转载自:https://zhuanlan.zhihu.com/p/32214787
研究的基本问题:
对应流程中的三个过程有三个研究的基本问题:
1.问题分析:如何去分析问题;
2.信息检索:如何根据问题的分析结果去缩小答案 可能存在的范围;
3. 答案抽取:如何从可能存在答案的信息块中抽取答案。
在问答系统的不同发展阶段, 对于这三个基本问题的解决方法随着数据类型的变化在不断变化, 从而形成了不同类型的问答系统。
复杂性:
问答系统的复杂程度可以从三个维度来衡量:
1.问题:对于问题维度, 问答系统可以分为限定领域(指系统能接受的问题只 能是关于某个特定的主题)的问答系统和开放领域 (指系统能接受的问题可以是任意主题的问题, 没 有任何限制)的问答系统.
2.数据:对于数据维度, 问答系统可以分为处理结构数据(或半结构数据)的问答系统 (例如关系数据)和处理无结构数据(例如文本)的问答系统.
3.答案:对于答案维度, 问答系统可以分为抽取式 (所谓抽取, 是指答案是从数据或者文本中抽取出 来的, 例如文本片段)问答系统和产生式(所谓产生, 是指答案是通过一定的规则或者内在的编码生成 出来的, 例如对话)问答系统。
问答系统根据问题、数据、答案三个维度的不同而属于不同类别。
发展历程:
依据问答系统处理的数据格式, 将问答系统的发展历史划分为三个阶段:
1.基于结构化数据的发展阶段.
基于结构化数据的发展阶段又可以划分为人工智能阶段和计算语言学阶段两个子阶段。
1.1 人工智能阶段:
在 20 世纪 60 年代, 由于人工智能的发展, 研究人员试图建立一种能回答人们提问的智能系统。 这个时期主要是限定领域、处理结构数据的问答系统, 被称为 AI 时期, 主要都是 AI 系统和专家系统, 代表系统有BASEBALL和LUNAR。
1.2 计算语言学阶段:
在20世纪70年代和 80 年代, 由于计算语言学的兴起, 大量研究集中在如何利用计算语言学技术去降低构建问答系统的成本和难度。这个时期被称为计算语言学时期, 主要集中在限定领域和处理结构数据, 代表系统是Unix Consultant。
2.基于自由文本数据的发展阶段.
20世纪 90年代, 问答系统进入开放领域、 基于文本的新时期。由于互联网的飞速发展, 产生了大量的电子文档, 这为问答系统进入开放领域、 基于文本的时期提供了客观条件。特别是在1999 年 TREC(text retrieval conference)的 QA track设立以来, 极大地推动了问答系统的发展。
3.基于问题答案对数据的发展阶段.
随着互联网技术的成熟和普及, 网络上出现了常问问题(frequent asked questions, FAQ)数据, 特别是在 2005 年末以来大量 的社区问答(community based question answering, CQA)数据(例如 Yahoo!Answer)出现在网络上, 即有了大量的问题答案对数据, 问答系统进入了开放领域、基于问题答案对时期。
由于各个阶段处理的数据格式和形式不同, 导致各个阶段解决问答系统的三个基本问题的方法 和技术各不相同。我们分别对这三个阶段各自的问题进行叙述。
基于结构化数据的问答系统
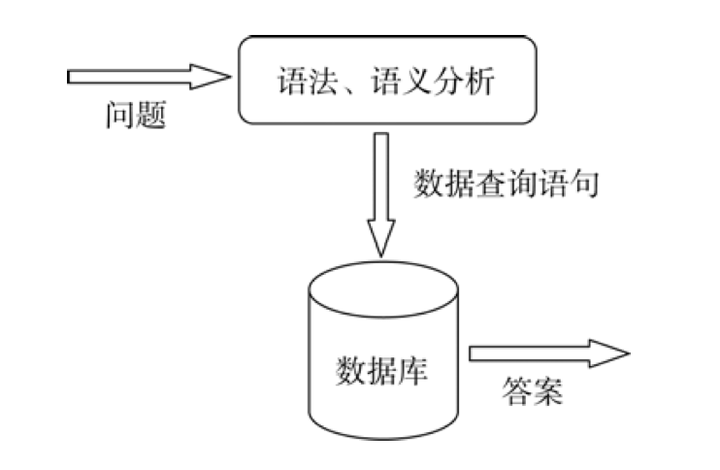
基于结构化数据的问答系统的主要思想是通过分析问题, 把问题转化为一个查询(query), 然后在 结构化数据中进行查询, 返回的查询结果即为问题 的答案。从其基本思想可知, 这种方法一般只能用在限定领域。
处理流程:
- 根据问题特点来分析问题, 产生一个结构数据的查询语言格式的查询(对应于问答系统的问 题分析部分)。
- 将产生的查询提交给管理结构数据的系统 (如数据库等), 系统根据查询的限制条件筛选数据 (对应于问答系统的信息检索部分, 即缩小答案可能存在的范围)。
- 把匹配的数据作为答案返回给用户(对应 于问答系统的答案抽取部分, 由于数据库查询的精 确匹配特性, “抽取”的动作不明显)。
两个关键问题:
一、需要构建一个特定领域的比较完备的结 构数据库.
二、准确、高效地把问题转化为查询语言形式的查询。
基于自由文本的问答系统
基于自由文本(free-text based)的问答系统属于开放域问答系统, 它只能回答那些答案存在于这个 文档集合中的问题。体系结构图如下:
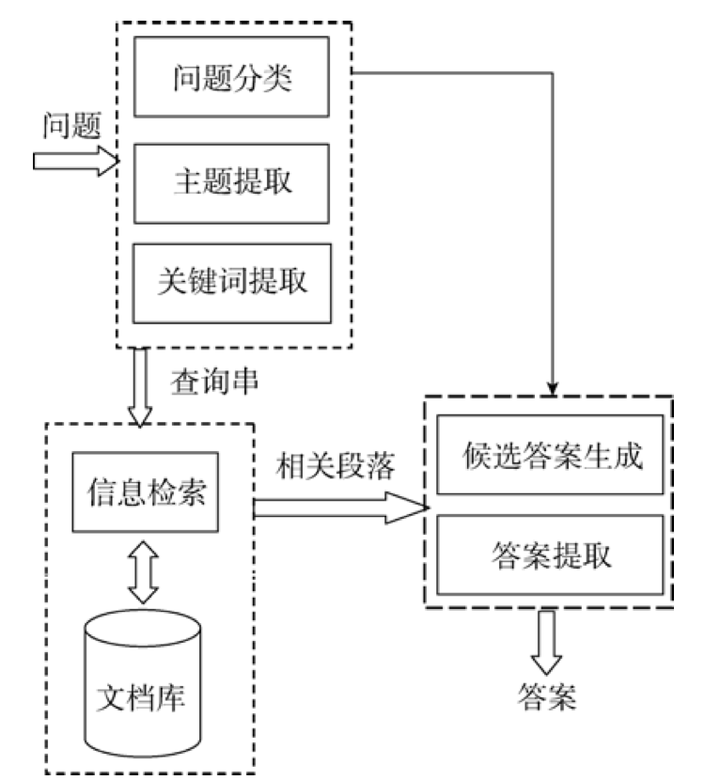
问题分析:
问题分析部分主要是用于分析和理解问题, 从而协助后续的检索和答案提取, 一般具有问句分类、问句主题提取两个主要研究内容。
1.问句分类:
问句分类是根据问句的答案类型对问句进行分类.问句分类的任务就是把一个问句分类到已有的分类结构中一个或几个类(软分类)。问句分类的方法主要包括模式匹配方法和机器学习方法两类。效果比较好的分类方法有:
- Zhang 等人在<Question classification using support vector machines>中,使用表层 n-gram 特征, 在K最近邻算法、决策树、朴素贝叶斯等分类方法中, 支持向量 机(support vector machine, SVM)效果较好。
- Li 等人在<Learning question classifiers>中,采用更深层次的特征, 包括语法(词性、词组)和 语义(解释、近义词)信息, 首先顶层分类器把问句归 类在一个大类别中, 然后根据该大类内的分类器把它分到小类别中, 分类效果较好。
2.问句主题:
信息检索部分需要选择问题中的一些关键词作为查询词, 很多时候会调整查询, 为了保证高相关性, 查询词都应该包含问题的主题。一般通过对问题进行句法分析, 获得问题的中心词, 然后选取中心词及其修饰词作为问题的主题。因此, 如何选取合适的中心词是该类方法的核心。比较有效的方法有:
- Cui 等人在<Unsupervised learning of soft patterns for generating definitions from online news>中,提出了一种基于外部资源选取主题的方法。它利用搜索引擎返回的结果去计算各种词组合的点互信息, 如 果词组合的点互信息高于某个阈值就被认为是词 组, 那么词组的序列就被认为是问题的主题。
信息检索:
信息检索的主要目的是缩小答案的范围, 提高下一步答案抽取的效率和精度。信息检索一般分为两个步骤:
(1) 文档检索, 即检索出可能包含答案的文档。
(2) 段落检索, 即从候选文档中检索(抽取)出 可能包含答案的段落。
1.文档检索
文档检索是给定一个由问题产生的查询, 通过某个检索模型去得到相关的文档。有两个问题需要处理:
一、是检索模型的选取;
二、是查询的生成。
2.段落检索
段落检索就是从候选文档集合中检索出最有可 能含有答案的段落 [16] (自然段落或者文档片段),进 一步缩小答案存在的范围。实验结果表明, 基于密度的算法可以获得相对较好的效果,目前表现比较好的段落检索算法有三个:
- MultiText 算法 ;
- IBM 的算法 ;
- SiteQ 算法 ;
基于密度的算法只考虑了独立的关键词及其位置信息, 没有考虑关键词在问句中的先后顺序, 也没有考虑语法和语义信息。Cui 等人 在<Question answering passage retrieval using dependency relations>中提出了一 种基于模糊依赖关系匹配的算法。这种算法把问题和答案都解析成为语法树, 并且从中得到词与词之间的依赖关系, 然后通过依赖关系匹配的程度来进行排序。实验结果表明, 这种方法的检索效果比基于密度算法好。
3.富信息索引
传统检索方法一般只需要处理关键词, 而问答 系统需要处理更多的语法、语义信息。因此, 部分 问答系统也把语法、语义等信息添加到索引中, 丰 富了传统的索引, 以提高检索效果。
答案抽取:
答案抽取的主要目的是得到用户想要的答案,满足用户需求.为了提取答案, 一般有两个步骤:
- 生成候选答案集合。
- 提取答案。
1.候选答案集合的生成
通过问题分析, 已经获得问句的类别。 目前问 答系统能处理的问题类型一般都是事实类型的问 题, 大多数的问题类型对应的答案比较短, 可能是 实体名, 如人名、地点等, 可能是抽象名词, 如人 类、学科、树木、植物等, 也可能是数字, 如距离、 速度等。对于这类问题, 可以通过找到相应类型的 词、词组或者片断来回答。
2.答案提取.
在得到候选答案集合以后, 主要有四种方法获 得问句的最佳答案:
- 基于表层特征的答案提取。
- 通过关系抽取答案。
- 通过模式匹配抽取答案。
- 利用统计模型抽取答案。
基于问题答案对的问答系统
基于问题答案对的问答系统研究主要有两个发展阶段:
- 基于常问问题(FAQ)列表的问答系统 研究阶段;
- 基于社区问答(CQA)的问答系统研究阶段。
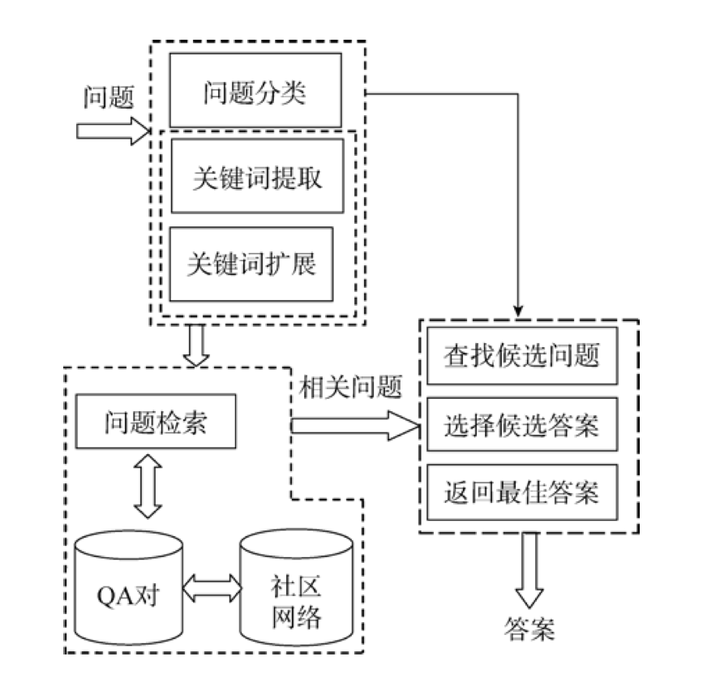
问题分析
和基于自由文本的问答系统的问题分析部分基本一样, 不过还多了几个不同的研究点。
1.问题主客观的判断.
基于结构数据的问答系统和基于自由文本的问 答系统一般都只能处理客观、事实类型(factoid)的问题。然而在 CQA 数据中有大量的主观类型的问题, 而对于主观类型的问题和客观类型的问题有不同 的处理方式, 例如主观问题没有标准答案, 而且答 案可以多个, 然而客观问题却只能有一个标准答案。
2.问题的紧急性.
在 CQA 数据中, 由于存在一个社区网络, 有用户的互动参与, 当问题的紧急程度不一样时, 系统应该有不一样的处理方式。因为有些问题很长时间 回答都没有影响, 但是有些问题需要尽快地得到回答。对于紧急性的问题, 系统应对它进行快速处理, 或者尽量把它放在明显的位置让其他用户进行回答; 对于紧急程度不高的问题, 就不用这样进行特别处理。对于问题的紧急性判断处理的好坏, 将直接影响到用户对一个 CQA 问答系统的评价, 因此非常重要。
信息检索
找到和问题类似的问题, 然后返回答案或者相似问题列表.研究适合问题答案对的检索模型和两个问题的相似性判断是最关键的两个问题。
1.研究问题答案对的检索模型.
在经过问题分析之后, 需要通过信息检索部分把相关的问题检索出来, 然后才能在答案抽取部分抽取合适的答案。研究成果有:
- Duan 等人 <Searching questions by identifying question topic and question fo-cus> 采用基于最小描述长度(minimum description length, MDL)的树剪切(tree cut)模型去识 别问题的主题和焦点, 然后利用语言模型的方法去 匹配问题主题和焦点来缩小检索范围, 提高检索精 度。
- Xue 等人在<Retrieval models for question and answer archives>中 ,首先构建一个相似问题的集合, 然 后训练一个翻译模型, 对问题部分采用基于翻译模 型的语言模型, 对答案部分采用 Query Likelihood 模型, 这两者合并在一起构成了一个检索模型。
- Bian 等人在 <Finding the right facts in the crowd: factoid question answering over social media>中 提出了对于事实类型问题的检索框架, 属于半监督的方法。实验发现, 其中的文本特征和社区特征对于检索效果的影响很大; 同时, 其他特 征, 如用户的反馈, 也能提高训练排序函数的效 果。
- Wang 等人 在<Ranking community answers by modeling question-answer relationships via analogical reasoning>中通过类比推理技术去建模问题与答案之间的关系, 提出了对于答案的排序方法。实验表明这种方法的平均排序倒数(mean reciprocal rank, MRR)值能达到 78%, 比采用朴素贝叶斯和 Cosine 的方法效果都好。
2.研究问题答案对的相似性.
除了从传统的信息检索的角度来看待信息检索部分, 还可以从问题对相似性的角度来看这个问题。其实传统的信息检索角度, 其本质也是把相似的问题检索出来。首先把与给定问题相似的问题找到, 然后再在相似的问题中寻找最好的答案。研究成果有:
- Wang 等人 在<A syntactic tree matching approach to finding similar questions in com-munity-based QA services>中,通过将每一个问题句子都生成其 syntactic tree 的形式, 然后比较问题的 syntactic tree 的相似性来判断问题的相似性。实验表明, 这种问 题的 syntactic tree 特征对于问题的相似性比较具有 明显的价值。还有一些研究主要依据这样一个假设:“如果两个问题的答案相似, 那么这两个问题是相似的”, 因此作者把问题的所有答案作为单一文档, 然后用语言模型去计算答案之间的相似性, 从而去判断两个问题之间的相似性。
- Akiyoshi 等人在 <A retrieval method for similar Q&A articles of Web bulletin board with relevance index derived from commercial Web search engine>中采用简单的基于关键字的检索方法去缩小搜索范围, 然后再利用 BBS 文章的结构特征(即 thread 结构, 一个 thread 包含一个问题网页和一组答案网页), 基于这种结构特征, 可以计算一篇问题文章和商业 搜索引擎返回的词之间的相关性, 最后来判断其 相似性。 作者在一个BBS站点上进行了实验, 结果表明比基于 Cosine 的相似度方法提高了 30%的 准确率。
答案抽取部分
在答案抽取部分, 由于问题答案对已经有了答 案, 答案抽取最重要的工作就是判断答案的质量.研究怎么从问题的众多答案中选择一个最好的答案.
Liu等人在<Understanding and summarizing answers in community-based question answering services>中提出了问题和答案的分类体系, 特 别是对 open 和 opinion 类型的问题进行了研究, 以 提高这两种类型问题的答案质量, 并通过实验得出 这两种类型的问题占总问题数目的 56%~80%的结 论。
- Jeon等人在<A framework to predict the quality of answers with non-textual features>中利用非文本特征来预测答案的质量, 主要用到的特征有答案的接受率、答案长度、提问 者的自评、回答问题的人的积极程度、回答问题的 人的回答问题偏好、用户打印答案的次数、用户拷 贝答案到他们博客的次数、用户的推荐次数、服务 提供商的推荐、是否是 Sponsor 的答案、点击次数、 答案的数目、用户的不推荐数目等。作者系统地分析了这些非文本特征对于预测答案质量的作用, 最后应用最大熵方法和核密度方法去预测答案的质量。
- Liu等人的<Understanding and summarizing answers in community-based question answering services>和 Tomasoni 等人的 <Metadata-aware measures for answer summarization in community question answering> 中,利用大多数 CQA问题都有多个答案的特性, 把答案抽取的问题转换为多文档摘要的问题, 从而达到较好的效果。