什么是XML?
XML代表可扩展标记语言。它旨在存储和传输中小数据量,并广泛用于共享结构化信息。
Python使您能够解析和修改XML文档。为了解析XML文档,您需要将整个XML文档放在内存中。在本教程中,我们将看到如何在Python中使用XML minidom类来加载和解析XML文件。
如何使用minidom解析XML
我们已经创建了一个我们要解析的示例XML文件。
步骤1)在文件内部,我们可以看到名字,姓氏,主页和专业领域(SQL,Python,测试和业务)
步骤2)一旦我们解析了文档,我们将打印出文档根目录的“节点名称”和“ firstchild标记名”。Tagname和nodename是XML文件的标准属性。
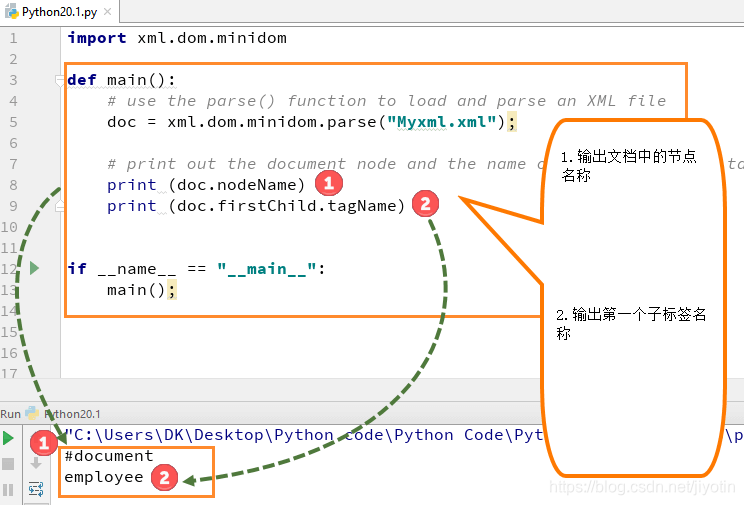
导入xml.dom.minidom模块并声明必须解析的文件(myxml.xml)
此文件包含有关员工的一些基本信息,如名字,姓氏,家庭,专业知识等。
我们使用XML minidom上的parse函数来加载和解析XML文件
我们有变量doc和doc获取解析函数的结果
我们想从文件中打印nodename和child标记名,因此我们在print函数中声明它
运行代码 - 它从XML文件打印出节点名称(#document),从XML文件打印出第一个子标记名(员工)
注意:
Nodename和子标记名是XML dom的标准名称或属性。
步骤3)我们还可以从XML文档中调用XML标记列表,并打印其内容。在这里,我们打印出一系列技能,如SQL,Python,测试和业务。
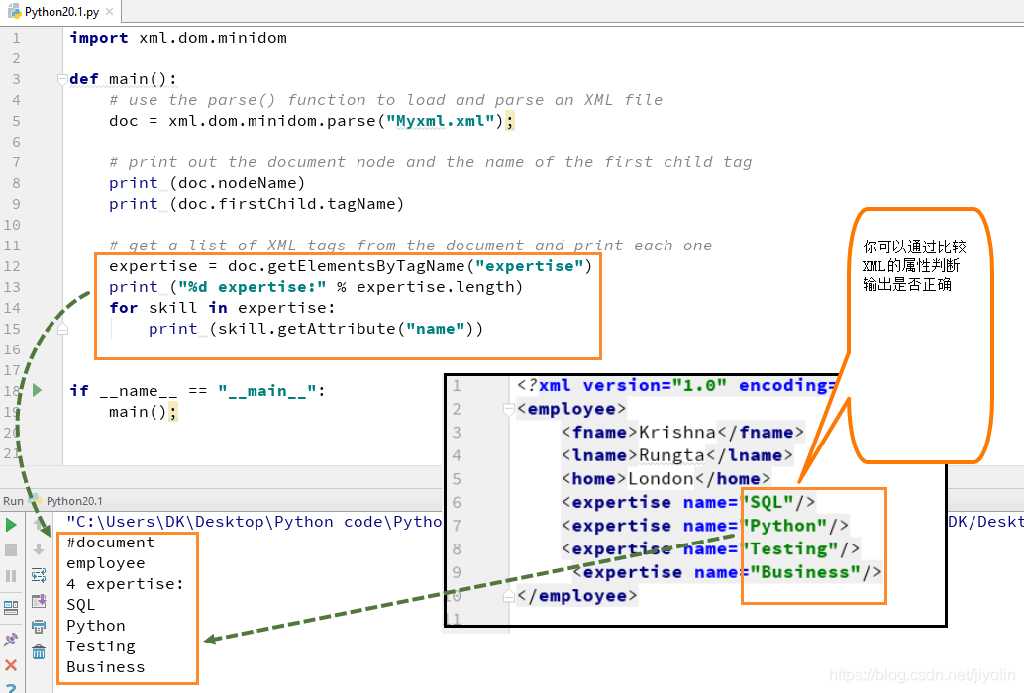
声明变量“专业知识”,我们将从中提取员工所具有的所有专业知识,使用名为“getElementsByTagName”的dom标准函数,这将获得所有名为skilled的元素,在每个skill tag上声明循环,运行代码 - 它将列出四种技能。
如何创建XML节点
我们可以使用“createElement”函数创建一个新属性,然后将这个新属性或标记附加到现有的XML标记。我们在XML文件中添加了一个新标签“BigData”。您必须编写代码将新属性(BigData)添加到现有XML标记,然后,您必须使用附加了现有XML标记的新属性打印出XML标记。

要添加新XML并将其添加到文档中,我们使用代码“doc.create elements“,此代码将为我们的新属性“Big-data”创建一个新技能标记,将此技能标记添加到文档第一个子节点(员工),运行代码,新标签“大数据”将与其他专业知识列表一起出现
XML解析示例
Python 2示例
import xml.dom.minidom
def main():
# use the parse() function to load and parse an XML file
doc = xml.dom.minidom.parse("Myxml.xml");
# print out the document node and the name of the first child tag
print doc.nodeName
print doc.firstChild.tagName
# get a list of XML tags from the document and print each one
expertise = doc.getElementsByTagName("expertise")
print "%d expertise:" % expertise.length
for skill in expertise:
print skill.getAttribute("name")
# create a new XML tag and add it into the document
newexpertise = doc.createElement("expertise")
newexpertise.setAttribute("name", "BigData")
doc.firstChild.appendChild(newexpertise)
print " "
expertise = doc.getElementsByTagName("expertise")
print "%d expertise:" % expertise.length
for skill in expertise:
print skill.getAttribute("name")
if name == "__main__":
main();
Python 3示例
import xml.dom.minidom
def main():
# use the parse() function to load and parse an XML file
doc = xml.dom.minidom.parse("Myxml.xml");
# print out the document node and the name of the first child tag
print (doc.nodeName)
print (doc.firstChild.tagName)
# get a list of XML tags from the document and print each one
expertise = doc.getElementsByTagName("expertise")
print ("%d expertise:" % expertise.length)
for skill in expertise:
print (skill.getAttribute("name"))
# create a new XML tag and add it into the document
newexpertise = doc.createElement("expertise")
newexpertise.setAttribute("name", "BigData")
doc.firstChild.appendChild(newexpertise)
print (" ")
expertise = doc.getElementsByTagName("expertise")
print ("%d expertise:" % expertise.length)
for skill in expertise:
print (skill.getAttribute("name"))
if __name__ == "__main__":
main();
如何使用ElementTree解析XML
ElementTree是一个用于操作XML的API。ElementTree是处理XML文件的简便方法。
我们使用以下XML文档作为示例数据:
<data>
<items>
<item name="expertise1">SQL</item>
<item name="expertise2">Python</item>
</items>
</data>
使用ElementTree读取XML:
我们必须先导入xml.etree.ElementTree模块。
import xml.etree.ElementTree as ET
现在让我们获取根元素:
root = tree.getroot()
以下是读取上述xml数据的完整代码
import xml.etree.ElementTree as ET
tree = ET.parse('items.xml')
root = tree.getroot()
# all items data
print('Expertise Data:')
for elem in root:
for subelem in elem:
print(subelem.text)
输出:
Expertise Data:
SQL
Python
摘要:
Python使您可以一次解析整个XML文档,而不是一次解析一行。为了解析XML文档,您需要将整个文档保存。解析XML文档,导入xml.dom.minidom,使用函数“parse”来解析文档(doc = xml.dom.minidom.parse(文件名);使用代码(=doc.getElementsByTagName(“xml标记的名称”)从XML文档调用XML标记列表,使用函数“createElement”在XML文档中创建和添加新属性。