深度好文 | Matplotlib可视化最有价值的 50 个图表(附完整 Python 源代码)(★★★★★)
代码地址:https://github.com/liyangbit/PyDataRoad/tree/master/projects/matplotlib-top-50-visualizations
五星级推荐,上面链接的文章总结了 Matplotlib 以及 Seaborn 用的最多的50个图形,掌握这些图形的绘制,对于数据分析的可视化有莫大的作用,强烈推荐大家阅读后续内容。
大佬送福利了,项目来自于 github,我节选一些个人觉得用得上的地方,所有数据用 pandas 处理的,pandas 入门可以参考这篇博客 【python】numpy & pandas
文章目录
- 0 准备工作
- 1 关联 (Correlation)
- 1.1 散点图(Scatter plot)
- 1.2 带线性回归最佳拟合线的散点图 (Scatter plot with linear regression line of best fit)
- 1.3 边缘直方图 (Marginal Histogram)
- 1.4 边缘箱形图 (Marginal Boxplot)
- 1.5 相关图 (Correllogram)
- 1.6 矩阵图 (Pairwise Plot)
- 2 偏差 (Deviation)
- 3 分布 (Distribution)
- 3.1 连续变量的直方图 (Histogram for Continuous Variable)
- 3.2 类型变量的直方图 (Histogram for Categorical Variable)
- 3.3 密度图 (Density Plot)
- 3.4 直方密度线图 (Density Curves with Histogram)
- 3.5 Joy Plot
- 3.6 箱形图 (Box Plot)
- 3.7 包点+箱形图 (Dot + Box Plot)
- 3.8 小提琴图 (Violin Plot)
- 3.9 分类图 (Categorical Plots)
- 4 组成 (Composition)
- 5 变化 (Change)
- 6 分组 (Groups)
0 准备工作
-
matplotlib
matplotlib是Python数据可视化库的OG。尽管它已有十多年的历史,但仍然是Python社区中使用最广泛的绘图库。它的设计与MATLAB非常相似,MATLAB是20世纪80年代开发的专有编程语言。 -
Seaborn
Seaborn利用matplotlib的强大功能,可以只用几行代码就创建漂亮的图表。关键区别在于Seaborn的默认款式和调色板设计更加美观和现代。由于Seaborn是在matplotlib之上构建的,因此还需要了解matplotlib以便调整Seaborn的默认值。
python 还有其它的数据可视化库,eg ggplot、Bokeh、pygal、Plotly、geoplotlib、Gleam、missingno、Leather、Chartify、Altair 具体介绍可参考 12个流行的Python数据可视化库总结
# !pip install brewer2mpl
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
import warnings; warnings.filterwarnings(action='once')
large = 22; med = 16; small = 12
params = {'axes.titlesize': large,
'legend.fontsize': med,
'figure.figsize': (16, 10),
'axes.labelsize': med,
'axes.titlesize': med,
'xtick.labelsize': med,
'ytick.labelsize': med,
'figure.titlesize': large}
plt.rcParams.update(params)
plt.style.use('seaborn-whitegrid')
sns.set_style("white")
%matplotlib inline
# Version
print(mpl.__version__) #> 3.0.0
print(sns.__version__) #> 0.9.0
output
3.0.0
0.9.0
升级前,我的版本是
2.2.2
0.8.0
升级 matplotlib,后面 -i 是为了加速,具体参考 服务器上配置 Tensorflow GPU 版
pip install --upgrade matplotlib==3.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
升级seaborn
pip install --upgrade seaborn==0.9 -i https://pypi.tuna.tsinghua.edu.cn/simple
1 关联 (Correlation)
关联图表用于可视化2个或更多变量之间的关系。 也就是说,一个变量如何相对于另一个变化。
1.1 散点图(Scatter plot)
散点图是用于研究两个变量之间关系的经典的和基本的图表。 如果数据中有多个组,则可能需要以不同颜色可视化每个组。 在 matplotlib 中,您可以使用 plt.scatterplot() 方便地执行此操作。
# Prepare Data
midwest = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/midwest_filter.csv")# 332 rows × 29 columns
# Create as many colors as there are unique midwest['category']
categories = np.unique(midwest['category']) # 取 category 列的所有元素的集合
colors = [plt.cm.tab10(i/float(len(categories)-1)) for i in range(len(categories))]
# Draw Plot for Each Category
plt.figure(figsize=(16, 12), dpi= 50, facecolor='w', edgecolor='k')
for i, category in enumerate(categories):
plt.scatter('area', 'poptotal',
data=midwest.loc[midwest.category==category, :],
s=50, cmap=colors[i], label=str(category))# s 控制点的大小
# Decorations
plt.gca().set(xlim=(0.0, 0.1), ylim=(0, 90000),
xlabel='Area', ylabel='Population')
plt.xticks(fontsize=12); plt.yticks(fontsize=12)
plt.title("Scatterplot of Midwest Area vs Population", fontsize=22)
plt.legend(fontsize=12)
plt.show()
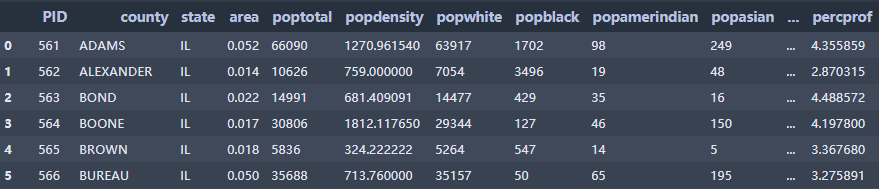
数据集 332 rows × 29 columns
部分节选如下
画出来的效果如下

1.2 带线性回归最佳拟合线的散点图 (Scatter plot with linear regression line of best fit)
如果你想了解两个变量如何相互改变,那么最佳拟合线就是常用的方法。 下图显示了数据中各组之间最佳拟合线的差异。 要禁用分组并仅为整个数据集绘制一条最佳拟合线,请从下面的 sns.lmplot() 调用中删除 hue ='cyl' 参数。
画图过程有点慢,因为要拟合
# Import Data
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv")#234 rows × 11 columns
df_select = df.loc[df.cyl.isin([4,8]), :] # 选出 cyl 列中值为 4 和 8 的值 151 rows × 11 columns
# Plot
sns.set_style("white")
gridobj = sns.lmplot(x="displ", y="hwy", hue="cyl", data=df_select,
height=7, aspect=1.6, robust=True, palette='tab10',
scatter_kws=dict(s=60, linewidths=.7, edgecolors='black'))# height 控制图大小
# Decorations
gridobj.set(xlim=(0.5, 7.5), ylim=(0, 50))
plt.title("Scatterplot with line of best fit grouped by number of cylinders", fontsize=20)
plt.savefig('1.png')
plt.show()
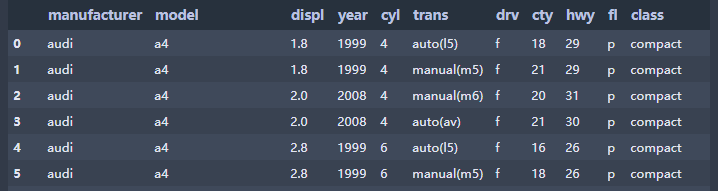
部分数据集(234 rows × 11 columns)

可以分开画,通过 sns.lmplot 中的 col 属性来控制
# Import Data
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv")
df_select = df.loc[df.cyl.isin([4,8]), :]
# Each line in its own column
sns.set_style("white")
gridobj = sns.lmplot(x="displ", y="hwy",
data=df_select,
height=7,
robust=True,
palette='Set1',
col="cyl",
scatter_kws=dict(s=60, linewidths=.7, edgecolors='black'))
# Decorations
gridobj.set(xlim=(0.5, 7.5), ylim=(0, 50))
plt.show()

1.3 边缘直方图 (Marginal Histogram)
边缘直方图具有沿 X 和 Y 轴变量的直方图。 这用于可视化 X 和 Y 之间的关系以及单独的 X 和 Y 的单变量分布。 这种图经常用于探索性数据分析(EDA)。
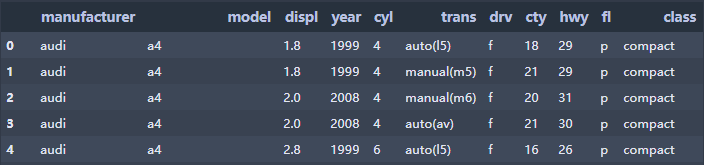
234 rows × 11 columns,右边是 displ 列的分布,下面是hwy列的分布
# Import Data
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv")
# Create Fig and gridspec
fig = plt.figure(figsize=(12, 8), dpi= 60)
grid = plt.GridSpec(4, 4, hspace=0.5, wspace=0.2)
# Define the axes
ax_main = fig.add_subplot(grid[:-1, :-1])
ax_right = fig.add_subplot(grid[:-1, -1], xticklabels=[], yticklabels=[])
ax_bottom = fig.add_subplot(grid[-1, 0:-1], xticklabels=[], yticklabels=[])
# Scatterplot on main ax
ax_main.scatter('displ', 'hwy', s=df.cty*4, c=df.manufacturer.astype('category').cat.codes, alpha=.9, data=df, cmap="tab10", edgecolors='gray', linewidths=.5)
# histogram on the right
ax_bottom.hist(df.displ, 40, histtype='stepfilled', orientation='vertical', color='deeppink')
ax_bottom.invert_yaxis()
# histogram in the bottom
ax_right.hist(df.hwy, 40, histtype='stepfilled', orientation='horizontal', color='deeppink')
# Decorations
ax_main.set(title='Scatterplot with Histograms \n displ vs hwy', xlabel='displ', ylabel='hwy')
ax_main.title.set_fontsize(20)
for item in ([ax_main.xaxis.label, ax_main.yaxis.label] + ax_main.get_xticklabels() + ax_main.get_yticklabels()):
item.set_fontsize(14)
xlabels = ax_main.get_xticks().tolist()
ax_main.set_xticklabels(xlabels)
plt.show()

1.4 边缘箱形图 (Marginal Boxplot)
边缘箱图与边缘直方图具有相似的用途。 然而,箱线图有助于精确定位 X 和 Y 的中位数、第25和第75百分位数。
234 rows × 11 columns,右边是 hwy 列的箱形图,下面是列 displ 的箱形图
# Import Data
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv")
# Create Fig and gridspec
fig = plt.figure(figsize=(12, 8), dpi= 60)
grid = plt.GridSpec(4, 4, hspace=0.5, wspace=0.2)
# Define the axes
ax_main = fig.add_subplot(grid[:-1, :-1])
ax_right = fig.add_subplot(grid[:-1, -1], xticklabels=[], yticklabels=[])
ax_bottom = fig.add_subplot(grid[-1, 0:-1], xticklabels=[], yticklabels=[])
# Scatterplot on main ax
ax_main.scatter('displ', 'hwy', s=df.cty*5, c=df.manufacturer.astype('category').cat.codes, alpha=.9, data=df, cmap="Set1", edgecolors='black', linewidths=.5)
# Add a graph in each part
sns.boxplot(df.hwy, ax=ax_right, orient="v")
sns.boxplot(df.displ, ax=ax_bottom, orient="h")
# Decorations ------------------
# Remove x axis name for the boxplot
ax_bottom.set(xlabel='')
ax_right.set(ylabel='')
# Main Title, Xlabel and YLabel
ax_main.set(title='Scatterplot with Histograms \n displ vs hwy', xlabel='displ', ylabel='hwy')
# Set font size of different components
ax_main.title.set_fontsize(20)
for item in ([ax_main.xaxis.label, ax_main.yaxis.label] + ax_main.get_xticklabels() + ax_main.get_yticklabels()):
item.set_fontsize(14)
plt.show()

1.5 相关图 (Correllogram)
相关图用于直观地查看给定数据框(或二维数组)中所有可能的数值变量对之间的相关度量。
(32, 14)
核心函数 df.corr() pandas.DataFrame.corr

# Import Dataset
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv")
# Plot
plt.figure(figsize=(12,8), dpi= 60)
sns.heatmap(df.corr(), xticklabels=df.corr().columns, yticklabels=df.corr().columns, cmap='RdYlGn', center=0, annot=True)
# Decorations
plt.title('Correlogram of mtcars', fontsize=22)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.show()

1.6 矩阵图 (Pairwise Plot)
矩阵图是探索性分析中的最爱,用于理解所有可能的数值变量对之间的关系。 它是双变量分析的必备工具。
150 rows × 5 columns
# Load Dataset
df = sns.load_dataset('iris')
# Plot
plt.figure(figsize=(10,8), dpi= 80)
sns.pairplot(df, kind="scatter", hue="species", plot_kws=dict(s=80, edgecolor="white", linewidth=2.5))
plt.show()

# Load Dataset
df = sns.load_dataset('iris')
# Plot
plt.figure(figsize=(10,8), dpi= 10)
sns.pairplot(df, kind="reg", hue="species")
plt.show()

2 偏差 (Deviation)
2.1 面积图 (Area Chart)
通过对轴和线之间的区域进行着色,面积图不仅强调峰和谷,而且还强调高点和低点的持续时间。 高点持续时间越长,线下面积越大
100 rows × 6 columns

diff() 求差分,这里求列的差分,第一排 nan,第二排减第一排,第三排减第二排……参考 diff函数
fillna(0) 就是把差分后的 nan 填上 0
shift(1) 这里表示某一列所有元素下移一行,第一行为 nan
import numpy as np
import pandas as pd
# Prepare Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/economics.csv", parse_dates=['date']).head(100)
x = np.arange(df.shape[0]) # x
y_returns = (df.psavert.diff().fillna(0)/df.psavert.shift(1)).fillna(0) * 100 # y
# Plot
plt.figure(figsize=(12,8), dpi= 60)
plt.fill_between(x[1:], y_returns[1:], 0, where=y_returns[1:] >= 0, facecolor='green', interpolate=True, alpha=0.7) # 大于0补绿色
plt.fill_between(x[1:], y_returns[1:], 0, where=y_returns[1:] <= 0, facecolor='red', interpolate=True, alpha=0.7) # 小于0补红色
# Annotate
plt.annotate('Peak \n1975', xy=(94.0, 21.0), xytext=(88.0, 28),
bbox=dict(boxstyle='square', fc='firebrick'),
arrowprops=dict(facecolor='steelblue', shrink=0.05), fontsize=15, color='white')
# Decorations
xtickvals = [str(m)[:3].upper()+"-"+str(y) for y,m in zip(df.date.dt.year, df.date.dt.month)]
plt.gca().set_xticks(x[::6])
plt.gca().set_xticklabels(xtickvals[::6], rotation=90, fontdict={'horizontalalignment': 'center', 'verticalalignment': 'center_baseline'})
plt.ylim(-35,35)
plt.xlim(1,100)
plt.title("Month Economics Return %", fontsize=22)
plt.ylabel('Monthly returns %')
plt.grid(alpha=0.5)
plt.show()

df.date.dt.month_name() 我这里会报错,不晓得是不是 pandas 的版本问题,我改为df.date.dt.month 显示月份的数字,而不是名字,差别不是很大
这里有一个讨论这个问题的 https://github.com/pandas-dev/pandas/issues/22830
3 分布 (Distribution)
3.1 连续变量的直方图 (Histogram for Continuous Variable)
直方图显示给定变量的频率分布。 下面的图表示基于类型变量对频率条进行分组,从而更好地了解连续变量和类型变量。
234 rows × 11 columns

# Import Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare data
x_var = 'displ'
groupby_var = 'class'
df_agg = df.loc[:, [x_var, groupby_var]].groupby(groupby_var)
vals = [df[x_var].values.tolist() for i, df in df_agg]
# Draw
plt.figure(figsize=(12,6), dpi= 60)
colors = [plt.cm.Spectral(i/float(len(vals)-1)) for i in range(len(vals))]
n, bins, patches = plt.hist(vals, 30, stacked=True, density=False, color=colors[:len(vals)])
# Decoration
plt.legend({group:col for group, col in zip(np.unique(df[groupby_var]).tolist(), colors[:len(vals)])})
plt.title(f"Stacked Histogram of ${x_var}$ colored by ${groupby_var}$", fontsize=22)
plt.xlabel(x_var)
plt.ylabel("Frequency")
plt.ylim(0, 25)
plt.xticks(ticks=bins[::3], labels=[round(b,1) for b in bins[::3]])
plt.show()

3.2 类型变量的直方图 (Histogram for Categorical Variable)
类型变量的直方图显示该变量的频率分布。 通过对条形图进行着色,可以将分布与表示颜色的另一个类型变量相关联。
234 rows × 11 columns(同 3.1 节)
# Import Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare data
x_var = 'manufacturer'
groupby_var = 'class'
df_agg = df.loc[:, [x_var, groupby_var]].groupby(groupby_var)
vals = [df[x_var].values.tolist() for i, df in df_agg]
# Draw
plt.figure(figsize=(12,6), dpi= 60)
colors = [plt.cm.Spectral(i/float(len(vals)-1)) for i in range(len(vals))]
n, bins, patches = plt.hist(vals, df[x_var].unique().__len__(), stacked=True, density=False, color=colors[:len(vals)])
# Decoration
plt.legend({group:col for group, col in zip(np.unique(df[groupby_var]).tolist(), colors[:len(vals)])})
plt.title(f"Stacked Histogram of ${x_var}$ colored by ${groupby_var}$", fontsize=22)
plt.xlabel(x_var)
plt.ylabel("Frequency")
plt.ylim(0, 40)
plt.xticks(ticks=bins, labels=np.unique(df[x_var]).tolist(), rotation=90, horizontalalignment='left')
plt.show()

3.3 密度图 (Density Plot)
密度图是一种常用工具,用于可视化连续变量的分布。 通过“响应”变量对它们进行分组,您可以检查 X 和 Y 之间的关系。以下情况用于表示目的,以描述城市里程的分布如何随着汽缸数的变化而变化。
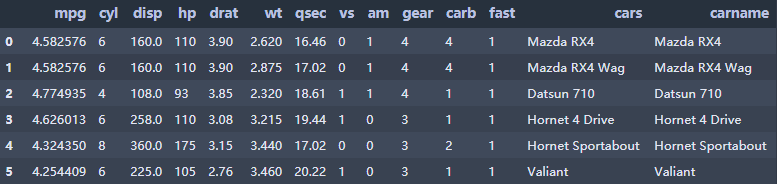
234 rows × 11 columns(同 3.1 节)
np.unique(df.cyl)
output
array([4, 5, 6, 8])

3.4 直方密度线图 (Density Curves with Histogram)
带有直方图的密度曲线汇集了两个图所传达的集体信息,因此您可以将它们放在一个图中而不是两个图中。
234 rows × 11 columns(同 3.1 节)
np.unique(df.cty)
output
array([ 9, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26,
28, 29, 33, 35])
统计 cty 列的三类数据
# Import Data
# Import Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Draw Plot
plt.figure(figsize=(12,6), dpi= 60)
sns.distplot(df.loc[df['class'] == 'compact', "cty"], color="dodgerblue", label="Compact", hist_kws={'alpha':.7}, kde_kws={'linewidth':3})
sns.distplot(df.loc[df['class'] == 'suv', "cty"], color="orange", label="SUV", hist_kws={'alpha':.7}, kde_kws={'linewidth':3})
sns.distplot(df.loc[df['class'] == 'minivan', "cty"], color="g", label="minivan", hist_kws={'alpha':.7}, kde_kws={'linewidth':3})
plt.ylim(0, 0.35)
# Decoration
plt.title('Density Plot of City Mileage by Vehicle Type', fontsize=22)
plt.legend()
plt.show()

3.5 Joy Plot
Joy Plot允许不同组的密度曲线重叠,这是一种可视化大量分组数据的彼此关系分布的好方法。 它看起来很悦目,并清楚地传达了正确的信息。 它可以使用基于 matplotlib 的 joypy 包轻松构建。 (需要安装 joypy 库)
pip install joypy -i https://pypi.tuna.tsinghua.edu.cn/simple 后面-i的部分是用来加速
234 rows × 11 columns(同 3.1 节)
统计 column=['hwy', 'cty'] 这两列在每类中的分布
# pip install joypy
import joypy
# Import Data
mpg = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Draw Plot
plt.figure(figsize=(9,5), dpi= 60)
fig, axes = joypy.joyplot(mpg, column=['hwy', 'cty'], by="class", ylim='own', figsize=(10,6))
# Decoration
plt.title('Joy Plot of City and Highway Mileage by Class', fontsize=22)
plt.show()

3.6 箱形图 (Box Plot)
箱形图是一种可视化分布的好方法,记住中位数、第25个第45个四分位数和异常值。 但是,您需要注意解释可能会扭曲该组中包含的点数的框的大小。 因此,手动提供每个框中的观察数量可以帮助克服这个缺点。
例如,左边的前两个框具有相同大小的框,即使它们的值分别是5和47。 因此,写入该组中的观察数量是必要的。
234 rows × 11 columns(同 3.1 节)
hwy 列数据在每类上的分布
# Import Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Draw Plot
plt.figure(figsize=(12,8), dpi= 60)
sns.boxplot(x='class', y='hwy', data=df, notch=False)
# Add N Obs inside boxplot (optional)
def add_n_obs(df,group_col,y):
medians_dict = {grp[0]:grp[1][y].median() for grp in df.groupby(group_col)}
xticklabels = [x.get_text() for x in plt.gca().get_xticklabels()]
n_obs = df.groupby(group_col)[y].size().values
for (x, xticklabel), n_ob in zip(enumerate(xticklabels), n_obs):
plt.text(x, medians_dict[xticklabel]*1.01, "#obs : "+str(n_ob), horizontalalignment='center', fontdict={'size':14}, color='white')
add_n_obs(df,group_col='class',y='hwy')
# Decoration
plt.title('Box Plot of Highway Mileage by Vehicle Class', fontsize=22)
plt.ylim(10, 40)
plt.show()

3.7 包点+箱形图 (Dot + Box Plot)
包点+箱形图 (Dot + Box Plot)传达类似于分组的箱形图信息。 此外,这些点可以了解每组中有多少数据点。
234 rows × 11 columns(同 3.1 节)
# Import Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Draw Plot
plt.figure(figsize=(12,8), dpi= 60)
sns.boxplot(x='class', y='hwy', data=df, hue='cyl')
sns.stripplot(x='class', y='hwy', data=df, color='black', size=3, jitter=1)
for i in range(len(df['class'].unique())-1):
plt.vlines(i+.5, 10, 45, linestyles='solid', colors='gray', alpha=0.2)
# Decoration
plt.title('Box Plot of Highway Mileage by Vehicle Class', fontsize=22)
plt.legend(title='Cylinders')
plt.show()
np.unique(df.cyl)
output
array([4, 5, 6, 8])
横坐标类别,纵坐标 hwy 列的数据分布,根据 cyl 进行分组(数据划分的流程为,类-hwy-cyl)

3.8 小提琴图 (Violin Plot)
小提琴图是箱形图在视觉上令人愉悦的替代品。 小提琴的形状或面积取决于它所持有的观察次数。 但是,小提琴图可能更难以阅读,并且在专业设置中不常用。
234 rows × 11 columns(同 3.1 节)
# Import Data
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Draw Plot
plt.figure(figsize=(12,8), dpi= 60)
sns.violinplot(x='class', y='hwy', data=df, scale='width', inner='quartile')
# Decoration
plt.title('Violin Plot of Highway Mileage by Vehicle Class', fontsize=22)
plt.show()
hwy 列的数据在每类中的分布

3.9 分类图 (Categorical Plots)
由 seaborn库 提供的分类图可用于可视化彼此相关的2个或更多分类变量的计数分布。
891 rows × 15 columns

a = set(titanic.deck)
a
output
{nan, 'D', 'G', 'B', 'F', 'C', 'A', 'E'}
画图
# Load Dataset
titanic = sns.load_dataset("titanic")
# Plot
g = sns.catplot("alive", col="deck", col_wrap=4,
data=titanic[titanic.deck.notnull()],
kind="count", height=2.5, aspect=.8,
palette='tab20')
fig.suptitle('sf')
plt.show()

b = set(titanic.embark_town)
b
output
{nan, 'Cherbourg', 'Queenstown', 'Southampton'}
a = set(titanic['class'])
a
output
{'First', 'Second', 'Third'}
画图
# Load Dataset
titanic = sns.load_dataset("titanic")
# Plot
sns.catplot(x="age", y="embark_town",
hue="sex", col="class",
data=titanic[titanic.embark_town.notnull()],
orient="h", height=3.5, aspect=1, palette="tab10",
kind="violin", dodge=True, cut=0, bw=.2)

删掉 sns.catplot 中的 hue

4 组成 (Composition)
4.1 华夫饼图 (Waffle Chart)
可以使用 pywaffle包 创建华夫饼图,并用于显示更大群体中的组的组成。
pip install pywaffle -i https://pypi.tuna.tsinghua.edu.cn/simple 安装
234 rows × 11 columns(同 3.1 节)
print(set(df_raw['class']))
output
{'suv', 'midsize', 'compact', 'minivan', 'pickup', '2seater', 'subcompact'}
画图,根据 class 的 size 来分组
#! pip install pywaffle
# Reference: https://stackoverflow.com/questions/41400136/how-to-do-waffle-charts-in-python-square-piechart
from pywaffle import Waffle
# Import
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare Data
df = df_raw.groupby('class').size().reset_index(name='counts')
n_categories = df.shape[0]
colors = [plt.cm.inferno_r(i/float(n_categories)) for i in range(n_categories)]
# Draw Plot and Decorate
fig = plt.figure(
FigureClass=Waffle,
plots={
'111': {
'values': df['counts'],
'labels': ["{0} ({1})".format(n[0], n[1]) for n in df[['class', 'counts']].itertuples()],
'legend': {'loc': 'upper left', 'bbox_to_anchor': (1.05, 1), 'fontsize': 12},
'title': {'label': '# Vehicles by Class', 'loc': 'center', 'fontsize':18}
},
},
rows=7,
colors=colors,
figsize=(16, 9)
)

4.2 饼图 (Pie Chart)
饼图是显示组成的经典方式。 然而,现在通常不建议使用它,因为馅饼部分的面积有时会变得误导。 因此,如果您要使用饼图,强烈建议明确记下饼图每个部分的百分比或数字。
234 rows × 11 columns(同 3.1 节)
# Import
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare Data
df = df_raw.groupby('class').size()
# Make the plot with pandas
df.plot(kind='pie', subplots=True, figsize=(6, 6))
plt.title("Pie Chart of Vehicle Class - Bad")
plt.ylabel("")
plt.show()

改进
# Import
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare Data
df = df_raw.groupby('class').size().reset_index(name='counts')
# Draw Plot
fig, ax = plt.subplots(figsize=(9, 8), subplot_kw=dict(aspect="equal"), dpi= 60)
data = df['counts']
categories = df['class']
explode = [0,0,0,0,0,0.1,0]
def func(pct, allvals):
absolute = int(pct/100.*np.sum(allvals))
return "{:.1f}% ({:d} )".format(pct, absolute)
wedges, texts, autotexts = ax.pie(data,
autopct=lambda pct: func(pct, data),
textprops=dict(color="w"),
colors=plt.cm.Dark2.colors,
startangle=140,
explode=explode)
# Decoration
ax.legend(wedges, categories, title="Vehicle Class", loc="center left", bbox_to_anchor=(1, 0, 0.5, 1))
plt.setp(autotexts, size=10, weight=700)
ax.set_title("Class of Vehicles: Pie Chart")
plt.show()

4.3 树形图 (Treemap)
树形图类似于饼图,它可以更好地完成工作而不会误导每个组的贡献。
pip install squarify -i https://pypi.tuna.tsinghua.edu.cn/simple安装 squarify
234 rows × 11 columns(同 3.1 节)
# pip install squarify
import squarify
# Import Data
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare Data
df = df_raw.groupby('class').size().reset_index(name='counts')
labels = df.apply(lambda x: str(x[0]) + "\n (" + str(x[1]) + ")", axis=1)
sizes = df['counts'].values.tolist()
colors = [plt.cm.Spectral(i/float(len(labels))) for i in range(len(labels))]
# Draw Plot
plt.figure(figsize=(12,8), dpi= 60)
squarify.plot(sizes=sizes, label=labels, color=colors, alpha=.8)
# Decorate
plt.title('Treemap of Vechile Class')
plt.axis('off')
plt.show()

4.4 条形图 (Bar Chart)
条形图是基于计数或任何给定指标可视化项目的经典方式。 在下面的图表中,我为每个项目使用了不同的颜色,但您通常可能希望为所有项目选择一种颜色,除非您按组对其进行着色。 颜色名称存储在下面代码中的all_colors中。 您可以通过在plt.plot()中设置颜色参数来更改条的颜色。
234 rows × 11 columns(同 3.1 节)
import random
# Import Data
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare Data
df = df_raw.groupby('manufacturer').size().reset_index(name='counts')
n = df['manufacturer'].unique().__len__()+1
all_colors = list(plt.cm.colors.cnames.keys())
random.seed(100)
c = random.choices(all_colors, k=n)
# Plot Bars
plt.figure(figsize=(12,8), dpi= 60)
plt.bar(df['manufacturer'], df['counts'], color=c, width=.5)
for i, val in enumerate(df['counts'].values):
plt.text(i, val, float(val), horizontalalignment='center', verticalalignment='bottom', fontdict={'fontweight':500, 'size':12})
# Decoration
plt.gca().set_xticklabels(df['manufacturer'], rotation=60, horizontalalignment= 'right')
plt.title("Number of Vehicles by Manaufacturers", fontsize=22)
plt.ylabel('# Vehicles')
plt.ylim(0, 45)
plt.show()

print(sorted(set(df_raw['manufacturer'])))
output
['audi', 'chevrolet', 'dodge', 'ford', 'honda', 'hyundai', 'jeep', 'land rover', 'lincoln', 'mercury', 'nissan', 'pontiac', 'subaru', 'toyota', 'volkswagen']
5 变化 (Change)
5.1 日历热力图 (Calendar Heat Map)
与时间序列相比,日历地图是可视化基于时间的数据的备选和不太优选的选项。 虽然可以在视觉上吸引人,但数值并不十分明显。 然而,它可以很好地描绘极端值和假日效果。
pip install calmap -i https://pypi.tuna.tsinghua.edu.cn/simple 安装 calmap
2518 rows × 12 columns
 最后一列是 week
最后一列是 week
df.columns
output
Index(['VIX.Open', 'VIX.High', 'VIX.Low', 'VIX.Close', 'VIX.Volume',
'VIX.Adjusted', 'year', 'month', 'monthf', 'weekday', 'weekdayf',
'week'],
dtype='object')
画 df['2014']['VIX.Close'] 也就是 VIX.Close 列的值
import matplotlib as mpl
# pip install calmap
import calmap
# Import Data
df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/yahoo.csv", parse_dates=['date'])
df.set_index('date', inplace=True)
# Plot
plt.figure(figsize=(16,10), dpi= 80)
calmap.calendarplot(df['2014']['VIX.Close'], fig_kws={'figsize': (16,10)}, yearlabel_kws={'color':'black', 'fontsize':14}, subplot_kws={'title':'Yahoo Stock Prices'})
plt.show()

6 分组 (Groups)
6.1 树状图 (Dendrogram)
树形图基于给定的距离度量将相似的点组合在一起,并基于点的相似性将它们组织在树状链接中。
(50, 5)

import scipy.cluster.hierarchy as shc
# Import Data
df = pd.read_csv('https://raw.githubusercontent.com/selva86/datasets/master/USArrests.csv')
# Plot
plt.figure(figsize=(12, 8), dpi= 60)
plt.title("USArrests Dendograms", fontsize=22)
dend = shc.dendrogram(shc.linkage(df[['Murder', 'Assault', 'UrbanPop', 'Rape']], method='ward'), labels=df.State.values, color_threshold=100)
plt.xticks(fontsize=12)
plt.show()

6.2 平行坐标 (Parallel Coordinates)
平行坐标有助于可视化特征是否有助于有效地隔离组。 如果实现隔离,则该特征可能在预测该组时非常有用。
599 rows × 5 columns

set(df_final['cut'])
output
{'Fair', 'Good', 'Ideal', 'Premium'}
from pandas.plotting import parallel_coordinates
# Import Data
df_final = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/diamonds_filter.csv")
# Plot
plt.figure(figsize=(10,8), dpi= 60)
parallel_coordinates(df_final, 'cut', colormap='Dark2')
# Lighten borders
plt.gca().spines["top"].set_alpha(0)
plt.gca().spines["bottom"].set_alpha(.3)
plt.gca().spines["right"].set_alpha(0)
plt.gca().spines["left"].set_alpha(.3)
plt.title('Parallel Coordinated of Diamonds', fontsize=22)
plt.grid(alpha=0.3)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.show()

这种图我看了好多次,一直不太懂,这次特意查了下 数据可视化—平行坐标图的定义及解读方式

首先我们用不同的颜色来标识不同的标签,那么关于属性与标签之间的关系,我们可以从图中获得哪些信息?
-
折线走势“陡峭”与“低谷”只是表示在该属性上属性值的变化范围的大小,对于标签分类不具有决定意义,但是“陡峭“的属性上属性值间距较大,视觉上更容易区分出不同的标签类别
-
标签的分类主要看相同颜色的折线是否集中,若在某个属性上相同颜色折线较为集中,不同颜色有一定的间距,则说明该属性对于预测标签类别有较大的帮助
-
若某个属性上线条混乱,颜色混杂,则较大可能该属性对于标签类别判定没有价值