spark下载与入门
spark shell
其他shell工具只能使用单机的硬盘和内存来操作数据,而spark shell可以用来与分布式存储在许多机器的内存或者硬盘上的数据进行交互,并且处理过程的分发由spark自动控制完成。
spark支持许多语言版本,此处交互式shell部分只考虑Python版本(PySpark Shell)和Scala版本(Spark-sehll)。
- 进入PySpark Shell:
进入spark目录后,输入bin/pyspark
- 进入spark-shell:
进入spark目录后,输入bin/spark-sehll
两种方式对比如下图(上图Scala下图Python):
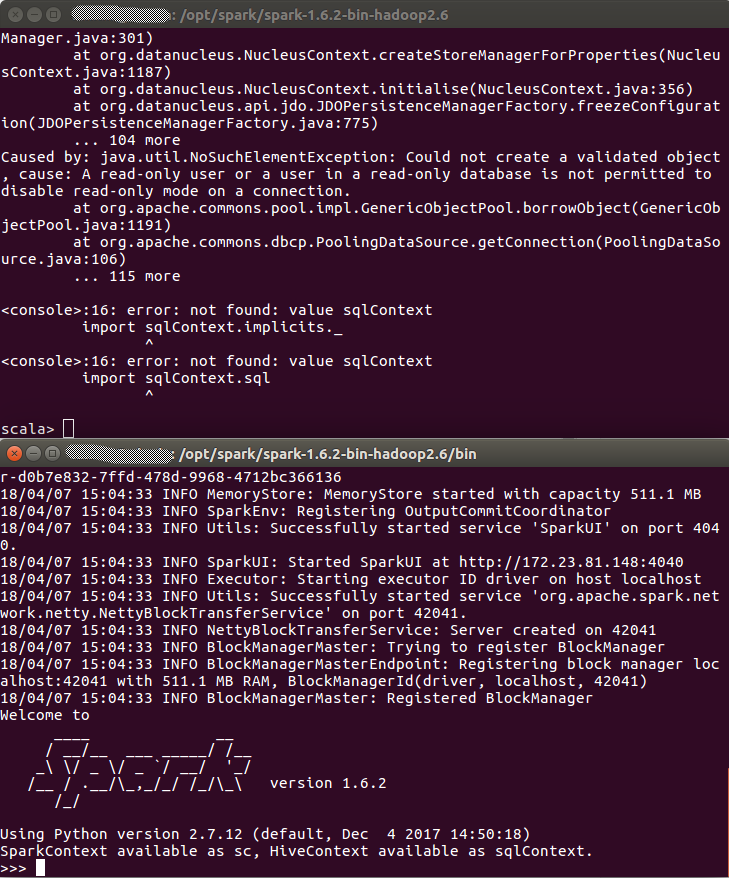
这里可以看到对比,即使没有赋予管理员权限,pyspark依旧可以获取SparkContext,而Scala则不行。
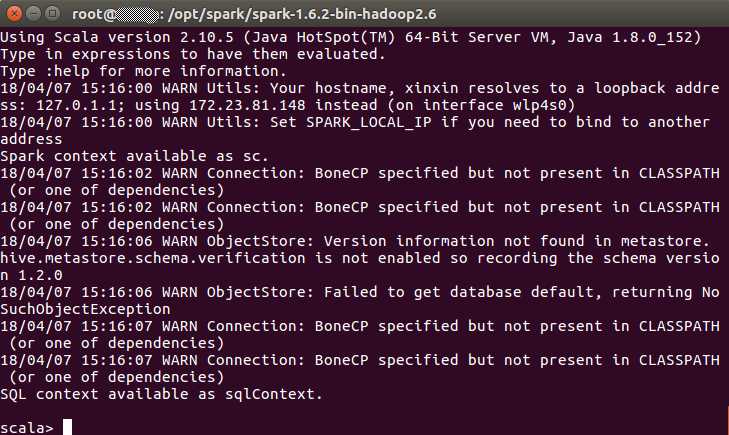
在执行命令行sudo -s后,即以管理员身份运行bin/spark-shell,则Scala可以正常使用SparkContext,如下图示:
————————————
减少shell中输出的日志信息,使之只显示警告及更严重的信息:
在conf目录下创建名为log4j.properties的文件,拷贝spark开发者在spark中加入的日志设置文件模板:log4j.properties.template。找到下面这行:
log4j.rootCategory=INFO, console
改成:
log4j.rootCategory=WARN, console
——————————————
spark中的分布式数据集成为弹性分布式数据集(resilient distributed dataset,RDD)。
lines = sc.textFile("README.md")即为创建一个名为lines的RDD,是从电脑上的一个本地文本文件创建出来的。
——————————————
每个spark应用都由一个驱动器程序(driver program)来发起集群上的各种并行操作。前面的例子里,驱动器程序就是spark shell本身,只需要输入运行的操作即可。
驱动器程序通过一个SparkContext对象来访问Spark,这个对象代表对计算集群的一个连接。shell启动时已经自动创建了一个SparkContext对象,是一个叫做sc的变量。一旦有了SparkContext,可以用它来创建RDD。比如用lines=sc.textFile()来创建一个代表文件中各行文本的RDD,可以在可以在行上进行各种操作,比如lines.count()。
要执行这些操作,驱动器程序一般要管理多个执行器(executor)节点。比如要在集群上运行count()操作,那么不同的节点会统计文件的不同部分的行数。
有很多用来传递函数的API(application program interface应用程序编程接口),可以将对应操作运行在集群上。比如说lines.filter()等等。
————————————————
除了Spark shell这种交互式运行方式外,还可以在独立程序中使用Spark。与shell的区别是需要自己初始化SparkContext,接下来,使用的API是一样的。
连接Spark:
Java和Scala中,只需要给应用添加一个对于spark-core工件的Maven(流行的包管理工具,可以用于任何基于Java的语言,让你可以连接公共仓库中的程序库)依赖。可以使用Maven来构建工程,也可以使用其他能够访问Maven仓库的工具来进行构建,包括Scala的sbt工具或者Gradle工具。一些常用的集成开发环境(比如eclipse)也可以让你直接把Maven依赖添加到工程中。
python中,可以把应用写成python脚本,但是需要另一个自带脚本来运行,来引入python程序中的spark依赖,它为spark的pythonAPI配置好了运行环境。
bin/spark-submit my_script.py
初始化spark:
连接spark后,需要在程序中导入spark包并且创建SparkContext。可以先创建SparkConf对象来配置应用,然后基于它创建SparkContext对象。参数local表示Spark运行在单机单线程上。参数my app可以帮你在集群管理器的用户界面中找到你的应用。