版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_33689414/article/details/86240341
Structured Streaming入门实例
Structured Streaming是Spark2.4版本推出的新的实时流处理计算。相比Spark Streaming具有更低的延迟。
具体信息请看:Structured Streaming官方介绍
示例一:words count
- Scala代码
package com.test
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
object WordCount {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
val spark = SparkSession.builder()
.master("local")
.appName("WordCount")
.getOrCreate()
// 读取socket流数据,监听端口9998
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", "9998")
.load()
// 隐式转换
import spark.implicits._
// 将一行数据进行空格分割后打平
val words = lines.as[String].flatMap(_.split(" "))
// 根据value进行groupby,计算出count
val wordCounts = words.groupBy("value").count()
// 将流数据写入console控制台
val query = wordCounts
.writeStream
.format("console")
.outputMode("complete")
.start()
// 将进程阻塞
query.awaitTermination()
}
}
- nc -lk 9998进行传输数据

- WordCount代码结果输出

这里解释下:outputMode
outputMode输出模式分为3种:append,complete,update。
- append:只有流数据中的新行将写入sink
- complete:每次有更新时,流数据中的所有行都将写入sink
- update:每次有更新时,只有流数据中更新的行要写入sink。如果查询没有包含聚合,相当于“append”模式。
示例二:WordCount Append模式
object WordCountAppend {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
val spark = SparkSession
.builder()
.master("local")
.appName("WordCountAppend")
.getOrCreate()
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", "9998")
.load()
val query = lines.writeStream
.format("console")
.outputMode("append")
.start()
query.awaitTermination()
}
}
自己体验一把就行
示例三:读取csv/json文件
package com.test
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types.{StringType, StructField, StructType}
object CSVFormat {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
val spark = SparkSession
.builder()
.master("local")
.appName("CSVFormat")
.getOrCreate()
// 定义schema
val schema = StructType(
List(
StructField("name", StringType),
StructField("age", StringType),
StructField("sex", StringType)
)
)
val lines = spark.readStream
.format("csv")
.schema(schema)
.load("/Users/zhangzhiqiang/Documents/test_project/comtest/data")
val query = lines.writeStream
.format("console")
.outputMode("append")
.start()
query.awaitTermination()
}
}
在/Users/zhangzhiqiang/Documents/test_project/comtest/data目录下存放一些csv文件,或者逐步放入csv文件,可以看到界面实时的输出csv文件的内容。
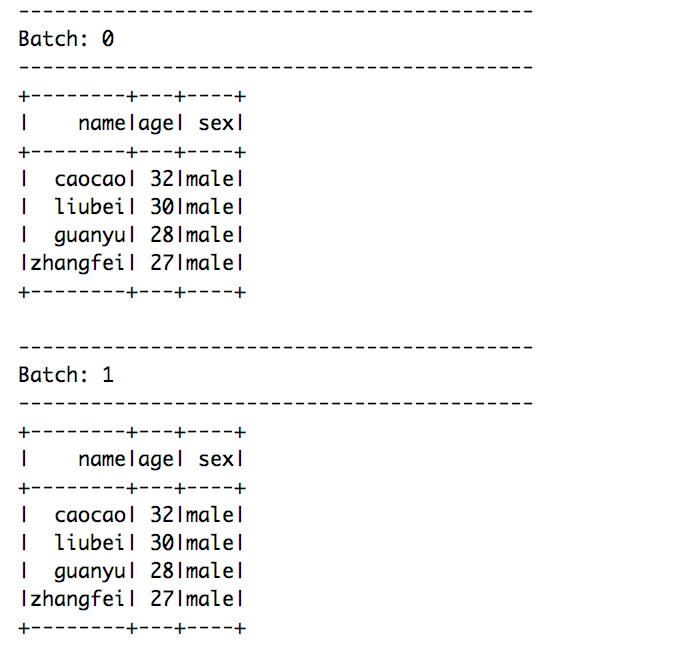
上图是,我将data目录下的文件复制了一份产生的。
示例四:kafka流数据读取
package com.test
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
object KafkaFormat {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.apache.kafka").setLevel(Level.WARN)
val spark = SparkSession
.builder()
.master("local")
.appName("KafkaFormat")
.getOrCreate()
// 读取kafka的数据
val df = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "test")
.load()
// 隐式转换
import spark.implicits._
// 截取 key,value 2个字段
val lines = df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
val res = lines.map { line =>
// 解析value的值
val columns = line._2.split(",")
(columns(0), columns(1), columns(2))
}.toDF()
res.createOrReplaceTempView("tmp")
val result = spark.sql("select _1 as name, _2 as age , _3 as sex from tmp")
val query = result.writeStream
.format("console")
.outputMode("append")
.start()
query.awaitTermination()
}
}
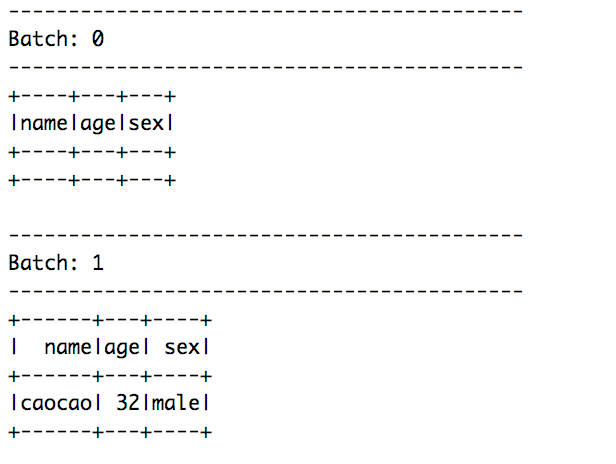
启动kafka生成器命令行,sh kafka-console-producer.sh --broker-list localhost:9092 --topic test,向命令行写入caocao,32,male。
可以看到console的信息,如下图:
示例五:解析kafka的json数据
package com.test
import com.google.gson.Gson
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
object KafkaFormatJson {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.apache.kafka").setLevel(Level.WARN)
val spark = SparkSession.builder()
.master("local")
.appName("KafkaFormatJson")
.getOrCreate()
// 读取kafka流数据
val lines = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "test")
.load()
// 隐式转换
import spark.implicits._
val values = lines.selectExpr("CAST(value AS STRING)").as[String]
val res = values.map { value =>
// 解析json逻辑
val gson = new Gson
val people = gson.fromJson(value, classOf[People])
(people.name, people.age, people.sex)
}
res.createOrReplaceTempView("tmp")
// spark sql
val result = spark.sql("select _1 as name, _2 as age, _3 as sex from tmp")
// 写入
val query = result.writeStream
.format("console")
.outputMode("append")
.start()
query.awaitTermination()
}
}
People类
package com.test
case class People(name: String, age: String, sex: String) extends Serializable
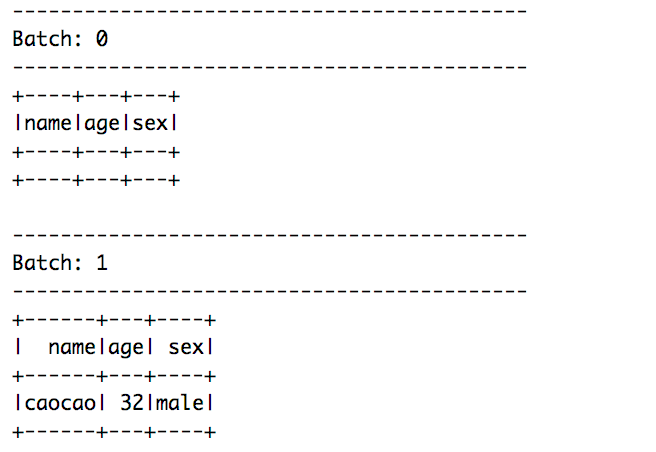
启动程序,在kafka生成器命令行,输入{"name":"caocao","age":"32","sex":"male"}数据。可以看到console的信息,如下:
github代码:structuredstreamngdemo项目