转自:https://blog.csdn.net/chenyukuai6625/article/details/76922840
一、背景简介
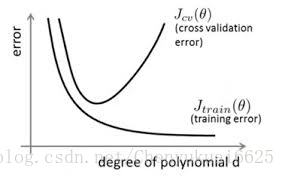
在深度学习和机器学习的各种模型训练过程中,在训练数据不够多时,自己常常会遇到的问题就是过拟合(overfitting),过拟合的意思就是模型过度接近训练的数据,使得模型的泛化能力降低,泛化能力降低表现为模型在训练集上测试的误差很低,但是真正在验证集上测试时却发现error很大,如下图所示。所以此时得到的过拟合的模型不是我们想要的模型,我们需要对模型进行优化,从而提高其泛化性能,使其在测试时模型表现更好。
如今常用的神经网络优化方法(避免过拟合,提高模型泛化性)有以下几种:early stopping、数据集扩增、正则化(Regularization)包括L1、L2(L2 regularization也叫权重衰减),dropout。下面将分别对这几种优化方法进行介绍。
在进行优化方法之前先介绍一下一个知识点,在深度学习的模型训练中,我们用于训练的原始数据集常常分为3部分:训练集(training data)、验证集(validation data)和测试集(testing data)。这三个数据集分别有各自的功能,其中训练集是用于模型的训练的,验证集的作用为确定网络结构或者控制模型复杂程度的参数,测试集是用于评估训练模型的好坏和精确度。
这三个数据集最不好理解的就是验证集,现在我们单独来理解这个数据集的作用。假设建立一个BP神经网络,对于隐含层的节点数目,我们并没有很好的方法去确定。此时,一般将节点数设定为某一具体的值,通过训练集训练出相应的参数后,再由交叉验证集去检测该模型的误差;然后再改变节点数,重复上述过程,直到交叉验证误差最小。此时的节点数可以认为是最优节点数,即该节点数(这个参数)是通过交叉验证集得到的。所以由上面可以发现交叉验证集是用于确定网络结构或者控制模型复杂程度的参数。
二、early stopping
Early stopping方法的具体做法是,在每一个Epoch结束时(一个Epoch集为对所有的训练数据的一轮遍历)计算验证集(validation data)的精确率(accuracy),当accuracy不再提高时,就停止训练,及早的停止训练也可以在一定程度上避免训练模型对于训练数据的过拟合。
我们可以很好理解这种做法,因为当accurary不再提高,再继续训练也是无益的,这只会提高训练的时间。但是现在的问题就是如何评判验证集的精确率不再提高了呢?这里并不是认为validation accuracy一降下来便认为不再提高了,这是因为一个epoch精确率降低了,随后的epoch有可能它又升高上去了。所以在实际中我们不能仅根据一两次的epoch来判定验证集的精确率的变化。这里我们一般采用的方法是多看几个epoch(例如10、20、30等),这种方法也非常好理解,就是当我们经过一定的epoch之后发现验证集精确率还是没有达到最佳,我们就认为精确率不再提高。此时停止迭代(Early Stopping)。这种策略我们也称为“No-improvement-in-n”,n即Epoch的次数,可以设定n为10、20、30等,具体情况具体分析。
三、L2 正则化(权重衰减)
3.1 公式推导说明核心思想
L2正则化所做的改变就是在原代价函数后面加上一个正则化项,如下所示:
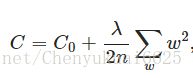
其中C0为原始的代价函数,后面的一项就是L2正则化项,它的值为所有权重w的平方的和除以训练集的样本大小n。λ为正则项系数,用于权衡正则项与C0项的比重。另外还有一个系数1/2,主要是为了后面求导的结果方便,后面那一项求导会产生一个2,与1/2相乘刚好为1。
那么L2正则项是如何避免overfitting的呢?我们可以通过推导来发现原因,对C进行求导得:
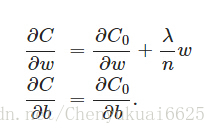
由上图可以发现L2正则项对b的更新没有任何影响,但对于w的更新有些影响,影响如下:
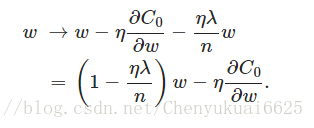
由上图可以发现,当λ=0时即为没有L2正则化情况,但当加入L2正则化时,因为η、λ、n都是正的,所以 1−ηλ/n肯定小于1,所以L2正则化的效果就是减小w,这也就是权重衰减(weight decay)的由来。但是这里需要说明的是权重衰减并不是说权重w会减小,我们这里的权重衰减讲的是相比于没加入L2正则化的情况权重w会减小,在加入L2正则化时,权重w的增加或减小极大程度取决于后面的导数项,所以w最终的值可能增大也可能减小。
现在,我们通过公式推导解释了L2正则化项会有让w“变小”的效果,但是还没解释为什么w“变小”可以防止overfitting?
3.2 权重衰减如何防止overfitting?
一个所谓“显而易见”的解释就是:更小的权值w,从某种意义上说,表示网络的复杂度更低,对数据的拟合刚刚好(这个法则也叫做奥卡姆剃刀),还没达到过拟合,而在实际应用中,也验证了这一点,L2正则化的效果往往好于未经正则化的效果。当然,这个解释没有那么有说服力,没办法直观理解,现在我们通过数学知识来理解这个问题。
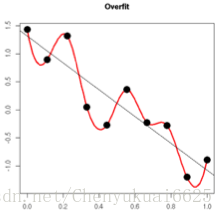
过拟合的时候,拟合函数的系数往往非常大,为什么?如下图所示,过拟合,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。 而正则化是通过约束参数的范数使其不要太大,所以它可以在一定程度上减少过拟合情况。
四、L1正则化
在原始的代价函数后面加上一个L1正则化项,即所有权重w的绝对值的和,乘以λ/n。
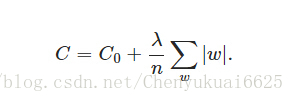
同样先计算导数:
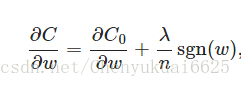
上式中sgn(w)表示w的符号,当w>0时,sgn(w)=1,当w<0时,sgn(w)=-1,sgn(0)=0。那么权重w的更新公式为:
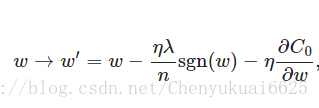
上式比原始的更新规则多出了η * λ * sgn(w)/n这一项。当w为正时,更新后的w变小。当w为负时,更新后的w变大——因此它的效果就是让w往0靠,使网络中的权重尽可能为0,也就相当于减小了网络复杂度,防止过拟合。
五、Dropout
L1、L2正则化是通过修改代价函数来实现的,而Dropout则是通过修改神经网络本身来实现的,它直接使一些神经节点失活,它在训练神经网络模型时常常采用的提高模型泛化性的方法。假设dropout的概率为0.5,我们要训练的神经网络结构如下:

在训练时,我们采用的dropout的方法就是使得上面的某些神经元节点失效,将这些节点视为不存在,网络如下:

保持输入输出层不变,按照BP算法更新上图神经网络中的权值(虚线连接的单元不更新,因为它们被“临时失活”了)。以上就是一次迭代的过程,在第二次迭代中,也用同样的方法,只不过这次失活的那一半隐层单元,跟上一次失活的神经节点是不一样的,因为我们每一次迭代都是“随机”地去失活一半。第三次、第四次……都是这样,直至训练结束。
上面的过程就是Dropout,但是它为什么有助于防止过拟合呢?可以简单地这样解释,运用了dropout的训练过程,相当于训练了很多个只有半数隐层单元的神经网络(以dropout的概率为0.5为例),每一个这样的半数网络,都可以给出一个分类结果,这些结果有的是正确的,有的是错误的。随着训练的进行,大部分半数网络都可以给出正确的分类结果,那么少数的错误分类结果就不会对最终结果造成大的影响。
六、数据集的扩增
数据集在模型训练的时候显得非常重要,没有好的数据没有更多的数据好的模型无从谈起。在深度学习中,更多的训练数据,意味着可以用更深的网络,训练出更好的模型。
我们了解到数据对于模型的重要性,但是数据的获取常常需要耗费更多的人力物力。之前在做图像检测的项目时就干过这件事,特别麻烦,效率特别低。不过在做图像相关的模型时,获取数据还有一个很好的途径,就是在原始数据上做改动,从而可得到更多的数据,做各种变换。如:将原始图片旋转一个小角度;在图像上添加噪声;做一些有弹性的畸变;截取原始图像的一部分。通过这种方式可以在数据集不足的情况下对数据进行扩增,极大的增加数据集。