版权声明:本文为博主原创文章,如若转载请注明出处 https://blog.csdn.net/tonydz0523/article/details/86631664
长租公寓算是国内正在规范化的一个产业,其中比较正规的比较大的有某如、某壳,想要对长租公寓行业做一些简单的数据分析,于是乎爬虫搞起来,柿子挑软的捏:从某壳下手。
爬虫策略
说实话,某壳的数据挺好爬的,没有比较变态的反爬措施(某如有:价格是图片,不过也好解决,下一篇写哈),只要不是频繁请求的话应该就没事儿(我都是sleep1秒以上的,反正就爬一次而已),本人不支持暴力爬取,动不动就多线程、多进程、代理都搞上了,没意思。。。其实还是数据量小,哈哈
- 我们爬取的是北京的房源,其他地区不在范围
- 公寓公司的找房策略就是围绕着地铁站进行的,因此爬取策略也是围绕地铁站,首先爬取各个地铁站的链接

- 翻页策略:进入地铁站页面后,有下图的页面选择,我们可以获取最大数字,然后生成链接;或者直接获取一下页链接。我选用的方式是后者
- 使用BeautifulSoup对页面进行分析,然后爬取数据
- 设置爬取间隔,1~2秒,随机选取
- 爬取数据存入mongodb
- 地铁链接存入redis,以取出爬取的方式以支持断点续爬
爬虫实践
获取各个地铁站的链接存入redis
地铁站数据情况:
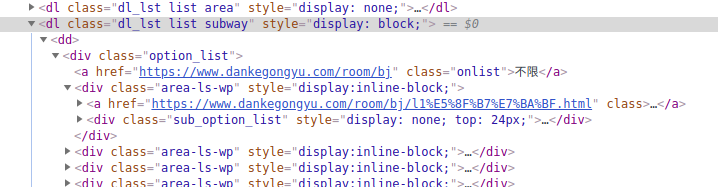
- 首先获取各个地铁线路:
class为dl_lst list subway的dl标签下所有,class为area-ls-wp的div标签 - 循环各地铁线路,链接在
class为sub_option_list的div标签下的a标签中的href
详细代码如下:
# 获取城市地点和网站链接
def get_locations(rds):
url = 'https://www.dankegongyu.com/room/bj/d%E6%B5%B7%E6%B7%80%E5%8C%BA-b%E4%BA%94%E9%81%93%E5%8F%A3.html'
responese = requests.get(url=url, headers=headers)
soup = BeautifulSoup(responese.text, 'lxml')
locations = soup.find('dl', class_='dl_lst list subway').find_all('div', class_='area-ls-wp')
# 获取地区的url
for location in locations:
all_hrefs = location.find('div', class_='sub_option_list').find_all('a')
for href in all_hrefs:
key = href.text.strip()
rds.hset('danke_hash', key, href['href']) #把地铁站和链接以使用hash存储
rds.rpush('danke_name', key) #存储地铁站入redis列表
获取详细信息
网页上的详细信息:

要获取的数据如下:
house_head = ['location', 'community', 'type', 'url', 'area', 'floor', 'face', 'the_way', 'new_price', 'price', 'tags', 'distance_subway']
地铁站、小区、房源构造(如三室一厅)、链接、面积、楼层、朝向、是否合租、价格优惠、价格、标签、距离地铁距离
详细的不写了直接看代码把,代码如下:
# 获取每个地区的租房信息
def get_info(url, client):
while True:
responese = requests.get(url=url, headers=headers)
soup = BeautifulSoup(responese.text, 'lxml')
if soup.find('div', class_='r_ls_box'):
houses = soup.find('div', class_='r_ls_box').find_all('div', class_='r_lbx')
for house in houses:
xiaoqu = house.find('div', class_='r_lbx_cena').find('a')
house_url = xiaoqu['href']
house_info = list(filter(None, xiaoqu['title'].split(' '))) #空格分割并去除列表中的空值
house_info.append(house_url)
size = house.find('div', class_='r_lbx_cenb').get_text(strip=True)
size_list = [x.strip() for x in size.split('|')]
house_info.extend(size_list[:2])
house_info.append(size_list[-1][:-1])
house_info.append(size_list[-1][-1])
if house.find('div', class_='room_price'):
new_price = re.sub('[ \n]', '', house.find('div', class_='new-price-link').get_text(strip=True))[
:-2]
house_price = house.find('div', class_='room_price').get_text()
else:
new_price = ''
house_price = house.find('div', class_='r_lbx_moneya').get_text()
house_info.append(new_price)
price = ''.join(list(filter(str.isdigit, house_price))) #字符串只保留数字为住房价格
house_info.append(price)
tags = house.find('div', class_='r_lbx_cenc').get_text('\n', strip=True).split('\n')
house_info.append(tags)
distance_subway = house.find('div', class_='r_lbx_cena').get_text(strip=True).split("站")[-1][:-1]
print(distance_subway)
house_info.append(distance_subway)
total = {}
for i, info in enumerate(house_info):
total[house_head[i]] = info
save_to_mongo(total, client)
print('成功存入mongo:{}'.format(total))
time.sleep(random.choice([1, 1.5, 2]))
pages = soup.find('div', class_='page').find_all('a')
if pages[-1].get_text(strip=True) == '>': # 判断是否有下一页
url = pages[-1]['href']
else:
break
else:
break
由于只用一次就没写啥备注,完整代码在这。