目录
机器学习主要分为有监督学习和无监督学习。
1 有监督学习
有监督学习可以大致分为两类问题:分类和预测。
1.1 分类问题
对于分类,输出是离散的值。如果,C=2代表二分类问题;如果C>2代表多分类问题,我们也可以用二分类问题去求解多分类问题。这类,我们不妨假设y=f(x)是原始的函数,但是我们对函数f并不知道。所以我们需要去用预测出的y1=f1(x)函数逼近这个真实的函数。而我们总的目标是用新训练数据(训练中没有出现过的数据)去检验检验f1(x)的泛化能力。
对于本书,我们主要是谈论以概率为主的模型,所以我们采用条件概率,当输入为x和训练数据集为D时,输出y输入C中的哪一类的概率最大。这个概率模型的参数我们也可以用MAP去估计。

这里的MAP的大概公式说明如下:
argmax p(y|x) = argmax p(x|y) p(y) / p(x) = argmax p(x|y) p(y)
这里p(x|y)为最大似然,p(y)为先验概率。
对最大似然p(x|y)里面的参数theta估计的一般步骤为:写似然函数;对似然函数取对,并整理;求导数;解似然方程。
分类问题在实际中得到应用特别多,可以用在文件分类、垃圾邮件的过滤、花朵的分类(这里是以鸢尾花为例,从这个例子中我们还可以知道,特征工程对整个机器学习系统的一个重要性,因为方法几乎都是差不多的,能差别比较大的就是输入数据特征分布,不同的数据特征分布对机器学习的结果影响是比较大的)、图片识别(手写体识别)、人脸定位和识别。
1.2 回归问题
回归问题和分类问题特别像,不同的是输出是连续的值。回归问题常见的应用有股市价格预测、YouTube用户年龄的预测、在某种药物下体内某种抗原的数量、室外温度的预测等。
2 无监督学习
无监督学习和监督学习有两点区别:用p(x|theta)替代了p(y|x,theta),所以监督学习是条件概率密度,无监督学习是非条件学习概率密度;x是特征向量,所以我们需要创建多变量概率模型。其实,在现实生活中无监督学习更常见,比如我们出生牙牙学语,父母有监督地纠正我们的错误,到后来我们拥有一定的学习能力,会自动地无监督学习新的事物。在机器学习里面,那些标签的数据其实也是人工标注的,这会导致需要的代价特别高,标注的少量标签包含的信息量可能会特别少。
关于无监督学习的例子有以下几个:
2.1 发现类别
假设类别有K类,在监督学习中,K的值是确定的。在无监督学习中,K的值是根据我们自己的喜好去确定。这里,我们把不同的类别分别建立不同的模型,从而比较在哪一个模型中该类别的概率最大。
应用:行星的发现、根据用户上网习惯的分类、发现新的细胞。
2.2 发现隐含因子
当我们处理高维数据的时候,比较有效的方法是减低维数,因为低维里面,我们更容易捕获都那些潜在的有效因子。

比如这里我们将三维的数据降维到二维,很明显二维的效果要好很多,因为大多数点都聚集在一个平面上面,如果我们再降维降至一维,那么大多数点会到这个红线上面,会更加的线性。
降维的优点:让我们的模型能够更加集中火力处理输入的数据(此时是低维,因为低维里面有用信息的“浓度”会更高);低维的特征也能够快速的最近近邻搜寻,这样能够节省时间;便于数据的可视化。
3 机器学习中的基本概念
3.1 参数和非参数模型
参数模型有很多参数,并且随着数据的增加,参数是会发生变化的。它比非参数模型能够更快地使用,但是它把数据的分布假设给强行假设,固定死了。相当于参数模型,非参数模型就比较的灵活,但是计算量要稍微大一点。
非参数模型---K近邻算法

目标点到其他点之间的距离一般是用欧氏距离去度量。下面是几种距离公式的说明:
两个n维变量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的闵可夫斯基距离定义为:

其中p是一个变参数:当p=1时,就是曼哈顿距离;当p=2时,就是欧氏距离;当p→∞时,就是切比雪夫距离。因此,根据变参数的不同,闵氏距离可以表示某一类/种的距离。
3.2 维度灾难
维数灾难(Curse of Dimensionality):通常是指在涉及到向量的计算的问题中,随着维数的增加,计算量呈指数倍增长的一种现象。维数灾难涉及数字分析、抽样、组合、机器学习、数据挖掘和数据库等诸多领域。对于维度灾难问题,我们这里以KNN为例,一般来说输入特征维度为2维,KNN算法的效果是最好的。但是随着输入维数的增加,KNN的计算量会增大,如果K→∞时,这个模型效果会特别差,甚至不能够去工作。
哪些问题会面临维度灾难问题呢?
贝叶斯统计:在贝叶斯统计中维数灾难通常是一个难点,因为其后验分布通常都包含着许多参数。然而,这一问题在基于模拟的贝叶斯推理(尤其是适应于很多实践问题的马尔科夫蒙特卡洛方法)出现后得到极大地克服。当然,基于模拟的方法收敛很慢,因此这也并不是解决高维问题的灵丹妙药。
距离函数
最近邻查询:当维数趋于极限值时,查询点到数据集中所有点的距离都相等,此时最近邻已经没有意义,也称为最近邻查询的不稳定性。
动态规划问题:即指的是动态规划问题各阶段上状态变量的维数。当状态变量的维数增加时,动态规划问题的计算量会呈指数倍增长,限制了人们用动态规划研究问题和解决问题的能力。
模式识别:根据模式识别理论,低维空间线性不可分的模式通过非线性映射到高维特征空间则可能实现线性可分,但是如果直接采用这种技术在高维空间进行分类或回归,则存在确定非线性映射函数的形式和参数、特征空间维数等问题,而最大的障碍则是在高维特征空间运算时存在的“维数灾难”。即维数越高,计算量越大。
解决方法
1 特征抽取
基于低维投影的降维:主要包括主成分分析( Principal Component Analysis, PCA) 方法和投影寻踪 ( Projection Pursuit,PP) 方法;
基于神经网络的降维:主要包括自动编码网络、自组织映射网络和生成建模;
基于数据间相似度的降维:主要包括多维尺度、随机邻居嵌入、Isomap、局部线性嵌入和拉普拉斯特征映射;
2 特征选择
主要分为三大类:一类属于“过滤”的(filter)方法,另一类属于“包裹”的方法,还有通过范数进行特征选择的方法。
3 采用核函数技术可以有效地解决“维数灾难”。
3.3 线性回归和logistics回归
这里,我们就只做一个简单的比较,因为本书的后面第7、8章会讲,到时候再详细说。

Logistics需要通过sigmoid函数,线性回归直接通过线性函数,对于损失函数,两者也是不同的。
3.4 过拟合
这里书上对过拟合说得不详细,我又查阅了其他资料。
导致过拟合的原因如下:
(1)建模样本选取有误,如样本数量太少,选样方法错误,样本标签错误等,导致选取的样本数据不足以代表预定的分类规则;
(2)样本噪音干扰过大,使得机器将部分噪音认为是特征从而扰乱了预设的分类规则;
(3)假设的模型无法合理存在,或者说是假设成立的条件实际并不成立;
(4)参数太多,模型复杂度过高;
(5)对于决策树模型,如果我们对于其生长没有合理的限制,其自由生长有可能使节点只包含单纯的事件数据(event)或非事件数据(no event),使其虽然可以完美匹配(拟合)训练数据,但是无法适应其他数据集。
(6)对于神经网络模型:a)对样本数据可能存在分类决策面不唯一,随着学习的进行,BP算法使权值可能收敛过于复杂的决策面;b)权值学习迭代次数足够多(Overtraining),拟合了训练数据中的噪声和训练样例中没有代表性的特征。
解决方案
(1)在神经网络模型中,可使用权值衰减的方法,即每次迭代过程中以某个小因子降低每个权值。
(2)选取合适的停止训练标准,使对机器的训练在合适的程度;
(3)保留验证数据集,对训练成果进行验证;
(4)获取额外数据进行交叉验证;
(5)正则化,即在进行目标函数或代价函数优化时,在目标函数或代价函数后面加上一个正则项,一般有L1正则与L2正则等。
3.5 模型的选择
我们用训练集去对模型进行训练,不能用测试集对模型去进行选择,因为我们并不知道测试集的标签。这里,我们将训练集分成两块,一块是训练集,另一块是验证集。
对于验证集的作用:一是可以用在训练的过程中,一般在训练时,几个epoch结束后跑一次验证集看看效果。(验证得太频繁会影响训练速度)这样做的第一个好处是,可以及时发现模型或者参数的问题,比如模型在验证集上发散、出现很奇怪的结果 (如无穷大)、MAP不增长或者增长很慢等等情况,这时可以及时终止训练,重新调参或者调整模型,而不需要等到训练结束。另外一个好处是验证模型的泛化能力,如果在验证集上的效果比训练集上差很多,就该考虑模型是否过拟合了。同时,还可以通过验证集对比不同的模型。
一般我们将80%的数据作为训练数据,20%的数据作为验证数据,但是在实际中,往往没有足够的数据去训练。我们可以采用K折交叉验证。当K等于样例数时,叫做留一法;当K=10时,叫做十折交叉验证。
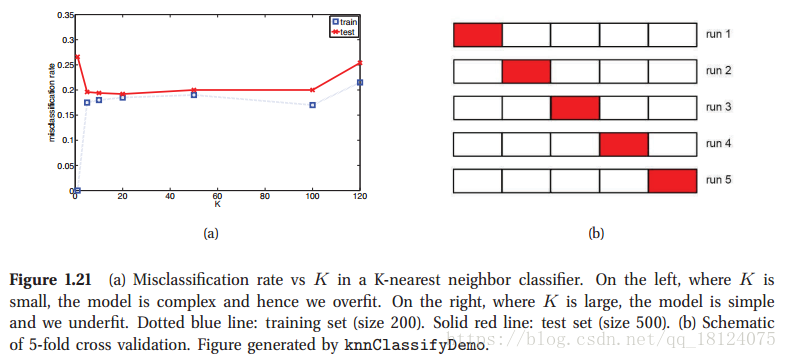
3.6 定理
奥卡姆剃刀:如无必要,勿增实体
丑小鸭定理:所以的特征都是相等重要
没有免费的午餐:若学习算法La在某些问题上比学习算法Lb要好,那么必然存在另一些问题,在这些问题中Lb比La表现更好。