垃圾邮件分析是一个用来快速了解MLlib的例子。这个程序用了两个函数:HashingTF与LogisticRegressionWithSGD,前者从文本数据构建词频(termfrequency)特征向量,后者使用随机梯度下降法实现逻辑回归。
机器学习算法尝试根据训练数据(training data)使得表示算法行为的数学目标最大化,并 以此来进行预测或作出决定。机器学习问题分为几种,包括分类、回归、聚类,每种都有 不一样的目标。拿分类(classification)作为一个简单的例子:分类是基于已经被标记的其 他数据点(比如一些已经分别被标记为垃圾邮件或非垃圾邮件的邮件)作为例子来识别一 个数据点属于几个类别中的哪一种(比如判断一封邮件是不是垃圾邮件)。
所有的学习算法都需要定义每个数据点的特征(feature)集,也就是传给学习函数的值。 举个例子,对于一封邮件来说,一些特征可能包括其来源服务器、提到 free 这个单词的次 数、字体颜色等。在很多情况下,正确地定义特征才是机器学习中最有挑战性的部分。例 如,在产品推荐的任务中,仅仅加上一个额外的特征(例如我们意识到推荐给用户的书籍 可能也取决于用户看过的电影),就有可能极大地改进结果。
大多数算法都只是专为数值特征(具体来说,就是一个代表各个特征值的数字向量)定义 的,因此提取特征并转化为特征向量是机器学习过程中很重要的一步。例如,在文本分类 中(比如垃圾邮件和非垃圾邮件的例子),有好几个提取文本特征的方法,比如对各个单 词出现的频率进行计数。
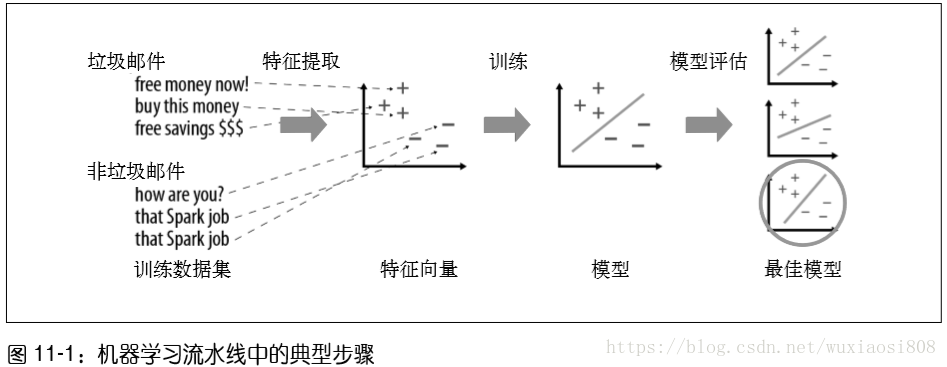
当数据已经成为特征向量的形式后,大多数机器学习算法都会根据这些向量优化一个定义 好的数学函数。例如,某个分类算法可能会在特征向量的空间中定义出一个平面,使得这 个平面能“最好”地分隔垃圾邮件和非垃圾邮件。这里需要为“最好”给出定义(比如大 多数数据点都被这个平面正确分类)。算法会在运行结束时返回一个代表学习决定的模型 (比如这个选中的平面),而这个模型就可以用来对新的点进行预测(例如根据新邮件的特 征向量在平面的哪一边来决定它是不是垃圾邮件)。图 11-1 展示了一个机器学习流水线的 示例。
#spark快速大数据分析 第11章
#垃圾邮件分类
# -*- coding:utf-8 -*-
# import sys
# reload(sys)
# sys.getdefaultencoding("utf8")
from pyspark.mllib.regression import LabeledPoint
from pyspark.mllib.feature import HashingTF
from pyspark.mllib.classification import LogisticRegressionWithSGD
from pyspark import SparkContext,SparkConf
conf = SparkConf().setAppName("local").setAppName("MY APP")
sc=SparkContext(conf=conf)
spam = sc.textFile('spam.txt')
normal = sc.textFile("ham.txt")
#创建一个HashingTF实例来把邮件文件映射为包含10000个特征的向量
tf = HashingTF(numFeatures=100000)
#各个邮件都被切分为单词,每个单词被映射为一个特征
spamFeatures = spam.map(lambda email : tf.transform(email.split(" ")))
normalFeatures = normal.map(lambda email:tf.transform(email.split(" ")))
#创建LabeledPoint数据集分别存放阳性(垃圾邮件)和阴性(正常邮件)的例子
positiveExamples = spamFeatures.map(lambda features:LabeledPoint(1,features))
negativeExamples = normalFeatures.map(lambda features:LabeledPoint(0,features))
trainingData = positiveExamples.union(negativeExamples)
trainingData.cache() #因为逻辑回归是迭代算法,所有换成训练数据RDD
#使用SGD算法运行逻辑回归
model = LogisticRegressionWithSGD.train(trainingData)
#以阳性和阴性的例子分别进行测试。首先使用一样的HashingTF特征来得到特征向量,然后对该向量应用到模型
postTest = tf.transform("O M G GET cheap stuff by sending money to ..".split(" "))
negTest = tf.transform("Hi Dad,I started studying Spark the other ...".split(" "))
print("Prediction for positive test example:%g" % model.predict(postTest))
print("Prediction for negative test example:%g" % model.predict(negTest))