Sklearn 与 TensorFlow 机器学习实用指南——第十三章总结_卷积神经网络
在本章中,我们将介绍 CNN 的来源,构建它们模块的外观以及如何使用 TensorFlow 实现它们。然后我们将介绍一些最好的 CNN 架构。参考 地址
视觉皮层的结构
David H.Hubel 和 Torsten Wiesel 在 1958 年和 1959 年对猫进行了一系列实验,对视觉皮层的结构提供了重要的见解。
具体来说,他们发现视皮层中的许多神经元有一个小的局部感受野,这意味着它们只对位于视野中有限的一部分区域的视觉刺激起作用(见图 13-1,五个神经元的局部感受野由虚线圆圈表示)。不同神经元的感受野可能重叠,并且它们一起平铺了整个视野。
此外,作者表明,一些神经元只对水平线方向的图像作出反应,而另一些神经元只对不同方向的线作出反应(两个神经元可能具有相同的感受野,但对不同方向的线作出反应)。他们还注意到一些神经元具有较大的感受野,并且它们对较复杂的模式作出反应,这些模式是较低层模式的组合。
这些观察结果让我们想到:更高级别的神经元是基于相邻低级神经元的输出(在图 13-1 中,请注意,每个神经元只与来自前一层的少数神经元相连)。这个强大的结构能够检测视野中任何区域的各种复杂图案。

这些研究启发了 后来的的新认知机(neocognitron),逐渐演变为卷积神经网络。一个重要的里程碑是 Yann LeCun等人于 1998 年发表的一篇论文,该论文引入了着名的 LeNet-5 架构,广泛用于识别手写支票号码。这个架构有一些我们已经知道的模块,比如全连接层和 Sigmoid 激活函数,但是它还引入了两个新的构建块:卷积层和池化层。现在我们来看看他们。
卷积层
CNN 最重要的组成部分是卷积层:第一卷积层中的神经元不是连接到输入图像中的每一个像素,而是仅仅连接到它们的局部感受野中的像素(参见下图)。进而,第二卷积层中的每个神经元只与位于第一层中的小矩形内的神经元连接。这种架构允许网络专注于第一隐藏层中的低级特征,然后将其组装成下一隐藏层中的高级特征,等等。

前面介绍的多层神经网络层都散一长串神经元,比如MNIST输入到神经网络之前我们将其压缩为1D。现在,每个图层都以 2D 表示,这使得神经元与其相应的输入进行匹配变得更加容易。
位于给定层的第i行第j列的神经元连接到位于前一层中的神经元的输出的第i行到第 行,第j列到第 列。 和 是局部感受野的高度和宽度(见图 13-3)。 为了使图层具有与前一图层相同的高度和宽度,通常在输入周围添加零,如图所示。

如下图所示,通过将局部感受野隔开,还可以将较大的输入层连接到更小的层。 两个连续的感受野之间的距离被称为布长。 在图中,一个5×7的输入层(加零填充)连接到一个3×4层,使用3×3的卷积核和一个布长为 2(在这个例子中,步幅在两个方向是相同的,但是它并不一定总是如此)。 位于上层第i行第j列的神经元与位于前一层中的神经元的输出连接的第 至 行,第 列, 和 是垂直和水平的步幅。

卷积核/过滤器
神经元的权重可以表示为局部感受野大小的小图像。 例如,图 13-5 显示了两个可能的权重集,称为过滤器(或卷积核)。第一个表示为中间有一条垂直的白线的黑色正方形(除了中间一列外,这是一个充满 0 的7×7矩阵,除了中央垂直线是 1)。使用这些权重的神经元会忽略除了中央垂直线以外感受野的一切(因为除位于中央垂直线以外,所有的输入都将乘 0)。第二个卷积核是一个黑色的正方形,中间有一条水平的白线。 再一次,使用这些权重的神经元将忽略除了中心水平线之外的局部感受野中的一切。

现在,如果一个图层中的所有神经元都使用相同的垂直线卷积核(以及相同的偏置项),并且将网络输入到图 13-5(底部图像)中所示的输入图像,则该图层将输出左上图像。 请注意,垂直的白线得到增强,其余的变得模糊。 类似地,如果所有的神经元都使用水平线卷积核,你就会得到右上角的图像。注意到水平的白线得到增强,其余的则被模糊了。因此,使用相同卷积和的一个充满神经元的图层将为您提供一个特征映射,该特征映射突出显示图像中与卷积和最相似的区域。 在训练过程中,CNN 为其任务找到最有用的卷积和,并学习将它们组合成更复杂的模式(例如,交叉是图像中垂直卷积和和水平卷积和都激活的区域)。
叠加的多个特征映射
为了简单起见,我们将每个卷积层表示为一个薄的二维层,但是实际上它是由几个相同大小的特征映射组成的,所以使用3D图表示其会更加准确(见图 13-6)。
在一个特征映射中,所有神经元共享相同的参数(权重和偏置,权值共享),但是不同的特征映射可能具有不同的参数。 神经元的感受野与前面描述的相同,但是它延伸到所有先前的层的特征映射。 简而言之,卷积层同时对其输入应用多个卷积核,使其能够检测输入中的任何位置的多个特征。

事实上,特征地图中的所有神经元共享相同的参数会显着减少模型中的参数数量,但最重要的是,一旦 CNN 学会识别一个位置的模式,就可以在任何其他位置识别它。 相比之下,一旦一个常规 DNN 学会识别一个位置的模式,它只能在该特定位置识别它。
具体地,L-1层
行,
列神经元的输出连接到L层的 i 行 j 列。
下式给出了如何计算卷积层中神经元的输出
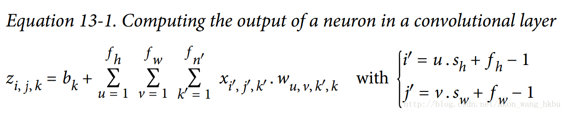
w是卷积核的连接权重。
TensorFlow 实现
一般图像都有上三个通道RGB,因而在tensorflow中,每个输入图像的通常被表示为三维张量 [height, width, channels]。那么一个小批次就被表示为四维张量[mini-batch, height, width, channels]。卷积层的权重表示为四维张量 [ ],卷积层的偏差项简单地表示为一维形状的张量[ ]。
我们来看一个简单的例子。 下面的代码使用 Scikit-Learn 的load_sample_images()加载两个样本图像。 然后创建两个7×7的卷积核(一个中间是垂直的白线,另一个是水平的白线),并将他们应用到两张图形中,使用 TensorFlow 的conv2d()函数构建的卷积图层(使用零填充且步幅为 2)。 最后,绘制其中一个结果特征映射(类似于图 13-5 中的右上图)。
from sklearn.datasets import load_sample_image
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
if __name__ == '__main__':
# Load sample images
china = load_sample_image("china.jpg")
flower = load_sample_image("flower.jpg")
dataset = np.array([china, flower], dtype=np.float32)
batch_size, height, width, channels = dataset.shape
# Create 2 filters
filters = np.zeros(shape=(7, 7, channels, 2), dtype=np.float32)
filters[:, 3, :, 0] = 1 # vertical line
filters[3, :, :, 1] = 1 # horizontal line
# Create a graph with input X plus a convolutional layer applying the 2 filters
X = tf.placeholder(tf.float32, shape=(None, height, width, channels))
convolution = tf.nn.conv2d(X, filters, strides=[1,2,2,1], padding="SAME")
with tf.Session() as sess:
output = sess.run(convolution, feed_dict={X: dataset})
plt.imshow(output[0, :, :, 1], cmap="gray") # plot 1st image's 2nd feature map
plt.show()
卷积图层有很多超参数:你必须选择卷积核的数量,高度和宽度,步幅和填充类型。 与往常一样,可以使用交叉验证来查找正确的超参数值,但这非常耗时。 稍后我们将讨论常见的 CNN 体系结构,以便了解超参数值在实践中的最佳工作方式。
内存需求
CNN 的另一个问题是卷积层需要大量的 RAM,特别是在训练期间,因为反向传播需要在正向传递期间计算的所有中间值。
在对新实例进行预测,一旦下一层计算完毕,一层所占用的 RAM 就可以被释放,因此只需要两个连续层所需的 RAM 数量。 但是在训练期间,在正向传递期间计算的所有内容都需要被保留用于反向传递,所以所需的 RAM 量(至少)是所有层所需的 RAM 总量。
如果由于内存不足错误导致训练崩溃,则可以尝试减少小批量大小。 或者,您可以尝试使用步幅降低维度,或者删除几个图层。 或者你可以尝试使用 16 位浮点数而不是 32 位浮点数。 或者你可以在多个设备上分发 CNN。
池化层
池化层的目标是对输入图像进行二次抽样(即收缩)以减少计算负担,内存使用量和参数数量(从而限制过度拟合的风险)。 减少输入图像的大小也使得神经网络容忍一点点的图像变换(位置不变)。
就像在卷积图层中一样,池化层中的每个神经元都连接到前一层中有限数量的神经元的输出,位于一个小的矩形感受野内。 您必须像以前一样定义其大小,跨度和填充类型。 但是,汇集的神经元没有权重; 它所做的只是使用聚合函数(如最大值或平均值)来聚合输入。
图 13-8 显示了最大池层,这是最常见的池化类型。 在这个例子中,我们使用一个2×2的核,步幅为 2,没有填充。 请注意,只有每个核中的最大输入值才会进入下一层。 其他输入被丢弃。

这显然是一个非常具有破坏性的层:即使只有一个2×2的核和 2 的步幅,输出在两个方向上都会变为原来的1/2(所以它的面积将变为原来的1/4),一下减少了 75% 的输入值。
池化层通常独立地在每个输入通道上工作,因此输出深度与输入深度相同。 您也可以在深度维度上进行合并,如下所示,在这种情况下,图像的空间维度(高度和宽度)保持不变,但通道数量会减少。
在 TensorFlow 中实现一个最大池层是非常容易的
import numpy as np
from sklearn.datasets import load_sample_image
import tensorflow as tf
import matplotlib.pyplot as plt
china = load_sample_image("china.jpg")
flower = load_sample_image("flower.jpg")
dataset = np.array([china, flower], dtype=np.float32)
batch_size, height, width, channels = dataset.shape
# Create 2 filters
filters = np.zeros(shape=(7, 7, channels, 2), dtype=np.float32)
filters[:, 3, :, 0] = 1 # vertical line
filters[3, :, :, 1] = 1 # horizontal line
X = tf.placeholder(tf.float32, shape=(None, height, width, channels))
max_pool = tf.nn.max_pool(X, ksize=[1,2,2,1], strides=[1,2,2,1],padding="VALID")
with tf.Session() as sess:
output = sess.run(max_pool, feed_dict={X: dataset})
plt.imshow(output[0].astype(np.uint8)) # plot the output for the 1st image
plt.show()
要创建一个平均池化层,只需将max_pool()换成avg_pool()函数。
CNN 架构
典型的 CNN 体系结构有一些卷积层(每一个通常跟着一个 ReLU 层),然后是一个池化层,然后是另外几个卷积层(+ ReLU),然后是另一个池化层,等等。 随着网络的进展,图像变得越来越小,但是由于卷积层的缘故,图像通常也会越来越深(即更多的特征映射)(见图 13-9)。 在堆栈的顶部,添加由几个全连接层(+ ReLU)组成的常规前馈神经网络,并且最终层输出预测(例如,输出估计类别概率的 softmax 层)。

通常情况下使用小卷积核比较好,比如可以通过将两个3×3核堆叠在一起来获得与5×5核相同的效果,计算量更少。
多年来,这种基础架构的变体已经被开发出来,导致了该领域的惊人进步。 这种进步的一个很好的衡量标准是比赛中的错误率,比如 ILSVRC ImageNet 的挑战。 在这个比赛中,图像分类的五大误差率在五年内从 26% 下降到仅仅 3% 左右。
我们来看看经典的 LeNet-5 架构(1998 年),还有ILSVRC 挑战赛的三名获胜者 AlexNet(2012),GoogLeNet(2014)和 ResNet(2015),查看**地址**。
TensorFlow 卷积操作
TensorFlow 还提供了一些其他类型的卷积层:
- conv1d()为 1D 输入创建一个卷积层。 例如,在自然语言处理中这是有用的,其中句子可以表示为一维单词阵列,并且接受场覆盖一些邻近单词。
- conv3d()创建一个 3D 输入的卷积层,如 3D PET 扫描。
- atrous_conv2d()创建了一个 atrous 卷积层。这相当于使用具有通过插入行和列(即,孔)而扩大的卷积核的普通卷积层。 例如,等于[[1,2,3]]的1×3卷积核可以以4的扩张率扩张,导致扩张的卷积核[[1,0,0,0,2,0,0,0,3]]。这使得卷积层在没有计算价格的情况下具有更大的局部感受野,并且不使用额外的参数。
- conv2d_transpose()创建了一个转置卷积层,有时称为去卷积层,它对图像进行上采样(这个名称是非常具有误导性的,因为这个层并不执行去卷积,这是一个定义良好的数学运算(卷积的逆))。这是通过在输入之间插入零来实现的,所以你可以把它看作是一个使用分数步长的普通卷积层。例如,在图像分割中,上采样是有用的:在典型的CNN中,特征映射越来越小当通过网络时,所以如果你想输出一个与输入大小相同的图像,你需要一个上采样层。
- depthwise_conv2d()创建一个深度卷积层,将每个卷积核独立应用于每个单独的输入通道。因此,如果有fn卷积核和fn’输入通道,那么这将输出fn×fn’特征映射。
- separable_conv2d()创建一个可分离的卷积层,首先像深度卷积层一样工作,然后将1×1卷积层应用于结果特征映射。这使得可以将卷积核应用于任意的输入通道组。
本章主要介绍了卷积和池化两个概念,并使用tensorflow进行另实现,随后介绍了几种在图像分类ILSVRC 挑战赛中出现的CNN架构,在之后关于图像的相关深度学习研究中,我们就可以复用这些基础网络进行提取特征。