一、引入
1.论文
AlexNet (https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf),
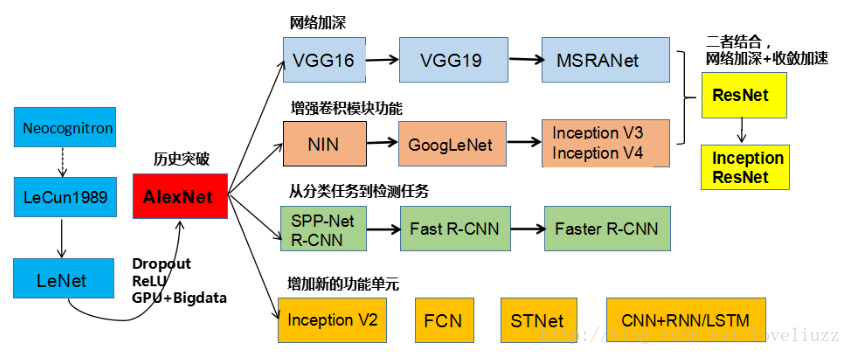
2. 特点
(1)针对网络架构:
- 使用ReLU作为CNN激活函数:验证其效果在较深的网络要优于Sigmoid;非饱和非线性函数训练速度快于饱和非线性函数。
- 使用LRN层:对局部神经元的活动创建竞争机制,使得其中响应比较大的值变的相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
- 使用重叠的最大池化:让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性,防止过拟合。
(2)针对过拟合现象:
- 数据增强:对原始图像随机的截取输入图片尺寸大小(以及对图像作水平翻转操作),使用数据增强后大大减轻过拟合,提升模型的泛化能力。
- 使用Dropout随机忽略一部分神经元:避免模型过拟合。
(3)针对训练速度:
- 使用GPU计算,加快计算速度。
二、tensorflow实现
1.实现计算前向预测和反向测评时间
(1)导入时间和tensorflow
from datetime import datetime
import math
import time
import tensorflow as tf(2) 设置参数
batch_size = 32 #每个batch数据的大小
num_batches = 100 #一共测试100个batch数据(3) 封装Alex用到的函数
def conv_op(input, name, wh, ww, n_out, dh, dw, p): #输入,范围名称,滤波器尺寸,滤波器输出通道数,步长,参数列表
n_in = input.get_shape()[-1].value #输入通道数
with tf.name_scope(name) as scope:
weight = tf.Variable(tf.truncated_normal([wh, ww, n_in, n_out], dtype=tf.float32, stddev=1e-1), name='weight') #滤波器
conv = tf.nn.conv2d(input, weight, (1, dw, dw, 1),padding='SAME') #步长 必须是边界填充SAME
bias_init_val = tf.constant(0.0, shape=[n_out],dtype=tf.float32)
biases = tf.Variable(bias_init_val, trainable=True, name='b') #偏置
result = tf.nn.bias_add(conv, biases) #前向
activation = tf.nn.relu(result, name=scope) #非线性激活
p += [weight, biases] #参数
return activation
def lrn_op(input, name):
lrn = tf.nn.lrn(input, 4, bias=1.0, alpha=0.001/9, beta=0.75, name=name) #lrn:都是论文推荐值
return lrn
def pool_op(input, name, wh, ww, dh, dw):
pool = tf.nn.max_pool(input, ksize=[1, wh, ww, 1], strides=[1, dw, dh, 1], padding='VALID', name=name) #池化 尺寸 步长 必须是不填充VALID
return pool
def fc_op(input, name, n_out, p): #全连接
n_in = input.get_shape()[-1].value #通道数
with tf.name_scope(name) as scope:
weight = tf.Variable(tf.truncated_normal([n_in, n_out], dtype=tf.float32, stddev=1e-2), name='weight')
bias_init_val = tf.constant(0.1, shape=[n_out], dtype=tf.float32)
biases = tf.Variable(bias_init_val, name='b')
activation = tf.nn.relu_layer(input, weight, biases, name=scope)
p += [weight, biases]
return activation(4) Alex特征提取:5卷积 3全连接
def inference(images, keep_prob):
parameters = [] #参数
#卷积1
conv1 = conv_op(images, name='conv1', wh=11, ww=11, n_out=96, dh=4, dw=4, p=parameters)
lrn1 = lrn_op(conv1, name='lrn1')
pool1 = pool_op(lrn1, name='pool1', wh=3, ww=3, dh=2, dw=2)
#卷积2
conv2 = conv_op(pool1, name='conv2', wh=5, ww=5, n_out=256, dh=2, dw=2, p=parameters)
lrn2 = lrn_op(conv2, name='lrn2')
pool2 = pool_op(lrn2, name='pool2', wh=3, ww=3, dh=2, dw=2)
# 卷积3
conv3 = conv_op(pool2, name='conv3', wh=3, ww=3, n_out=384, dh=1, dw=1, p=parameters)
# 卷积4
conv4 = conv_op(conv3, name='conv4', wh=3, ww=3, n_out=384, dh=1, dw=1, p=parameters)
# 卷积5
conv5 = conv_op(conv4, name='conv5', wh=3, ww=3, n_out=256, dh=1, dw=1, p=parameters)
lrn5 = lrn_op(conv5, name='lrn5')
pool5 = pool_op(lrn5, name='pool5', wh=3, ww=3, dh=2, dw=2)
#全连接:扁平化处理成1维向量
shp = pool5.get_shape()
flattened_shape = shp[1].value * shp[2].value * shp[3].value
resh1 = tf.reshape(pool5, [-1,flattened_shape], name='resh1') #转换为一维
fc1 = fc_op(resh1, name='fc1', n_out=4096, p=parameters)
fc1_drop = tf.nn.dropout(fc1, keep_prob, name='fc1_drop')
fc2 = fc_op(fc1_drop, name='fc2', n_out=4096, p=parameters)
fc2_drop = tf.nn.dropout(fc2, keep_prob, name='fc2_drop')
fc3 = fc_op(fc2_drop, name='fc3', n_out=1000, p=parameters)
softmax = tf.nn.softmax(fc3) #预测值
predictions = tf.argmax(softmax, 1) #返回最大值的索引号
return predictions, parameters, fc3(5)时间间隔函数
def time_tensorflow_run(session, target, feed, info_string):
num_steps_burn_in = 10 # 设备热身,存在显存加载/cache命中等问题
total_duration = 0.0 # 总时间
total_duration_squared = 0.0 # 用于计算方差
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target, feed_dict=feed)
duration = time.time() - start_time
if i >= num_steps_burn_in:
if not i % 10:
print('%s: step %d, duration = %.3f' %
(datetime.now(), i - num_steps_burn_in, duration))
total_duration += duration
total_duration_squared += duration * duration
mn = total_duration / num_batches
vr = total_duration_squared / num_batches - mn * mn
sd = math.sqrt(vr)
print('%s: %s across %d steps, %.3f +/- %.3f sec / batch' %
(datetime.now(), info_string, num_batches, mn, sd))
(6) 会话运行
def run_benchmark():
with tf.Graph().as_default():
image_size = 224
images = tf.Variable(tf.random_normal([batch_size,
image_size,
image_size, 3],
dtype=tf.float32,
stddev=1e-1))
keep_prob = tf.placeholder(tf.float32) #必须占位
predictions, parameters, fc3 = inference(images, keep_prob)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
time_tensorflow_run(sess, predictions, {keep_prob: 1.0}, "Forward") #预测用keep_prob=1.0
objective = tf.nn.l2_loss(fc3) #l2正则化必须计算每层输出,不能越级计算prediction,否则报错,格式不符。
grad = tf.gradients(objective, parameters) # 计算梯度(objective与parameters有相关)
time_tensorflow_run(sess, grad, {keep_prob: 0.5}, "Forward-backward") #评测用keep_prob=0.5
if __name__ == '__main__':
run_benchmark()(7)运行结果
2018-09-18 10:01:04.408404: step 0, duration = 0.699
2018-09-18 10:01:12.442118: step 10, duration = 0.826
2018-09-18 10:01:20.814070: step 20, duration = 0.805
2018-09-18 10:01:28.105761: step 30, duration = 0.824
2018-09-18 10:01:35.741192: step 40, duration = 0.870
2018-09-18 10:01:44.419362: step 50, duration = 0.949
2018-09-18 10:01:51.828631: step 60, duration = 0.707
2018-09-18 10:01:59.595154: step 70, duration = 0.859
2018-09-18 10:02:07.299633: step 80, duration = 0.899
2018-09-18 10:02:16.194959: step 90, duration = 1.009
2018-09-18 10:02:23.887428: Forward across 100 steps, 0.802 +/- 0.109 sec / batch
2018-09-18 10:03:05.413958: step 0, duration = 3.731
2018-09-18 10:03:55.454543: step 10, duration = 6.341
2018-09-18 10:04:42.905285: step 20, duration = 3.830
2018-09-18 10:05:21.209524: step 30, duration = 3.964
2018-09-18 10:06:03.452564: step 40, duration = 3.776
2018-09-18 10:06:43.287890: step 50, duration = 3.768
2018-09-18 10:07:20.795563: step 60, duration = 3.740
2018-09-18 10:08:02.258047: step 70, duration = 4.561
2018-09-18 10:08:42.556704: step 80, duration = 3.887
2018-09-18 10:09:25.965573: step 90, duration = 4.361
2018-09-18 10:10:01.336725: Forward-backward across 100 steps, 4.197 +/- 0.595 sec / batch
2.AlexNet在Mnist数据集上运行测试
因为MNIST数据集的图片展开为28*28*1,数据集上图片都较小,所有我们在卷积层和池化层的操作上都缩小了操作核的大小和步长,以保持图像的尺寸不会迅速崩塌。
在卷积层上缩小了卷积3*3,移动步长也都改为了1,池化层都使用了2*2,且移动步长也改为了1
(1)导入mnist
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data(2)设置参数
#设置参数 :共96000张图
step = 1500
batch_size = 64(3)封装Alex用到的函数
def conv_op(input, name, wh, ww, n_out, dh, dw, p): #输入,范围名称,滤波器尺寸,滤波器输出通道数,步长,参数列表
n_in = input.get_shape()[-1].value #输入通道数
with tf.name_scope(name) as scope:
weight = tf.Variable(tf.truncated_normal([wh, ww, n_in, n_out], dtype=tf.float32, stddev=1e-1), name='weight') #滤波器
conv = tf.nn.conv2d(input, weight, (1, dw, dw, 1),padding='SAME') #步长 必须是边界填充SAME
bias_init_val = tf.constant(0.0, shape=[n_out],dtype=tf.float32)
biases = tf.Variable(bias_init_val, trainable=True, name='b') #偏置
result = tf.nn.bias_add(conv, biases) #前向
activation = tf.nn.relu(result, name=scope) #非线性激活
p += [weight, biases] #参数
return activation
def lrn_op(input, name):
lrn = tf.nn.lrn(input, 4, bias=1.0, alpha=0.001/9, beta=0.75, name=name) #lrn:都是论文推荐值
return lrn
def pool_op(input, name, wh, ww, dh, dw):
pool = tf.nn.max_pool(input, ksize=[1, wh, ww, 1], strides=[1, dw, dh, 1], padding='VALID', name=name) #池化 尺寸 步长 必须是不填充VALID
return pool
def fc_op(input, name, n_out, p): #全连接
n_in = input.get_shape()[-1].value #通道数
with tf.name_scope(name) as scope:
weight = tf.Variable(tf.truncated_normal([n_in, n_out], dtype=tf.float32, stddev=1e-2), name='weight')
bias_init_val = tf.constant(0.1, shape=[n_out], dtype=tf.float32)
biases = tf.Variable(bias_init_val, name='b')
activation = tf.nn.relu_layer(input, weight, biases, name=scope)
p += [weight, biases]
return activation
(4)Alex特征提取
def inference(mnist, keep_prob):
parameters = [] #参数
mnist = tf.reshape(mnist, shape=[-1, 28, 28, 1])
#卷积1
conv1 = conv_op(mnist, name='conv1', wh=3, ww=3, n_out=64, dh=1, dw=1, p=parameters)
lrn1 = lrn_op(conv1, name='lrn1')
pool1 = pool_op(lrn1, name='pool1', wh=2, ww=2, dh=1, dw=1)
#卷积2
conv2 = conv_op(pool1, name='conv2', wh=3, ww=3, n_out=64, dh=1, dw=1, p=parameters)
lrn2 = lrn_op(conv2, name='lrn2')
pool2 = pool_op(lrn2, name='pool2', wh=2, ww=2, dh=1, dw=1)
# 卷积3
conv3 = conv_op(pool2, name='conv3', wh=3, ww=3, n_out=128, dh=1, dw=1, p=parameters)
# 卷积4
conv4 = conv_op(conv3, name='conv4', wh=3, ww=3, n_out=128, dh=1, dw=1, p=parameters)
# 卷积5
conv5 = conv_op(conv4, name='conv5', wh=3, ww=3, n_out=256, dh=1, dw=1, p=parameters)
lrn5 = lrn_op(conv5, name='lrn5')
pool5 = pool_op(lrn5, name='pool5', wh=2, ww=2, dh=1, dw=1)
#全连接:扁平化处理成1维向量
shp = pool5.get_shape() #格式有所变化
flattened_shape = shp[1].value * shp[2].value * shp[3].value
resh1 = tf.reshape(pool5, [-1,flattened_shape], name='resh1') #转换为一维
fc1 = fc_op(resh1, name='fc1', n_out=1024, p=parameters)
fc1_drop = tf.nn.dropout(fc1, keep_prob, name='fc1_drop')
fc2 = fc_op(fc1_drop, name='fc2', n_out=1024, p=parameters)
fc2_drop = tf.nn.dropout(fc2, keep_prob, name='fc2_drop')
fc3 = fc_op(fc2_drop, name='fc3', n_out=10, p=parameters)
softmax = tf.nn.softmax(fc3) #预测值
return softmax
(5)训练
note:格式转换:将训练数据reshape成单通道图片
def train(x, keep_prob):
x = tf.placeholder(tf.float32, [None, 784]) # 输入: MNIST数据图像为展开的向量 #格式转换
x_ = tf.reshape(x, shape=[-1, 28, 28, 1]) # 将训练数据reshape成单通道图片
y_ = tf.placeholder(tf.float32, [None, 10]) # 标签值:one-hot标签值
softmax = inference(x_, keep_prob)
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(softmax), reduction_indices=[1])) #损失
train_op = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct = tf.equal(tf.argmax(softmax, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32)) #准确率
with tf.Session() as sess:
tf.initialize_all_variables().run()
for i in range(step): #循环1500轮
xs, ys = mnist.train.next_batch(batch_size)
_, acc, los = sess.run([train_op, accuracy, cross_entropy], feed_dict={x: xs, y_: ys})
if i % 100 == 0: #每一百轮输出一次
print("After %d training step,loss is %6f,acc is %6f" % (i, los, acc)) #输出每100轮的结果
print('train over')
if __name__ == '__main__':
mnist = input_data.read_data_sets("D:/python/pycharm/venv/tmp/data", one_hot=True)
train(mnist, 0.5)(6)运行结果
After 0 training step,loss is 2.344332,acc is 0.046875
After 100 training step,loss is 0.311294,acc is 0.906250
After 200 training step,loss is 0.297705,acc is 0.890625
After 300 training step,loss is 0.146328,acc is 0.937500
After 400 training step,loss is 0.029096,acc is 1.000000
After 500 training step,loss is 0.167835,acc is 0.968750
After 600 training step,loss is 0.063780,acc is 0.984375
After 700 training step,loss is 0.164380,acc is 0.921875
After 800 training step,loss is 0.018011,acc is 1.000000
After 900 training step,loss is 0.002993,acc is 1.000000
After 1000 training step,loss is 0.022672,acc is 1.000000
After 1100 training step,loss is 0.110279,acc is 0.968750
After 1200 training step,loss is 0.094898,acc is 0.953125
After 1300 training step,loss is 0.044098,acc is 0.984375
After 1400 training step,loss is 0.045850,acc is 0.984375
train over