在HDFS中常见的容错恢复是副本机制,它会在部分文件丢失之后通过心跳机制发数据给NameNode然后寻找未丢失的副本,按照replication进行备份。这样的话会保证数据在绝大多数情况下不丢失。但是造成的问题就是这种机制使得Hadoop的空间利用率会很低。比如说在一个备份数量为3的情况下空间利用率仅为1/3,而从空间利用率这个维度来看的话用于容错恢复的纠删码机制表现的不错。
在这里我斗胆说一句纠删码基于信息论中的互信息,就是一个不知道的信息可以由其它和它相关的信息所推算出来。以下是叶老师(叶尚青)的例子:

在①丢失的情况下能够通过④⑤⑥推导出来(或者是②③④亦或是②③⑤⑥)。但是关键的信息都丢掉了的话比如说丢失其中的两个方程与两个值这时候就无法挽救了但是这种概率是非常低的。实务上纠删码是非常厉害的。
实务上里索码是纠删码思想的一种实现,在HDFS中会用主要的硬盘资源存储实际的数据,而使用少数的机器去存储数据之间的依赖关系如下图所示:

整个纠删码的使用包括编码和解码:
编码阶段让n个不同的数据块与m个数据校验块组成一个(n + m) * n的矩阵,然后再乘以原始数据组成的一个矩阵进而得到一个新的矩阵。这个过程称为编码如下图所示:

如果数据丢失了一些这时就需要通过已有的信息去解码,进而推算出丢失的信息也就是下图书中D矩阵的信息。我们首先得到出当前数据单位矩阵与校验块组成的矩阵B。然后计算这个矩阵的逆矩阵B-1 。然后通过B-1 * B * D = B-1 * Survivors 得到矩阵D(左边就只剩下单位矩阵与D矩阵的乘积)。计算的过程如下图所示:

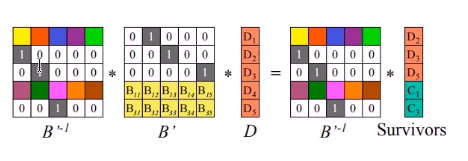
这样就顺利的解出丢失的数据了。
在数据量较大状态下纠删码机制可以将磁盘的利用率收敛于100%,但是它的容错恢复会带来大量的计算这样会使得读写数据的效率低下。