Sklearn 与 TensorFlow 机器学习实用指南——第十五章总结
自编码器是能够在无监督的情况下学习输入数据的有效表示(叫做编码)的人工神经网络(即,训练集是未标记),即一个输出等于输入的网络。这些编码通常具有比输入数据低得多的维度,使得自编码器对降维有用(参见第 8 章)。
在本章中,我们将更深入地解释自编码器如何工作,可以施加什么类型的约束以及如何使用 TensorFlow 实现它们,无论是用来降维,特征提取,无监督预训练还是作为生成式模型。参考地址
有效的数据表示
自编码器是一个输出等于输入的网络,而中间层是输入的高效表达。自编码器总是由两部分组成:将输入转换为内部表示的编码器(或识别网络),然后是将内部表示转换为输出的解码器(或生成网络)(见图 15-1)。
可以看到,自编码器和多层感知器(MLP,第10章)有着相同的结构,但是输出层中的神经元数量等于输入数量,因为输出等于输入。在这个例子中,只有一个由两个神经元(编码器)组成的隐藏层和一个由三个神经元(解码器)组成的输出层。 由于自编码器试图重构输入,所以输出通常被称为重建,并且损失函数包含重建损失,当重建与输入不同时,重建损失会对模型进行惩罚。

为了防止自编码器简单地将输入复制到编码,隐含层通常比输入数据具有更低的维度(比如上图时2D而不是3D),它被迫学习输入数据中最重要的特征(并删除不重要的特征)。
用不完整的线性自编码器执行 PCA
如果自编码器仅使用线性激活并且损失函数是均方误差(MSE),则可以显示它最终执行主成分分析(参见第 8 章)。
以下代码构建了一个简单的线性自编码器,以在 3D 数据集上执行 PCA,并将其投影到 2D:
import tensorflow as tf
reset_graph()
n_inputs = 3 # 3D inputs
n_hidden = 2 # 2D codings
n_outputs = n_inputs
learning_rate = 0.01
X = tf.placeholder(tf.float32, shape=[None, n_inputs])
hidden = tf.layers.dense(X, n_hidden)
outputs = tf.layers.dense(hidden, n_outputs)
# 损失函数为MSE
reconstruction_loss = tf.reduce_mean(tf.square(outputs - X))
optimizer = tf.train.AdamOptimizer(learning_rate)
training_op = optimizer.minimize(reconstruction_loss)
init = tf.global_variables_initializer()
需要注意的两件事:
- 输出的数量等于输入的数量
- 为了执行简单的 PCA,我们设置activation_fn = None(即,所有神经元都是线性的)

图 15-2 显示了原始 3D 数据集(左侧)和自编码器隐藏层的输出(即编码层,右侧)。 正如您所看到的,自编码器找到了将数据投影到数据上的最佳二维平面,保留了数据的尽可能多的差异(就像 PCA 一样)。
栈式自编码器(SAE)
像前面讨论的神经网络一样,自编码器可以有多个隐藏层。 在这种情况下,它们被称为栈式自编码器(或深度自编码器),添加更多层有助于自编码器了解更复杂的编码。
栈式自编码器的架构关于中央隐藏层(编码层)通常是对称的。例如,一个用于 MNIST 的自编码器(在第 3 章中介绍)可能有 784 个输入,其次是一个隐藏层,有 300 个神经元,然后是一个中央隐藏层,有 150 个神经元,然后是另一个隐藏层,有 300 个神经元,输出层有 784 神经元。 这个栈式自编码器如图 15-3 所示。

TensorFlow实现
我们可以像常规深度 MLP一样实现栈式自编码器。特别是,我们在第 11 章中用于训练深度网络的技术也可以应用。例如,下面的代码使用 He 初始化,ELU 激活函数和 l2 正则化为 MNIST 构建一个栈式自编码器。 代码应该看起来很熟悉,除了没有标签(没有y):
reset_graph()
from functools import partial
n_inputs = 28 * 28
n_hidden1 = 300
n_hidden2 = 150 # codings
n_hidden3 = n_hidden1
n_outputs = n_inputs
learning_rate = 0.01
l2_reg = 0.0001
X = tf.placeholder(tf.float32, shape=[None, n_inputs])
he_init = tf.contrib.layers.variance_scaling_initializer() # He initialization
#Equivalent to:
#he_init = lambda shape, dtype=tf.float32: tf.truncated_normal(shape, 0., stddev=np.sqrt(2/shape[0]))
l2_regularizer = tf.contrib.layers.l2_regularizer(l2_reg)
my_dense_layer = partial(tf.layers.dense,
activation=tf.nn.elu,
kernel_initializer=he_init,
kernel_regularizer=l2_regularizer)
hidden1 = my_dense_layer(X, n_hidden1)
hidden2 = my_dense_layer(hidden1, n_hidden2)
hidden3 = my_dense_layer(hidden2, n_hidden3)
outputs = my_dense_layer(hidden3, n_outputs, activation=None)
reconstruction_loss = tf.reduce_mean(tf.square(outputs - X)) # 注意这里的误差,计算的是输出与输入间的重建误差,不再是输出与标签之间的
reg_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
loss = tf.add_n([reconstruction_loss] + reg_losses)
optimizer = tf.train.AdamOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
关联权重
当自编码器整齐地对称时,就像我们刚刚构建的那样,一种常用技术是将解码器层的权重与编码器层的权重相关联。 这样减少了模型中的权重数量,加快了训练速度,并限制了过度拟合的风险。
具体来说,如果自编码器总共具有N个层(不计入输入层),并且 W{[L]}表示第L层的连接权重(例如,层 1 是第一隐藏层,则层N / 2是编码层,而层N是输出层),则解码器层权重可以简单地定义为:W^{[N-L + 1]}=W{[L]T}^(转置),(其中L = 1, 2, …, N2)。
TensorFlow中没有这样的函数,我们可以手动定义:
weights1_init = initializer([n_inputs, n_hidden1])
weights2_init = initializer([n_hidden1, n_hidden2])
weights1 = tf.Variable(weights1_init, dtype=tf.float32, name="weights1")
weights2 = tf.Variable(weights2_init, dtype=tf.float32, name="weights2")
weights3 = tf.transpose(weights2, name="weights3") # 关联权重 tied weights
weights4 = tf.transpose(weights1, name="weights4") # tied weights
biases1 = tf.Variable(tf.zeros(n_hidden1), name="biases1")
biases2 = tf.Variable(tf.zeros(n_hidden2), name="biases2")
biases3 = tf.Variable(tf.zeros(n_hidden3), name="biases3")
biases4 = tf.Variable(tf.zeros(n_outputs), name="biases4")
hidden1 = activation(tf.matmul(X, weights1) + biases1) # 激活函数
hidden2 = activation(tf.matmul(hidden1, weights2) + biases2)
hidden3 = activation(tf.matmul(hidden2, weights3) + biases3)
outputs = tf.matmul(hidden3, weights4) + biases4
其余部分大致相同,可以看到:
- 权重 3 和权重 4 不是变量,它们分别是权重 2 和权重 1 的转置(它们与它们“绑定”);
- 由于它们不是变量,所以规范它们是没有用的:我们只调整权重 1 和权重 2;
- 偏置永远不会被束缚,并且永远不会正规化。
一次训练一个自编码器
对于栈式自编码器的训练,不是一次完成的,而是一次训练一个浅自编码器,然后将所有的编码器堆叠在一个栈式编码器中(因此得名),通常要快得多。

在训练的第一阶段,第一个自编码器学习重构输入。 在第二阶段,第二个自编码器学习重构第一个自编码器隐藏层的输出。最后,只需使用所有这些自编码器来构建一个大三明治,如图 15-4 所示(即,您首先将每个自编码器的隐藏层,然后按相反顺序堆叠输出层)。 这给你最后的栈式自编码器。 您可以用这种方式轻松地训练更多的自编码器,构建一个非常深的栈式自编码器。
为了实现这种多阶段训练算法,最简单的方法是对每个阶段使用不同的 TensorFlow 图。训练完一个自编码器后,您只需通过它运行训练集并捕获隐藏层的输出。这个输出作为下一个自编码器的训练集。一旦所有自编码器都以这种方式进行了训练,您只需复制每个自编码器的权重和偏置,然后使用它们来构建堆叠的自编码器。
另一种方法是使用包含整个栈式自编码器的单个图,以及执行每个训练阶段的一些额外操作,如图 15-5 所示。

这值得解释一下:
- 图中的中央列是完整的栈式自编码器。这部分可以在训练后使用;
- 左列是运行第一阶段训练所需的一系列操作。它创建一个绕过隐藏层 2 和 3 的输出层。该输出层与堆叠的自编码器的输出层共享相同的权重和偏置。此外还有旨在使输出尽可能接近输入的训练操作。因此,该阶段将训练隐藏层1和输出层(即,第一自编码器)的权重和偏置;
- 图中的右列是运行第二阶段训练所需的一组操作。它增加了训练操作,目的是使隐藏层 3 的输出尽可能接近隐藏层 1 的输出。注意,我们必须在运行阶段 2 时冻结隐藏层 1。此阶段将训练隐藏层 2 和 3 的权重和偏置(即第二自编码器)。
这一部分理解起来比较难,看对应的参考代码辅助理解。
无监督预训练使用栈式自编码器
正如在第 11 章中讨论的那样,如果你正在处理复杂的监督任务,但却没有大量标记的训练数据,则一种解决方案是找到执行类似任务的神经网络,然后重新使用其较低层。 这样就可以仅使用很少的训练数据来训练高性能模型,因为你的神经网络不必学习所有的低级特征。
同样,如果你有一个大型数据集,但大多数数据集未标记,可以先使用所有数据训练栈式自编码器,然后重新使用较低层为实际任务创建一个神经网络,并使用标记数据对其进行训练。
例如,图 15-8 显示了如何使用栈式自编码器为分类神经网络执行无监督预训练。

降噪自编码(DAE)
另一种强制自编码器学习有用功能的方法是为其输入添加噪声,对其进行训练以恢复原始的无噪声输入。 这可以防止自编码器将其输入复制到其输出,因此最终不得不在数据中查找模式。
噪声可以是纯粹的高斯噪声添加到输入,或者它可以随机关闭输入,就像 drop out(在第 11 章介绍)。 图 15-9 显示了这两个选项。

在 TensorFlow 中实现去噪自编码器并不难。 我们从高斯噪声开始。 这实际上就像训练一个常规的自编码器一样,除了给输入添加噪声外,重建损耗是根据原始输入计算的:
noise_level = 1.0
X = tf.placeholder(tf.float32, shape=[None, n_inputs])
X_noisy = X + noise_level * tf.random_normal(tf.shape(X))
hidden1 = tf.layers.dense(X_noisy, n_hidden1, activation=tf.nn.relu,
name="hidden1")
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, # not shown in the book
name="hidden2") # not shown
hidden3 = tf.layers.dense(hidden2, n_hidden3, activation=tf.nn.relu, # not shown
name="hidden3") # not shown
outputs = tf.layers.dense(hidden3, n_outputs, name="outputs") # not shown
reconstruction_loss = tf.reduce_mean(tf.square(outputs - X)) # MSE
optimizer = tf.train.AdamOptimizer(learning_rate)
training_op = optimizer.minimize(reconstruction_loss)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
稀疏自编码器
通常良好特征提取的另一种约束是稀疏性:通过向损失函数添加适当的项,自编码器被推动以减少编码层中活动神经元的数量。 例如,它可能被推到编码层中平均只有 5% 的显著活跃的神经元。
为了支持稀疏模型,我们必须首先在每次训练迭代中测量编码层的实际稀疏度。 我们通过计算整个训练批次中编码层中每个神经元的平均激活来实现。 批量大小不能太小,否则平均数不准确。
一旦我们对每个神经元进行平均激活,我们希望通过向损失函数添加稀疏损失来惩罚太活跃的神经元。例如,如果我们测量一个神经元的平均激活值为 0.3,但目标稀疏度为 0.1,那么它必须受到惩罚才能激活更少。一种方法可以简单地将平方误差(0.3-0.1)^2添加到损失函数中,但实际上更好的方法是使用 Kullback-Leibler 散度(在第 4 章中简要讨论),其具有比均方误差更强的梯度,如图 15-10 所示。

给定两个离散的概率分布P和Q,这些分布之间的 KL 散度,记为Dkl(P || Q),可以使用公式 15-1 计算。
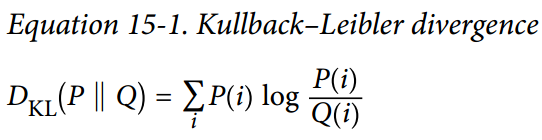
在我们的例子中,我们想要测量编码层中的神经元将激活的目标概率p与实际概率q(即,训练批次上的平均激活)之间的差异。 所以KL散度简化为公式 15-2。
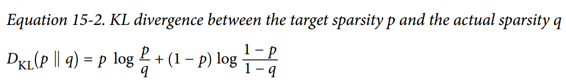
TensorFlow实现:
def kl_divergence(p, q):
# Kullback Leibler divergence
return p * tf.log(p / q) + (1 - p) * tf.log((1 - p) / (1 - q))
learning_rate = 0.01
sparsity_target = 0.1
sparsity_weight = 0.2
X = tf.placeholder(tf.float32, shape=[None, n_inputs]) # not shown in the book
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.sigmoid) # not shown
outputs = tf.layers.dense(hidden1, n_outputs) # not shown
hidden1_mean = tf.reduce_mean(hidden1, axis=0) # batch mean
sparsity_loss = tf.reduce_sum(kl_divergence(sparsity_target, hidden1_mean))
reconstruction_loss = tf.reduce_mean(tf.square(outputs - X)) # MSE
loss = reconstruction_loss + sparsity_weight * sparsity_loss
optimizer = tf.train.AdamOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
由于计算KL散度需要概率值(0~1),所以隐含层的输出应该介于0和1之间,因而激活函数使用sigmoid函数。
变分自编码器(VAE)
Diederik Kingma 和 Max Welling 于 2014 年推出了另一类重要的自编码器,并迅速成为最受欢迎的自编码器类型之一:变分自编码器。
我们来看看他们是如何工作的。 图 15-11(左)显示了一个变分自编码器。有一个特殊的地方:不是直接为给定的输入生成编码 ,编码器产生平均编码μ和标准差σ。然后从平均值μ和标准差σ的高斯分布中随机采样实现编码。之后,解码器正常解码采样的编码。该图的右侧部分显示了一个训练实例通过此自编码器。首先,编码器产生μ和σ,随后对编码进行随机采样(注意它不是完全位于μ处),最后对编码进行解码,最终的输出与训练实例类似。

从图中可以看出,尽管输入可能具有非常复杂的分布,但变分自编码器倾向于产生编码,看起来好像它们是从简单的高斯分布采样的:在训练期间,损失函数推动编码在编码空间(也称为潜在空间)内逐渐迁移以占据看起来像高斯点集成的云的大致(超)球形区域。一个重要的结果是,在训练了一个变分自编码器之后,你可以很容易地生成一个新的实例:只需从高斯分布中抽取一个随机编码,对它进行解码就可以了!
损失函数由两部分组成。 首先是通常的重建损失,推动自编码器重现其输入(我们可以使用交叉熵来解决这个问题,如前所述)。第二种是潜在的损失,推动自编码器使编码看起来像是从简单的高斯分布中采样,为此我们使用目标分布(高斯分布)与编码实际分布之间的 KL 散度。数学比以前复杂一点,特别是因为高斯噪声,它限制了可以传输到编码层的信息量(从而推动自编码器学习有用的特征)。幸运的是,这些方程简化为下面的潜在损失代码(不明觉厉):
eps = 1e-10 # smoothing term to avoid computing log(0) which is NaN
latent_loss = 0.5 * tf.reduce_sum(tf.square(hidden3_sigma) + tf.square(hidden3_mean) - 1 - tf.log(eps + tf.square(hidden3_sigma)))
一种常见的变体是训练编码器输出γ= log(σ^2)而不是σ。 只要我们需要σ,我们就可以计算σ= exp(2/γ)。 这使得编码器可以更轻松地捕获不同比例的σ,从而有助于加快收敛速度。 潜在损失结束会变得更简单一些:
latent_loss = 0.5 * tf.reduce_sum(tf.exp(hidden3_gamma) + tf.square(hidden3_mean) - 1 - hidden3_gamma)
以下代码使用log(σ^2)变体构建图 15-11(左)所示的变分自编码器:
reset_graph()
from functools import partial
n_inputs = 28 * 28
n_hidden1 = 500
n_hidden2 = 500
n_hidden3 = 20 # codings
n_hidden4 = n_hidden2
n_hidden5 = n_hidden1
n_outputs = n_inputs
learning_rate = 0.001
initializer = tf.contrib.layers.variance_scaling_initializer()
my_dense_layer = partial(
tf.layers.dense,
activation=tf.nn.elu,
kernel_initializer=initializer)
X = tf.placeholder(tf.float32, [None, n_inputs])
hidden1 = my_dense_layer(X, n_hidden1)
hidden2 = my_dense_layer(hidden1, n_hidden2)
# 均值
hidden3_mean = my_dense_layer(hidden2, n_hidden3, activation=None)
# 标准差
hidden3_sigma = my_dense_layer(hidden2, n_hidden3, activation=None)
# 以标准差sigma产生高斯噪声(尺寸也相同)
noise = tf.random_normal(tf.shape(hidden3_sigma), dtype=tf.float32)
hidden3 = hidden3_mean + hidden3_sigma * noise
hidden4 = my_dense_layer(hidden3, n_hidden4)
hidden5 = my_dense_layer(hidden4, n_hidden5)
logits = my_dense_layer(hidden5, n_outputs, activation=None)
outputs = tf.sigmoid(logits)
# 交叉熵 重建损失
xentropy = tf.nn.sigmoid_cross_entropy_with_logits(labels=X, logits=logits)
reconstruction_loss = tf.reduce_sum(xentropy)
eps = 1e-10 # smoothing term to avoid computing log(0) which is NaN
# 潜在的损失,促使自编码器时编码看起来像从高斯分布中采样
latent_loss = 0.5 * tf.reduce_sum(tf.square(hidden3_sigma) + tf.square(hidden3_mean) - 1 - tf.log(eps + tf.square(hidden3_sigma)))
loss = reconstruction_loss + latent_loss
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
training_op = optimizer.minimize(loss)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
其他自编码器
监督式学习在图像识别,语音识别,文本翻译等方面取得的惊人成就在某种程度上掩盖了无监督学习的局面,但它实际上正在蓬勃发展。 自编码器和其他无监督学习算法的新体系结构定期发明,以至于我们无法在本书中全面介绍它们。 以下是几种类型的自编码器的简要说明(绝非详尽无遗):
- 压缩自编码器(CAE),自编码器在训练过程中受到约束,因此与输入有关的编码的导数很小。 换句话说,两个类似的输入必须具有相似的编码。
- 栈式卷积自编码器(SCAE),学习通过重构通过卷积层处理的图像来提取视觉特征的自编码器。
- 生成随机网络(GSN),消除自编码器的泛化,增加了生成数据的能力。
- 赢家通吃(WTA)的自编码,在训练期间,在计算编码层中所有神经元的激活之后,只保留训练批次上每个神经元的前 k% 激活,其余部分设为零。 自然这导致稀疏的编码。 而且,可以使用类似的 WTA 方法来产生稀疏卷积自编码器。
- 对抗自编码器(AAE),一个网络被训练来重现它的输入,同时另一个网络被训练去找到第一个网络不能正确重建的输入。 这推动了第一个自编码器学习健壮的编码。
本章主要介绍了自动编码器及其几种变体,Tensorflow实现等内容。