版权声明:本文为博主原创文章,如若转载请注明出处 https://blog.csdn.net/tonydz0523/article/details/86632857
爬虫策略
某如的数据爬取策略其实跟某壳的差不多,就不多说了,可以看看那篇:https://blog.csdn.net/tonydz0523/article/details/86631664
某如的价格是图片格式,不能正常获取,这里我们着重讲它的价格信息获取策略。。。。。
- 为了与某壳数据做对比,我们只爬取友家类型房源数据
- 某如的数据和某壳的数据有个不同点就是,它的临近地铁不是只有一个是周边多个地铁站点,所以爬取的数据好多是重复的,之后处理就好
- 价格信息为图片:图片地址在
JavaScript代码中能找到,把图片下载下来使用tesseract进行图片识别(其实也就20张而已,把图片信息存入redis,直接匹配)
如下图,价格数据为图片格式:
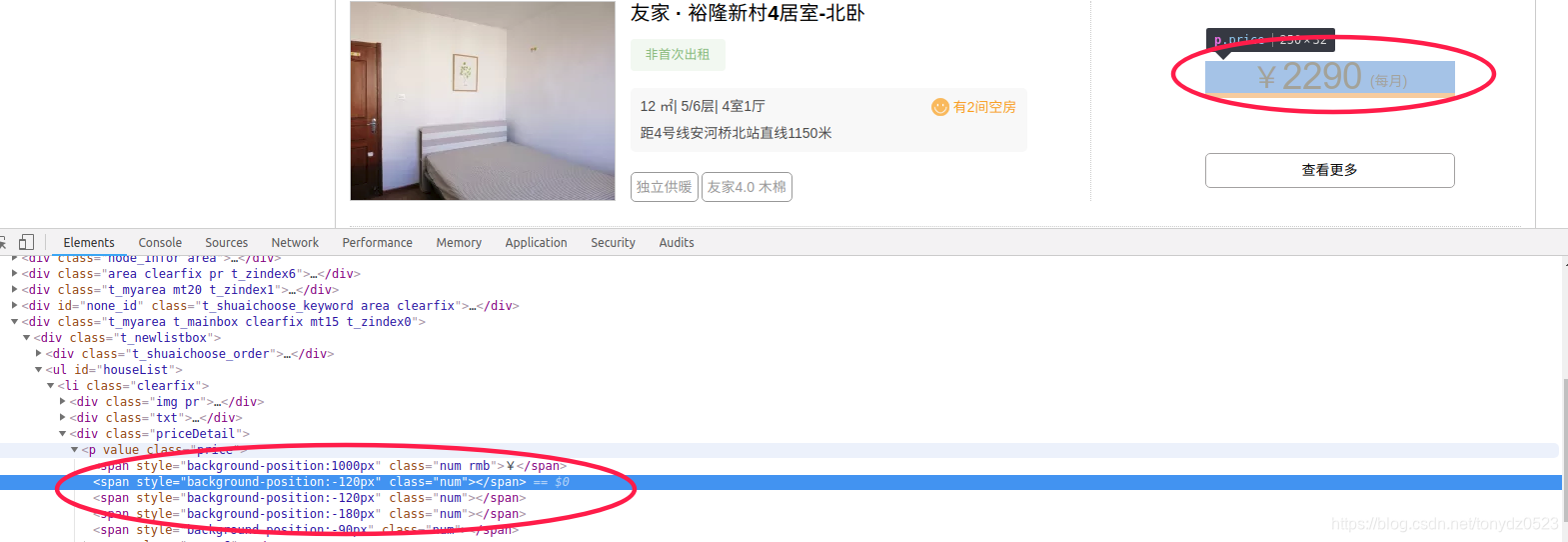
图片链接在JavaScript代码中:

offset中内容是图片对应位置的数字。
使用re,获取图片链接和offset:
re.findall(r'var ROOM_PRICE = {"image":"(.*?)","offset":(.*?)};', resp.text):
使用tesseract获取图片上数字信息:
# 获取图片上的数字
def pic2code(url):
pic_name = 'price1.png'
request.urlretrieve(url, pic_name)
img = Image.open(pic_name)
im = img.convert("L")
im_new = Image.new(im.mode, (340, 70), "black") # 创建新的背景使图片有留白便于识别
im_new.paste(im, (20, 20))
code = pytesseract.image_to_string(im_new) # 使用tesseract进行数字识别
return code
获取的链接和对应数字排序存入redis数据库:
price_url = "http:"+m[0][0]
# 判断价格图片是否已经有识别过了,识别过了的直接使用即可
if r.hget('ziru_price', price_url):
code = r.hget('ziru_price', price_url)
else:
code = pic2code(price_url)
rds.hset('ziru_price', price_url, code)
根据offset数据获取价格:
price_list = eval(m[0][1])
price = ''.join(list(code[j] for j in price_list[i]))