网络爬虫是当前互联网比较流行的概念,特别是对于搜索引擎、数据处理等,都需要我们从网上去“取”一些符合要求的数据。总的来说,一般的爬虫分为两个功能模块,也就是取数据和存数据。
取数据是爬虫的关键,特别对于一些具有“防御性”的情况,比如说网站需要登陆的情况,需要挂代理访问的情况,需要限制访问频率的情况,甚至需要输入验证码的情况,都需要在我们设计爬虫方法的时候考虑到。
存数据则是涉及到我们对数据的处理,是保存到数据库中,还是保存到本地文件中,或者临时保存在计算机内存中。
一般所谓的取网页内容,指的是通过程序(某种语言的程序代码,比如Python脚本语言)实现访问某个URL地址,然后获得其所返回的内容(HTML源码,Json格式的字符串等)。然后通过解析规则(比如说正则表达式等),分析出我们需要的数据并取出来。
这里,给大家讲一种最简单的抓取情况,比如说获取一般静态页面的源码(在Chrome浏览器中可以选择右键→查看网页源代码)。如下图,就是网易新闻排行榜页面的源代码,其中这里面有我们想要的数据,比如说一条条的新闻标题和对应的链接。


在Python中实现爬虫非常方便,因为Python中有大量的库,有自带的urllib、urllib2,还可以从网上下载requests库。
利用requests库实现爬虫的代码如下:
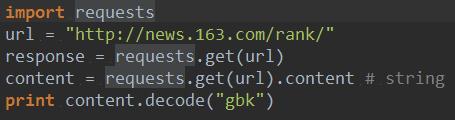
在Python中我们采用了requests库,首先在程序开始要导入该库。所给的url属于get请求方式,简单来说,无需我们向服务器发送一些其他用户相关的数据就可以得到服务器响应的结果。
通过get方式我们得到了response对象。在Pycharm中可以看到response的数据结构,其中我们想要的内容就在content这个字符串中。
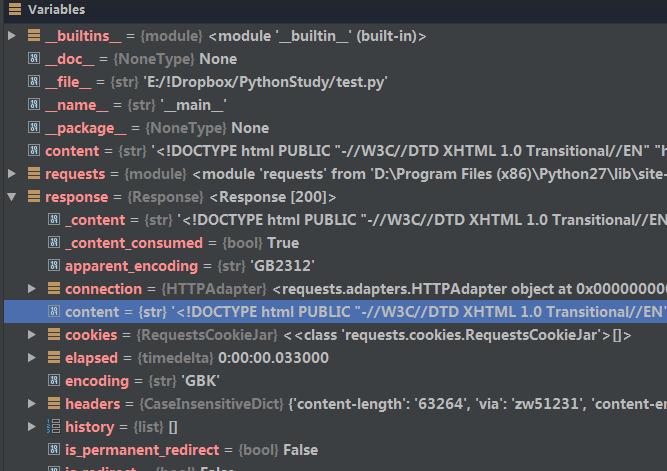
打印该字符串,如果我们直接采用print content,在终端打印出来的可能包含乱码。这是什么原因呢?
因为中文网站中包含中文,而终端不支持gbk编码,所以我们在打印时需要把中文从gbk格式转为终端支持的编码,一般为utf-8编码。一般在对字符串进行处理时,都需要我们对其编码进行转换,转成unicode编码。在终端输出时自动由unicode转换成其支持的编码,比如说utf-8编码。
当然,我们也可以采用print content.decode(“gbk”).encode(“utf-8″),在程序中就把打印的字符串转成utf-8编码了。打印结果就是我们从浏览器看到的网页源代码。
至此,我们实现了获取网页源代码。后面的任务就是如何从这写乱七八糟的源代码中“大海捞针”,筛选出我们需要的数据,本文就先不说了。
类似的,利用Python自带的urllib2实现同样功能如下:
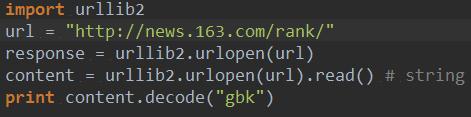
HTTP定义了与服务器交互的不同方法,最基本的方法有4种,分别是GET,POST,PUT,DELETE。URL全称是资源描述符,我们可以这样认为:一个URL地址,它用于描述一个网络上的资源,而HTTP中的GET,POST,PUT,DELETE就对应着对这个资源的查,改,增,删4个操作。其中,GET一般用于获取/查询资源信息,而POST一般用于更新资源信息,通常用于我们需要向服务器提交表单的情况。
如何区分GET请求与POST请求?表面上,我们可以简单地通过浏览器地址栏是否改变来加以区分。
比如说,我们在百度首页输入“宁哥的小站”,回车,然后地址栏会跳转到搜索结果的列表页。同时可以看到浏览器的地址栏会发生改变,类似于”http://www.baidu.com/s?wd=xxx“的形式。就是说,地址栏从百度首页”http://www.baidu.com/“跳转到了”http://www.baidu.com/s?wd=xxx“,变化就在于,在最初的url后面会附加相关的字段,以?分割url和请求的数据,这些数据就是你要查询字段的编码。。而这个过程,就是典型的GET请求的情况。
与之对应的POST请求则显得”深藏不露“。它在于你必须通过浏览器输入或提交一些服务器需要的数据,才能给你返回完整的界面,这点其实与GET请求情况有相通之处,但是这个过程浏览器的地址栏是不会发生跳转的。
那POST请求提交的数据是如何传给服务器的呢?大家可以采用一些分析页面的手段来获取上传的数据。实际上,POST请求是将提交的数据放在HTTP包的包体中,这种方式无疑加强了数据的安全性,不像GET请求那样,用户可以通过跳转的url就可以查看出向服务器发送的数据。另外,POST请求除了提交数据外,还可以提交文件,这点也是GET请求做不到的。
总得来说,在做数据查询时,建议用GET方式;而在做数据添加、修改或删除时,建议用POST方式。接下来我将对GET和POST分别进行一个示例的讲解,让大家对GET和POST有个更直观的理解。
GET请求一般用于我们向服务器查询的过程,比如说,百度搜索“宁哥的小站”,如图所示,浏览器的url会跳转成如图所示
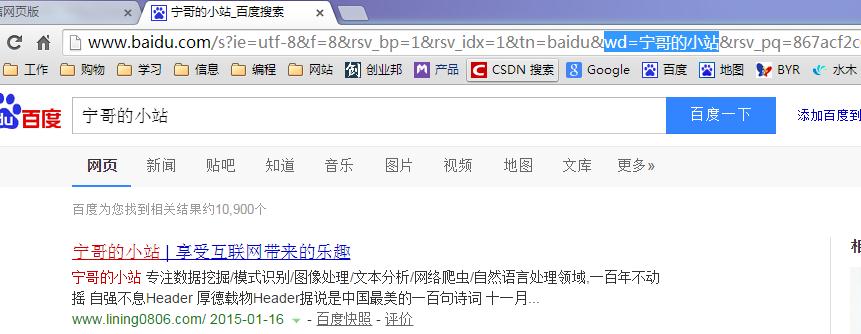
在其中我们可以看到在”http://www.baidu.com/s?”之后出现一个长长的字符串,其中就包含我们要查询的关键词。那么,我们在编程过程中,如何配置这段字符串参数呢?
在Chrome浏览器中,我们可以看到,请求的数据包含在请求头的Query String Parameters中,其实我们可以将这些字段都写在程序中,也可以摘取其中必要的部分,而不是全部。
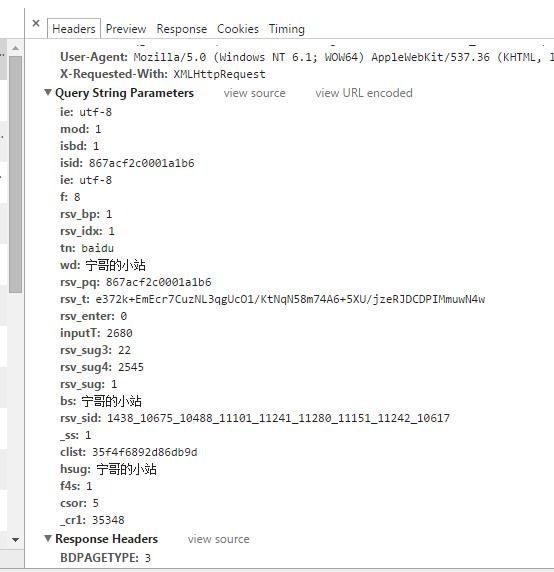
比较关键的是wd字段,这里我们只是把wd字段提取出来,写成词典,然后通过程序编码,配置成GET请求的url,再通过一般的程序抓取手段,可以得到我们查询的页面。程序如下:
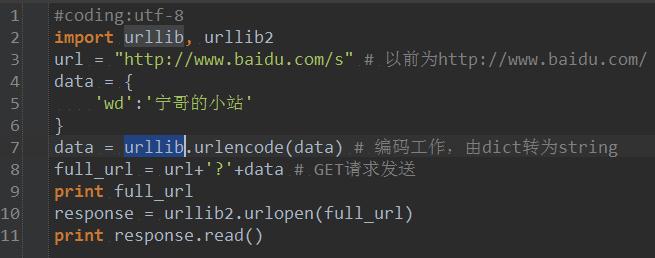
POST请求比较常见的一种情况就是用户名密码登陆情况,这里介绍一种用程序登陆豆瓣账号的流程。
在豆瓣需要我们输入用户名密码,才能获得我们用户里面相关的数据。那么我们通过POST方式传给服务器的数据在哪里呢?与GET方式一样,我们可以在Chrome浏览器中查看请求头,在里面可以看到Form Data,很自然可以看到我们在页面输入的用户名密码。
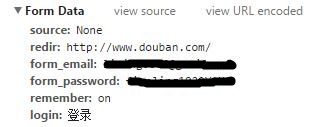
登陆之后,我们就可以获得与用户相关的页面。因为是POST方式,浏览器的url并没有跳转到其他,仍然与登陆之前一样,但是页面内容,却发生了变化。
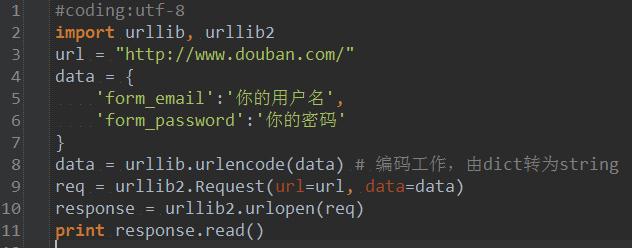
在编写网络爬虫的时候,我们只需要把与用户相关的数据给程序就可以了,对于豆瓣来说,关键就是form_email和form_password两个字段,这样通过下面程序来实现。
我们经常有这样的上网经历,就是如果你采用用户名密码登陆一个网站之后,如果在一段不长的时间内,再次访问这个本来需要你登陆的网站,你会很轻易地访问,而不需要再次输入用户名密码。这种“免登陆”的体验无疑给用户带来了非常好的体验,那为什么会“免登陆”呢?是什么在起作用呢?
答案就是Cookie。当我们在浏览器内输入url,浏览器会向服务器发送一个HTTP请求,相应的,服务器会响应这个请求,向浏览器返回响应的响应信息。所谓Cookie,可以简单认的为是在浏览器端记录包括登陆状态在内的各种属性值的容器名称,其实就是服务器为了保持浏览器与服务器之间连通状态,而在用户本地上创建的数据。只要用户再一次登陆,服务器会主动地寻找这些预存的数据,而无需再要求像第一次一样的操作。
Cookie是HTTP消息头中的一种属性,包括:Cookie名字(Name)Cookie的值(Value),Cookie的过期时间(Expires/Max-Age),Cookie作用路径(Path),Cookie所在域名(Domain),使用Cookie进行安全连接(Secure)。 前两个参数是Cookie应用的必要条件,另外,还包括Cookie大小(Size,不同浏览器对Cookie个数及大小限制是有差异的)。
有了Cookie,我们就可以实现自动登陆网站,甚至能够解决一些验证码登陆的情况。
在Python中,提供了cookielib这个模块,能够将cookie保存到本地,也可以保存在内存中。在第一次用用户名密码登陆网站之后,我们只需要如下创建opener对象,就可以记录cookie:
![]()
这样,接下来我们如果继续访问该域名的网站,直接采用opener.open(需要输入的url),就能实现用保存的Cookie直接打开。
验证码是一种非常有效的反爬虫机制,它能阻止大部分的暴力抓取,在电商类、投票类以及社交类等网站上应用广泛。如果破解验证码,成为了数据抓取工作者必须要面对的问题。
在访问某些网站时,我们最初只是需要提供用户名密码就可以登陆的,比如说豆瓣网,如果我们要是频繁登陆访问,可能这时网站就会出现一个验证码图片,要求我们输入验证码才能登陆,这样在保证用户方便访问的同时,又防止了机器的恶意频繁访问。对于这种情况,我们可以使用代理服务器访问,只需要换个ip地址再次访问,验证码就不会出现了,当然,当验证码再次出现的时候,我们只能再更换ip地址。
如果对于网站首次登陆就需要提供验证码的情况呢?两种办法,我们可以使用cookie登陆,还有就是可以采用验证码识别手段。使用cookie登陆比较简单,但是有时效性问题。而验证码识别虽然是个很好的思路,但是识别的精度又限制了抓取的效率。 拿知乎网举例子,如图所示,知乎的登陆界面要求我们输入用户名密码的同时,给出验证码,才能登陆。
如果采用cookie登陆,可以这样实现:首先需要手动登陆网站一次,获取服务器返回的cookie,这里就带有了用户的登陆信息,当然也可以采用获取的cookie登陆该网站的其他页面,而不用再次登陆。具体代码已经实现,详见ZhihuSpider。我们只需要在配置文件中提供用户名密码,及相应的cookie即可。对于不出现验证码的情况,爬虫会提交用户名密码实现post请求登陆,如果失败,才会使用事先提供的cookie信息。
需要说明的是,判断爬虫登陆与否,我们只需要看一下爬取的信息里面是否带有用户信息即可。在使用cookie登陆的时候,还需要不定期更新cookie,以保证爬取顺利进行。
有很多开源的网络爬虫,如果我们掌握某一种或多种开源的爬虫工具,再我们获取数据的道路上会如虎添翼,事半功倍。这里我介绍一下我对于Scrapy网络爬虫的学习和搭建。
Scrapy使用了Twisted异步网络库来处理网络通讯。整体架构大致如下:
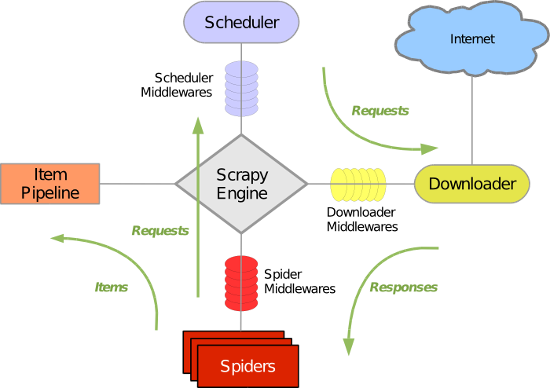
Scrapy要包括了以下组件:
- 引擎,用来处理整个系统的数据流处理,触发事务。
- 调度器,用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。
- 下载器,用于下载网页内容,并将网页内容返回给蜘蛛。
- 蜘蛛,蜘蛛是主要干活的,用它来制订特定域名或网页的解析规则。
- 项目管道,负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清晰、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 调度中间件,介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
- 下载器中间件,位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 蜘蛛中间件,介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。
首先安装Scrapy。在Windows和Linux下各有不同的办法,推荐在Linux下使用。一句话搞定:
pip install scrapy1、首先搭建工程:比如说我要建立一个工程,名字叫Wechatproject
输入命令:scrapy startproject Wechatproject(project名称)
那么生成的工程目录如下:
- Wechatproject
- ├── Wechatproject
- │ ├── __init__.py
- │ ├── items.py
- │ ├── pipelines.py
- │ ├── settings.py
- │ └── spiders
- │ └── __init__.py
- └── scrapy.cfg
scrapy.cfg 是整个项目的设置,主要用于部署scrapy的服务,一般不会涉及。
items.py 定义抓取结果中单个项所需要包含的所有内容。【目标】
settings.py 是scrapy的设置文件,可对其行为进行调整。【设置】
在配置文件中开启pipline插件,添加
- ITEM_PIPELINES = ['Wechatproject.pipelines.WechatprojectPipeline'] # add settings
如果需要下载images,添加
- ITEM_PIPELINES = {'Wechatproject.pipelines.WechatprojectPipeline':1, 'Wechatproject.pipelines.MyImagesPipeline':2} # add settings
- IMAGES_STORE = './images'
pipelines.py 定义如何对抓取到的内容进行再处理,例如输出文件、写入数据库等。【处理】
只有一个需要实现的方法:process_item。如果输出文件、写入数据库等,需要设置settings.py文件。
如果需要下载images,添加:
- '''if you want to download images'''
- # from scrapy.http.request import Request
- # from scrapy.contrib.pipeline.images import ImagesPipeline
- # class MyImagesPipeline(ImagesPipeline):
- # #@TODO
- # def get_media_requests(self, item, info):
- # for image_url in item['image_urls']: # item['image_urls'] contains the image urls
- # # yield Request(image_url)
- # yield Request(image_url, meta={'name': item['name']}) # item['name'] contains the images name
- # def item_completed(self, results, item, info):
- # return super(MyImagesPipeline, self).item_completed(results, item, info)
- # def file_path(self, request, response=None, info=None):
- # f_path = super(MyImagesPipeline, self).file_path(request, response, info)
- # f_path = f_path.replace('full', request.meta['name'])
- # return f_path
- # ##########################################################
- # # import hashlib
- # # image_guid = hashlib.sha1(request.url).hexdigest() # change to request.url after deprecation
- # # return '%s/%s.jpg' % (request.meta['name'], image_guid)
- # pass
- # # from scrapy.contrib.pipeline.media import MediaPipeline
- # # class MyMediaPipeline(MediaPipeline):
- # # #@TODO
- # # pass
spiders 目录下存放写好的spider,也即是实际抓取逻辑。【工具】
parse()方法可以返回两种值:BaseItem,或者Request。通过Request可以实现递归抓取(from scrapy.http import Request)。
如果要抓取的数据在当前页,可以直接解析返回item。
例如:yield item
如果要抓取的数据在当前页指向的页面,则返回Request并指定parse2作为callback。
如果要抓取的数据当前页有一部分,指向的页面有一部分.这种情况需要用Request的meta参数把当前页面解析到的数据传到parse2,后者继续解析item剩下的数据。
2、将来上述文件加入工程,便于文件管理
在Wechatproject工程目录下,新建Spider_Main.py,内容如下:
- from scrapy.cmdline import execute
- import sys
- sys.argv = ["scrapy", "crawl", "wechat"]
- execute()
3、在spider文件夹下定义spider。
spider定义三个主要的、强制的属性:
- name【spider的标识】;
- start_urls【一个需要爬取的链接起始列表】;
- parse()【调用时传入每一个url传回的Response对象作为参数,Response是传入这个方法的唯一参数】。
Scrapy为爬虫的start_urls属性中的每个url创建了一个scrapy.http.Request对象,这些scrapy.http.Request首先被调度,然后被执行,之后通过爬虫的parse()方法作为回调函数,scapy.http.Response对象被返回,结果也被反馈给爬虫。
parse()方法是用来处理Response对象,返回爬取的数据,并且获得更多等待爬取的链接。
可以使用其他分析方法如正则表达式或者BeautifulSoup对response.body进行分析,不局限于xpath()方法。
- from scrapy.selector import Selector
- sel = Selector(response) # sel是一个selector
sel.xpath()返回selectors列表,每一个selector表示一个xpath参数表达式选择的节点这样就可以更快的获取需要的数据。
使用sel.xpath().extract()取出节点下面的文本数据或者使用sel.xpath().re(r”(\w+)”)来正则匹配其中元素。
同理,
- from scrapy.selector import HtmlXPathSelector
- hxs = HtmlXPathSelector(response)
使用hxs.select()返回htmlxpathselectors列表,和hxs.select().extract()取出数据或者hxs.select().re(r”(\w+)”)来正则匹配。
4、网络抓取:scrapy crawl wechat(spider名称) 或 scrapy crawl wechat -o results\items.json -t json
Python学习网络爬虫主要分3个大的版块:抓取,分析,存储
另外,比较常用的爬虫框架Scrapy,这里最后也详细介绍一下。
首先列举一下本人总结的相关文章,这些覆盖了入门网络爬虫需要的基本概念和技巧:宁哥的小站-网络爬虫
当我们在浏览器中输入一个url后回车,后台会发生什么?比如说你输入http://www.lining0806.com/,你就会看到宁哥的小站首页。
简单来说这段过程发生了以下四个步骤:
- 查找域名对应的IP地址。
- 向IP对应的服务器发送请求。
- 服务器响应请求,发回网页内容。
- 浏览器解析网页内容。
网络爬虫要做的,简单来说,就是实现浏览器的功能。通过指定url,直接返回给用户所需要的数据,而不需要一步步人工去操纵浏览器获取。
抓取
这一步,你要明确要得到的内容是什么?是HTML源码,还是Json格式的字符串等。
1. 最基本的抓取
抓取大多数情况属于get请求,即直接从对方服务器上获取数据。
首先,Python中自带urllib及urllib2这两个模块,基本上能满足一般的页面抓取。另外,requests也是非常有用的包,与此类似的,还有httplib2等等。
Requests:
import requests
response = requests.get(url)
content = requests.get(url).content
print "response headers:", response.headers
print "content:", content
Urllib2:
import urllib2
response = urllib2.urlopen(url)
content = urllib2.urlopen(url).read()
print "response headers:", response.headers
print "content:", content
Httplib2:
import httplib2
http = httplib2.Http()
response_headers, content = http.request(url, 'GET')
print "response headers:", response_headers
print "content:", content
此外,对于带有查询字段的url,get请求一般会将来请求的数据附在url之后,以?分割url和传输数据,多个参数用&连接。
data = {'data1':'XXXXX', 'data2':'XXXXX'}
Requests:data为dict,json
import requests
response = requests.get(url=url, params=data)
Urllib2:data为string
import urllib, urllib2
data = urllib.urlencode(data)
full_url = url+'?'+data
response = urllib2.urlopen(full_url)
相关参考:网易新闻排行榜抓取回顾
2. 对于登陆情况的处理
2.1 使用表单登陆
这种情况属于post请求,即先向服务器发送表单数据,服务器再将返回的cookie存入本地。
data = {'data1':'XXXXX', 'data2':'XXXXX'}
Requests:data为dict,json
import requests
response = requests.post(url=url, data=data)
Urllib2:data为string
import urllib, urllib2
data = urllib.urlencode(data)
req = urllib2.Request(url=url, data=data)
response = urllib2.urlopen(req)
2.2 使用cookie登陆
使用cookie登陆,服务器会认为你是一个已登陆的用户,所以就会返回给你一个已登陆的内容。因此,需要验证码的情况可以使用带验证码登陆的cookie解决。
import requests
requests_session = requests.session()
response = requests_session.post(url=url_login, data=data)
若存在验证码,此时采用response = requests_session.post(url=url_login, data=data)是不行的,做法应该如下:
response_captcha = requests_session.get(url=url_login, cookies=cookies)
response1 = requests.get(url_login) # 未登陆
response2 = requests_session.get(url_login) # 已登陆,因为之前拿到了Response Cookie!
response3 = requests_session.get(url_results) # 已登陆,因为之前拿到了Response Cookie!
相关参考:网络爬虫-验证码登陆
3. 对于反爬虫机制的处理
3.1 使用代理
适用情况:限制IP地址情况,也可解决由于“频繁点击”而需要输入验证码登陆的情况。
这种情况最好的办法就是维护一个代理IP池,网上有很多免费的代理IP,良莠不齐,可以通过筛选找到能用的。对于“频繁点击”的情况,我们还可以通过限制爬虫访问网站的频率来避免被网站禁掉。
proxies = {'http':'http://XX.XX.XX.XX:XXXX'}
Requests:
import requests
response = requests.get(url=url, proxies=proxies)
Urllib2:
import urllib2
proxy_support = urllib2.ProxyHandler(proxies)
opener = urllib2.build_opener(proxy_support, urllib2.HTTPHandler)
urllib2.install_opener(opener) # 安装opener,此后调用urlopen()时都会使用安装过的opener对象
response = urllib2.urlopen(url)
3.2 时间设置
适用情况:限制频率情况。
Requests,Urllib2都可以使用time库的sleep()函数:
import time
time.sleep(1)
3.3 伪装成浏览器,或者反“反盗链”
有些网站会检查你是不是真的浏览器访问,还是机器自动访问的。这种情况,加上User-Agent,表明你是浏览器访问即可。有时还会检查是否带Referer信息还会检查你的Referer是否合法,一般再加上Referer。
headers = {'User-Agent':'XXXXX'} # 伪装成浏览器访问,适用于拒绝爬虫的网站
headers = {'Referer':'XXXXX'}
headers = {'User-Agent':'XXXXX', 'Referer':'XXXXX'}
Requests:
response = requests.get(url=url, headers=headers)
Urllib2:
import urllib, urllib2
req = urllib2.Request(url=url, headers=headers)
response = urllib2.urlopen(req)
4. 对于断线重连
不多说。
def multi_session(session, *arg):
retryTimes = 20
while retryTimes>0:
try:
return session.post(*arg)
except:
print '.',
retryTimes -= 1
或者
def multi_open(opener, *arg):
retryTimes = 20
while retryTimes>0:
try:
return opener.open(*arg)
except:
print '.',
retryTimes -= 1
这样我们就可以使用multi_session或multi_open对爬虫抓取的session或opener进行保持。
5. 多进程抓取
这里针对华尔街见闻进行并行抓取的实验对比:Python多进程抓取 与 Java单线程和多线程抓取
相关参考:关于Python和Java的多进程多线程计算方法对比
6. 对于Ajax请求的处理
对于“加载更多”情况,使用Ajax来传输很多数据。
它的工作原理是:从网页的url加载网页的源代码之后,会在浏览器里执行JavaScript程序。这些程序会加载更多的内容,“填充”到网页里。这就是为什么如果你直接去爬网页本身的url,你会找不到页面的实际内容。
这里,若使用Google Chrome分析”请求“对应的链接(方法:右键→审查元素→Network→清空,点击”加载更多“,出现对应的GET链接寻找Type为text/html的,点击,查看get参数或者复制Request URL),循环过程。
- 如果“请求”之前有页面,依据上一步的网址进行分析推导第1页。以此类推,抓取抓Ajax地址的数据。
- 对返回的json格式数据(str)进行正则匹配。json格式数据中,需从’\uxxxx’形式的unicode_escape编码转换成u’\uxxxx’的unicode编码。
7. 自动化测试工具Selenium
Selenium是一款自动化测试工具。它能实现操纵浏览器,包括字符填充、鼠标点击、获取元素、页面切换等一系列操作。总之,凡是浏览器能做的事,Selenium都能够做到。
这里列出在给定城市列表后,使用selenium来动态抓取去哪儿网的票价信息的代码。
参考项目:网络爬虫之Selenium使用代理登陆:爬取去哪儿网站
8. 验证码识别
对于网站有验证码的情况,我们有三种办法:
- 使用代理,更新IP。
- 使用cookie登陆。
- 验证码识别。
使用代理和使用cookie登陆之前已经讲过,下面讲一下验证码识别。
可以利用开源的Tesseract-OCR系统进行验证码图片的下载及识别,将识别的字符传到爬虫系统进行模拟登陆。当然也可以将验证码图片上传到打码平台上进行识别。如果不成功,可以再次更新验证码识别,直到成功为止。
参考项目:验证码识别项目第一版:Captcha1
爬取有两个需要注意的问题:
- 如何监控一系列网站的更新情况,也就是说,如何进行增量式爬取?
- 对于海量数据,如何实现分布式爬取?
分析
抓取之后就是对抓取的内容进行分析,你需要什么内容,就从中提炼出相关的内容来。
常见的分析工具有正则表达式,BeautifulSoup,lxml等等。
存储
分析出我们需要的内容之后,接下来就是存储了。
我们可以选择存入文本文件,也可以选择存入MySQL或MongoDB数据库等。
存储有两个需要注意的问题:
- 如何进行网页去重?
- 内容以什么形式存储?
Scrapy
Scrapy是一个基于Twisted的开源的Python爬虫框架,在工业中应用非常广泛。
相关内容可以参考基于Scrapy网络爬虫的搭建,同时给出这篇文章介绍的微信搜索爬取的项目代码,给大家作为学习参考。
参考项目:使用Scrapy或Requests递归抓取微信搜索结果
Robots协议
好的网络爬虫,首先需要遵守Robots协议。Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
在网站根目录下放一个robots.txt文本文件(如 https://www.taobao.com/robots.txt ),里面可以指定不同的网络爬虫能访问的页面和禁止访问的页面,指定的页面由正则表达式表示。网络爬虫在采集这个网站之前,首先获取到这个robots.txt文本文件,然后解析到其中的规则,然后根据规则来采集网站的数据。
1. Robots协议规则
User-agent: 指定对哪些爬虫生效
Disallow: 指定不允许访问的网址
Allow: 指定允许访问的网址
注意: 一个英文要大写,冒号是英文状态下,冒号后面有一个空格,”/”代表整个网站
2. Robots协议举例
禁止所有机器人访问
User-agent: *
Disallow: /
允许所有机器人访问
User-agent: *
Disallow:
禁止特定机器人访问
User-agent: BadBot
Disallow: /
允许特定机器人访问
User-agent: GoodBot
Disallow:
禁止访问特定目录
User-agent: *
Disallow: /images/
仅允许访问特定目录
User-agent: *
Allow: /images/
Disallow: /
禁止访问特定文件
User-agent: *
Disallow: /*.html$
仅允许访问特定文件
User-agent: *
Allow: /*.html$
Disallow: /对网易新闻排行榜的抓取,是我以前学爬虫做的一个小实验。像下图,我的目的就是想把网易新闻排行榜这个页面下的所有新闻的标题和对应的链接都下载下来,分专题保存。

抓取页面很容易,但是有一点,在页面分析的时候,我发现并不是所有专题的页面结构是一样的。用正则表达式分析的话,速度确实慢了点,这时候就要讲究不同解析规则的相互配合。而正则表达式,对于获取多种组合数据有一定的可取之处。
话不多说,上个简单的代码,同时我把python代码打包成exe可执行文件。代码和exe文件可以在NewsSpider下载。对于没有python环境的情况下,直接双击exe文件就可以开始抓取。这样子,我们就可以在上班的时候大模大样的看文档的姿态来筛选感兴趣的新闻,而不被领导发现喽。。
# -*- coding: utf-8 -*-
import os
import sys
import urllib2
import requests
import re
from lxml import etree
def StringListSave(save_path, filename, slist):
if not os.path.exists(save_path):
os.makedirs(save_path)
path = save_path+"/"+filename+".txt"
with open(path, "w+") as fp:
for s in slist:
fp.write("%s\t\t%s\n" % (s[0].encode("utf8"), s[1].encode("utf8")))
def Page_Info(myPage):
'''Regex'''
mypage_Info = re.findall(r'<div class="titleBar" id=".*?"><h2>(.*?)</h2><div class="more"><a href="(.*?)">.*?</a></div></div>', myPage, re.S)
return mypage_Info
def New_Page_Info(new_page):
'''Regex(slowly) or Xpath(fast)'''
# new_page_Info = re.findall(r'<td class=".*?">.*?<a href="(.*?)\.html".*?>(.*?)</a></td>', new_page, re.S)
# # new_page_Info = re.findall(r'<td class=".*?">.*?<a href="(.*?)">(.*?)</a></td>', new_page, re.S) # bugs
# results = []
# for url, item in new_page_Info:
# results.append((item, url+".html"))
# return results
dom = etree.HTML(new_page)
new_items = dom.xpath('//tr/td/a/text()')
new_urls = dom.xpath('//tr/td/a/@href')
assert(len(new_items) == len(new_urls))
return zip(new_items, new_urls)
def Spider(url):
i = 0
print "downloading ", url
myPage = requests.get(url).content.decode("gbk")
# myPage = urllib2.urlopen(url).read().decode("gbk")
myPageResults = Page_Info(myPage)
save_path = u"网易新闻抓取"
filename = str(i)+"_"+u"新闻排行榜"
StringListSave(save_path, filename, myPageResults)
i += 1
for item, url in myPageResults:
print "downloading ", url
new_page = requests.get(url).content.decode("gbk")
# new_page = urllib2.urlopen(url).read().decode("gbk")
newPageResults = New_Page_Info(new_page)
filename = str(i)+"_"+item
StringListSave(save_path, filename, newPageResults)
i += 1
if __name__ == '__main__':
print "start"
start_url = "http://news.163.com/rank/"
Spider(start_url)
print "end"
转载请注明:宁哥的小站 » 网易新闻排行榜抓取回顾