简介: Structured Streaming是Apache Spark2016年启动的项目,一个基于SparkSQL的全新的流处理引擎,致力于提供批流统一的高性能API
1. Structured Streaming的概述
对比SparkStreaming :
- Spark Streaming基于RDD开发,使用DStream API来编程,编程难度大.
- Spark Streaing 的主要模型是微批次(Micro Batch),将数据流按照相等时间间隔(BatchLerval)切分成小任务来执行.
- Structured Streaming 用户可以使用Dataset/DataFrame 或者 SQL 来对这个动态数据源进行实时查询。
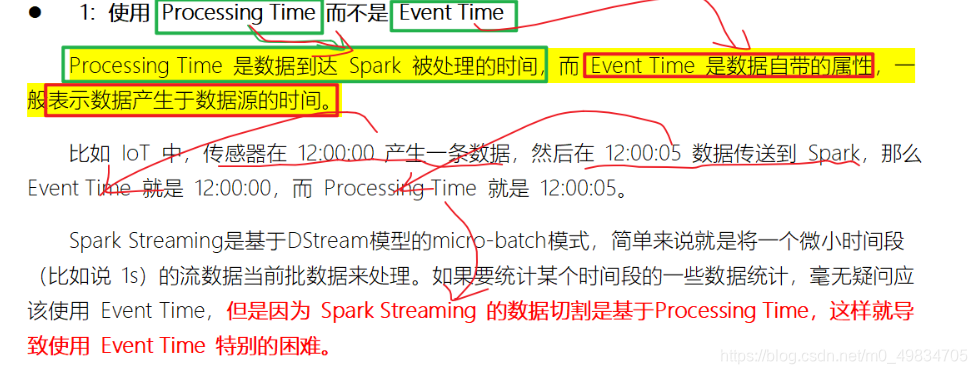
Spark Streaming的不足:
-
处理的是数据处理的时间而不是数据到来的时间
-
编程复杂

-
没有实现端到端一致性

-
批流代码不统一

Structured Streaming 的有什么优势?
缺点: 结构化流2.0以后出来的,限制比较多
优点:
- Incremental query model(增量查询模型)

- Support for end-to-end application(支持端到端一致性)

- 复用 Spark SQL 执行引擎

2. Structured Streaming的编程模型
简介:
- Structured Streaming将流式数据当成一个不断增长的table,然后使用和批处理同一套API,都是基于DataSet/DataFrame的
- 核心思想: 将实时到达的数据看作是一个不断追加的unbound table无界表,到达流的每个数据项(RDD)就像是表中的一个新行被附加到无边界的表中.(引出了可以用批处理SQL的方式来对数据进行实时查询)
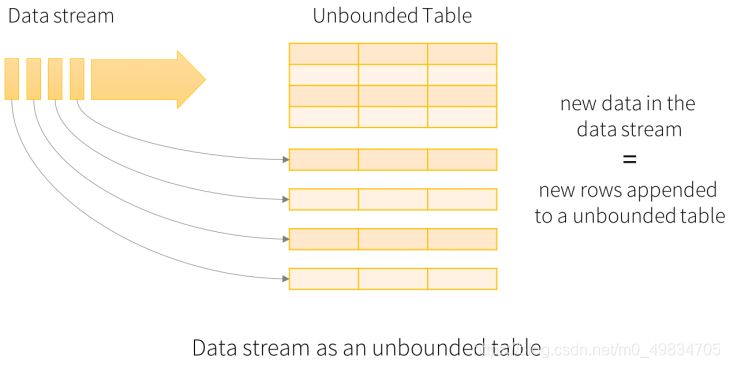
模型组成:
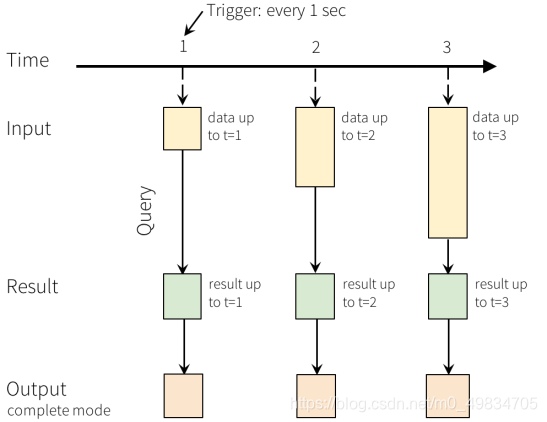
1:Input Table(Unbounded Table),流式数据的抽象表示,没有限制边界的,表的数据源源不断增加;
2:Query(查询),对 Input Table 的增量式查询,只要Input Table中有数据,立即(默认情况)执行查询分析操作,然后进行输出(类似SparkStreaming中微批处理);
3:Result Table,Query 产生的结果表;
4:Output,Result Table 的输出,依据设置的输出模式OutputMode输出结果;
3. Structured Streaming的数据源结构
数据源源码:
val spark = SparkSession
.builder
.master("local[2]")
.appName("StructuredNetworkWordCount")
.config("spark.sql.shuffle.partitions", 1)
.getOrCreate()
// socket为数据源
val lines = spark.readStream
.format("socket")
.option("host", "127.0.0.1")
.option("port", "9003")
.load()
// kafka为数据源
val lines = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "127.0.0.1:9092")
.option("subscribe", "topic1")
.option("maxOffsetsPerTrigger", 10)
.load()
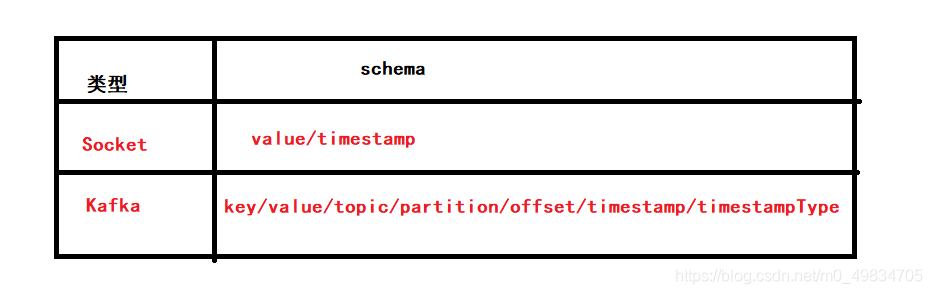
第一个代码段为构建spark session,第二和第三个代码段分别是构建socket数据源及kafka数据源。
这些数据源构建之后带有默认的schema结构。下表就是schema: