深度学习中许多数据集的标注是以xml方式保存的
本文以VOC2012数据集的标注文件为例探究包ElementTree的使用
(有错误的地方大家提出来我做更改,有的地方我也不是很理解,但是可以使用这个类对数据集的xml标注文件解析,我就没有深入研究)
xml文件格式
<root> # 最开始的标签叫做根标签,根标签的名字是root
<part> # 子标签,子标签名字为part,可以重复
<name>123</name> # 子标签中的元素
<age>20</age>
<sex>男</sex>
</part>
<part>
<name>456</name>
<age>40</age>
<sex>男</sex>
</part>
</root>
ElementTree简介
一般引用包的方式为:import xml.etree.ElementTree as ET
class ElementTree:
"""
ElementTree类是专门解析xml的一个类,在xml.etree.ElementTree包中
"""
def __init__(self, element=None, file=None):
"""
element:指的是xml文件的根节点
file:指的是已经使用open打开的一个文件对象
"""
def getroot(self):
"""
返回树的根节点
"""
def _setroot(self, element):
"""
替换根节点
"""
def parse(self, source, parser=None):
"""
加载xml文件,解析文件
source:是open打开的xml文件的对象
parser:是是用什么方式解析xml文件
return:返回值是xml文件的根节点
"""
def iter(self, tag=None):
"""
创建并返回根标签下所有的元素的迭代器
tag:字符串,指的是根标签下的元素的子标签名称,如果不指定,就返回所有的子标签,如果指定只返回该名称的子节点
"""
# compatibility
def getiterator(self, tag=None):
"""
这个方法已经弃用了,使用上面的iter替代
"""
warnings.warn(
"This method will be removed in future versions. "
"Use 'tree.iter()' or 'list(tree.iter())' instead.",
PendingDeprecationWarning, stacklevel=2
)
return list(self.iter(tag))
def find(self, path, namespaces=None):
"""
查找名为path标签的内容
path:要查找的标签名字
"""
def findtext(self, path, default=None, namespaces=None):
"""
根据标记名称或路径找到第一个匹配的元素
path:查找的子标签的名称
namespace:命名空间
返回值是要查找的标签的内容,不存在时返回None
"""
def findall(self, path, namespaces=None):
"""
查找所有名为path的子标签的内容
path:标签的名称
namespace:命名空间
返回值是一个list,包含所有的名称为path的子标签的内容
"""
def iterfind(self, path, namespaces=None):
"""
根据标记名称找到所有的名为path的子标签的内容,返回值是一个迭代器
path:
namespace:
返回值是一个迭代器
"""
def write(self, file_or_filename,
encoding=None,
xml_declaration=None,
default_namespace=None,
method=None, *,
short_empty_elements=True):
代码示例
VOC数据集的xml标注文件
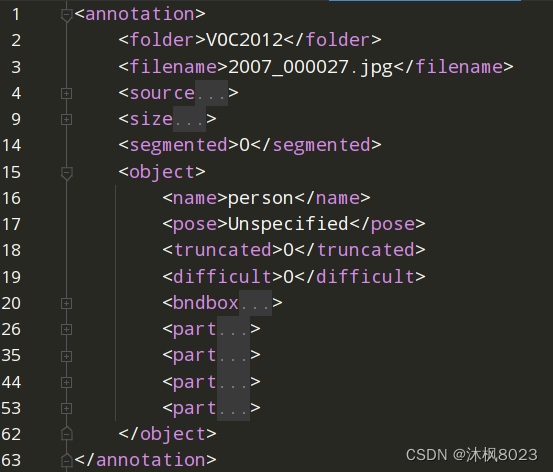
import xml.etree.ElementTree as ET
PATH = r"E:\pycharm\pytorch_object_detection\my_test\2007_000027.xml"
# xml文件解析,返回根节点:root = 'annotation'
root = ET.ElementTree().parse(open(PATH, 'r', encoding="utf-8"))
for obj in root.iter('object'): # 在root标签下找到所有的名为object的标签,并返回她们的迭代器
print(obj.find('name').text) # 查看obj标签下的子标签name的内容
box = obj.find('bndbox') # 查找object标签下子标签bnbox的元素,并打印其中的子标签的text
print(box.find('xmin').text, box.find('ymin').text, box.find('xmax').text, box.find('ymax').text)
print("====================================================================================")
for part in obj.findall('part'): # 将所有的名为part的子标签返回到一个列表中,并获取其中的内容
print(part.find('name').text)
print(part.find('bndbox').findtext('xmin'), # findtext返回查找到的第一个名为xmin的标签的内容
part.find('bndbox').findtext('ymin'),
part.find('bndbox').findtext('xmax'),
part.find('bndbox').findtext('ymax'))