问答系统主要术语:问题类型、答案类型、问句焦点、问句主题、候选段落、候选答案。分别介绍如下:
问题类型:对问题的分类,用以产生相应的策略和答案形式。
问题分为:事实类问题,列表类问题,定义类问题,列表类问题难度较大,因为涉及到不同的实体识别,这些实体往往分散在不同的文本段落。定义类问题难度最大,识别出用户提出的概念,然后再组织语言给出答案。另外还有根据语言学分为是非类问题、关系型问题、最型问题(比如最大,最好,最高)、观点类问题(带有主观性的评价)、原因结果问题(比如,为什么科学技术是第一生产力?)
答案类型:问句对应的目标的类型,由问题模式直接决定,比如问who is the ....?返回的答案类型就是一个人名。答案类型受命名实体识别技术范畴的影响,比如人名、地名、组织机构、时间、货币、体积、重量、尺寸、面积、颜色等
问句焦点:问题中的主题是对象,是宿主,宿主的属性则是焦点。
候选段落:由搜索引擎响应用户产生的文本片段,给每个段落相应的权重。找到合适的阈值。不一定越多越好。然后将用户问句与候选段落进行匹配,然后进行答案抽取,返回答案。
答案:涉及到信息抽取、实体识别。
问答系统结构:
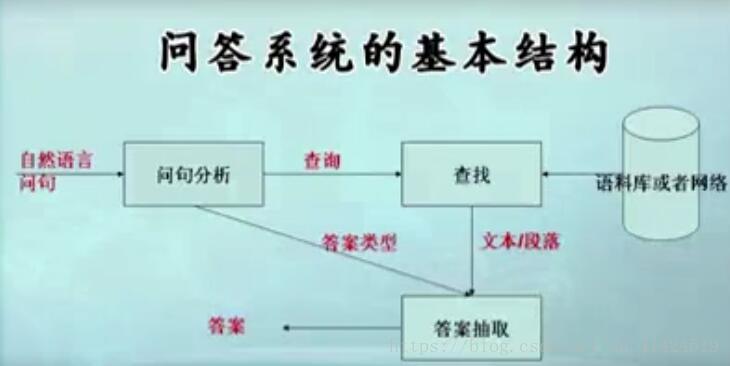
问答系统相关的技术:网络相关的,有网络爬虫、谷歌API、百度api的接口获得并调用其内部搜索的结果、网页去重、网页正文内容提取,数据库索引(开源数据库MYSQL)。
智能化信息检索模型研究:现有的信息检索模型有:布尔模型、向量空间模型、概率模型。概率模型可以看做是N-gram模型在信息检索领域的应用。
基于结构映射理论的新型信息检索模型-------系统相似性模型:向量空间的本源理论模型;通用性理论模型。来自由认知科学。
跟问答系统相关的自然语言处理技术:分词与词性标注,命名实体识别,文本摘要、文本分类、文本聚类、语言浅层分析,问句分析,问句与答案匹配及排序。
文本分类应用在:用户问句,后台的文档,在信息检索过程中只选择用户问句分类与后台文档分类匹配的文档,进而提高信息检索的效率。
文本聚类:比如用户查询sh一个输入“苹果”,通过聚类可以把苹果公司的聚到一起、把苹果土特产聚到一起、还有其他的苹果相关行业。
语言浅层分析:
引入模块越多,高精度与高复杂性不可兼容。
哈工大的《问答式信息检索的理论与方法研究》:问答系统涉及到三个层次:用户层、处理层、数据层;
用户层:接受用户输入,结果如何返回用户,语言的分析识别,用户查询记录分析,分门别类、个性化发展方向。
用户层结构如下:
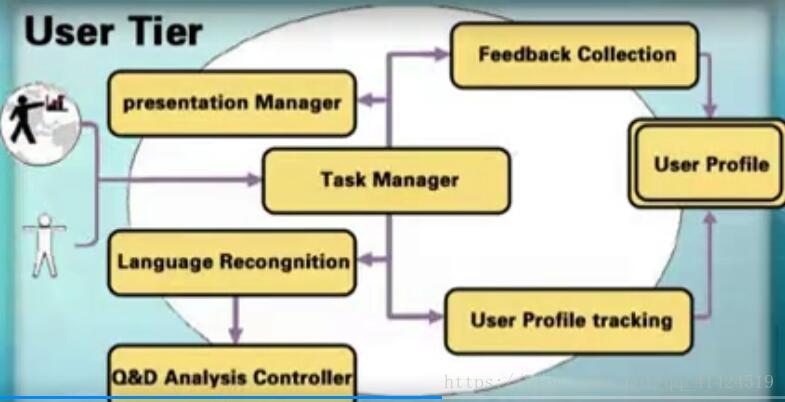
任务调度:最重要,记录用户行为。
语言识别:
输出管理:
反馈信息采集:
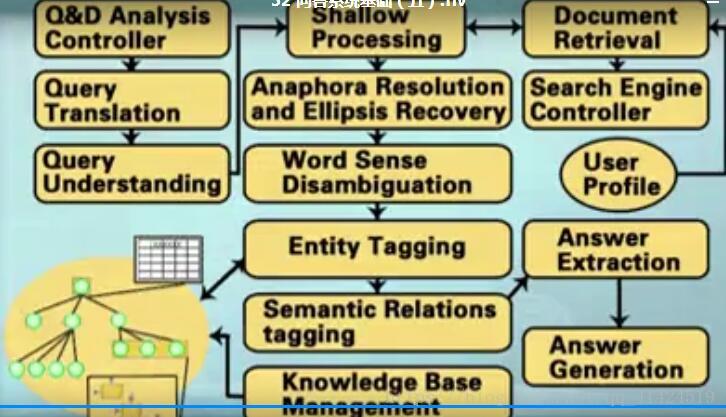
处理层:对用户问句进行分析,语言分析技术、术语关系抽取、答案的抽取与生成。
词义消歧:结合上下文处理。
指代消解:候选文档中的代词找出来对应的实体。成分缺失的补充。
问题理解:
问题翻译:跨语言检索。
用户兴趣追踪:个性化服务,用户兴趣模型建立,根据用户模型来推送信息。
知识库维护:从一个特定领域开始。
处理层结构如下:
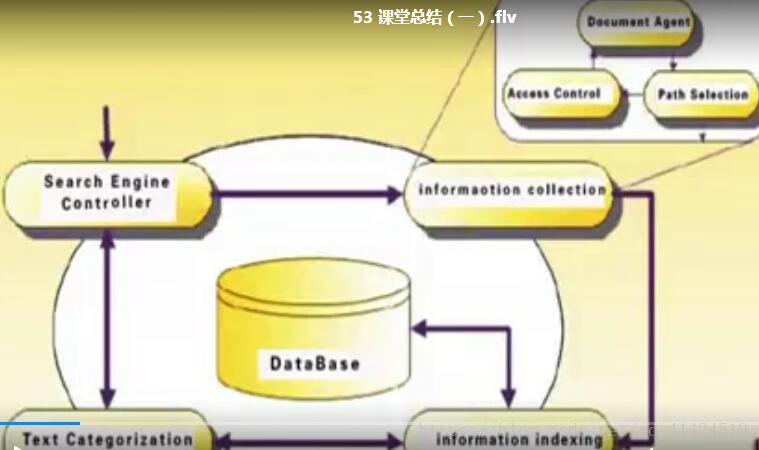
数据层:对网络海量文档的收集、存储,知识库。具体如下:
搜索引擎控制:
信息采集:
文本分类:
信息索引:
数据层结构如下:
特定领域的问答系统:构建专业领域知识库,如何从海量文本中自动构建专业领域知识库。
待续中。。。。。