均模型在很多应用中都可以在一定程度上提高最终模型在测试数据上的表现。