SQL语言的主要特点
Structured Query Language 结构化查询语言。
SQL语言类似于英语的自然语言,简洁易用。
SQL语言是一种非过程语言,即用户只要提出“干什么”即可,不必管具体操作过程,也不必了解数据的存取路径,只要指明所需的数据即可。
SQL语言是一种面向集合的语言,每个命令的操作对象是一个或多个关系,结果也是一个关系。
SQL语言既是自含式语言,又是嵌入式语言。可独立使用,也可嵌入到宿主语言中。
SQL语句的动词只有九条

SELECT一般格式
SELECT [ALL | DISTINCT] <目标列表达式> [别名] [,<目标列表达式> [别名] ]…
FROM <表名或视图名>[, <表名或视图名>]…
[WHERE <条件表达式>]--
[GROUP BY <列名1>
[HAVING <条件表达式> ]]
[ORDER BY <列名2 >[ASC | DESC]];
WHERE语句
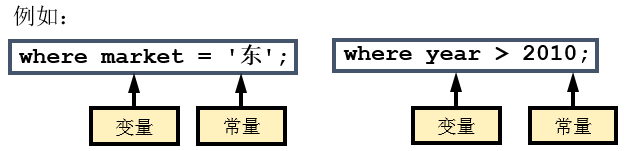
用WHERE 语句 选择满足特定条件的观测。

WHERE 语句的一般形式:

where-表达式 是由一系列运算符和操作数组成的用来选择观测的条件表达式。
运算数包含常量和变量。
运算符包含算术运算符,比较算符和逻辑算符。
常量运算数是固定值。
字符值必须包含在引号中并且区分大小写。
数值不用引号。
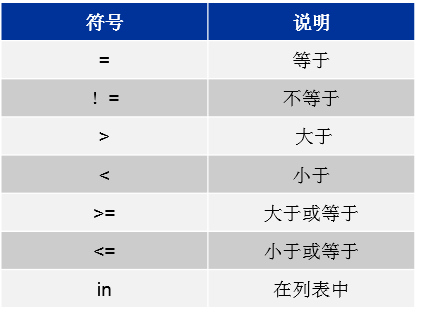
比较运算符 比较一个变量和一个值,或一个变量和另一个变量。
算数运算符 表示要进行算数计算
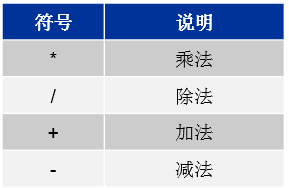
逻辑运算符 合并或修改表达式
多表的纵向合并
在SQL语句中使用集合运算完成。
在R语句中使用rbind() 函数完成
将两张表中的记录看作一个集合,则
并集是两张表中重复的记录只保留一份,不重复都保留;
交集是只保留一份重复的记录;
差集是只保留表1中不重复的记录。
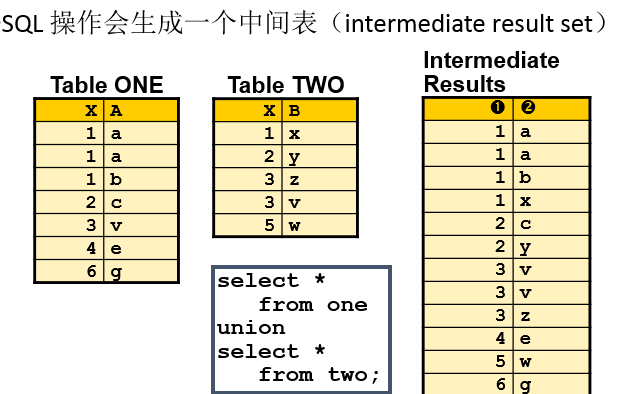
并集(UNION)
并集是将两个表中的同名列合并。
Rbind语句和SQL的union语句在处理变量名称上有明显的区别。
UNION1<- rbind(one, two)
select *
from one
union
select *
from two;
UNION_all<-sqldf("select * from one union all select * from two")
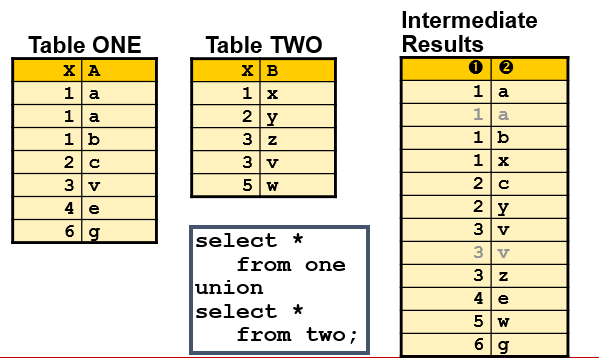
union后面没有跟随all选项,因此剔除重复值。
差集(EXCEPT )
只保留第一张表有,而且第二张表没有的观测。
select *
from one
except
select *
from two;
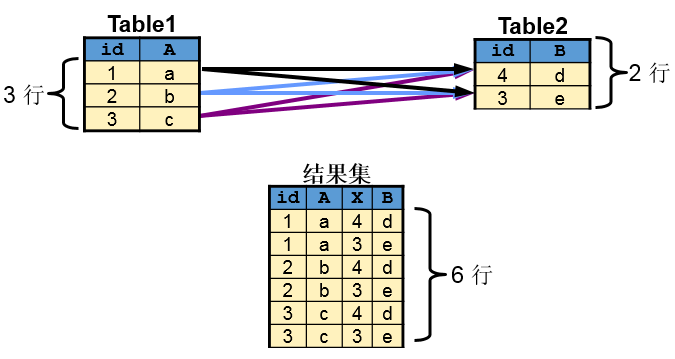
横向连接查询基础
交叉连接(cross join,笛卡尔乘积):查询结果包括两张表观测的所有组合情况,这是SQL实现两表合并的基础,但是极少单独做这种操作;
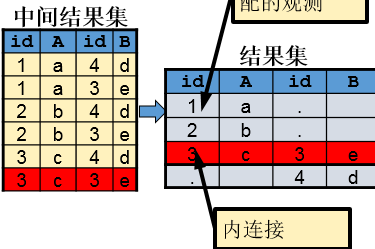
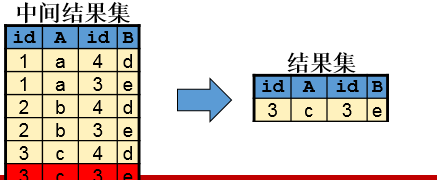
内连接(inner join):查询结果只包括两张表向匹配的观测,用法简单,但是在数据分析中谨慎使用,因为会造成样本的缺失;
外连接(outer join)包括左连接、右连接,全连接。


内连接在笛卡尔积基础之上加入了连接条件,其实就是限制条件,这类似单表操作中对观测进行筛选。
inner1<- merge(table1, table2, by = "id", all = FALSE)
inner2<-inner_join(table1, table2, by = "id")
inner3<-sqldf("select * from table1 as a inner join table2 as b on a.id=b.id")
inner4<-sqldf("select * from table1 as a,table2 as b where a.id=b.id")
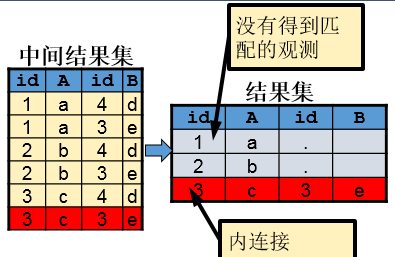
左连接等价于两部分的叠加:内连接+左表中没有匹配的观测
left1<- merge(table1, table2, by = "id", all.x = TRUE)
left2<-left_join(table1, table2, by = "id")
left3<-sqldf("select * from table1 as a left join table2 as b on a.id=b.id")
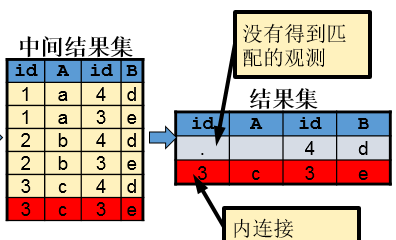
右连接等价于两部分的叠加:内连接+右表中没有匹配的观测。
right1<- merge(table1, table2, by = "id", all.y = TRUE)
right2<-right_join(table1, table2, by = "id")
right3<-sqldf("select * from table1 as a right join table2 as b on a.id=b.id")
全连接等价于三部分的叠加:内连接+左表中没有匹配的观测+右表中没有匹配的观测。
full1<- merge(table1, table2, by = "id", all = TRUE)
full2<-full_join(table1, table2, by = "id")
full3<-sqldf("select * from table1 as a full join table2 as b on a.id=b.id")