python爬虫的一些理解
(整理的有点乱,请多多关照)
1 . 爬虫简介
爬虫: 一段自动抓取互联网信息的程序

2. 爬虫价值
信息数据
3. 爬虫架构

4. 运行流程
(解:运行从上到下流程)
调度器 **** URL管理器 **** 下载器 **** 解析器 ***** 应用
-----有待爬URL—→
←-----是/否--------
-----获取1个带爬URL→
←----- URL --------
----------------下载URL内容-------- →
----------------URL的内容----------- →
------------------------解析URL内容------------- -→
--------------------价值数据,新URL列表----------- →
------------------------------收集价值数据------------------------→
-----新增到待爬URL—→
URL管理器
URL管理器:管理待抓取URL集合和已抓取URL集合
防止重复抓取、防止循环抓取
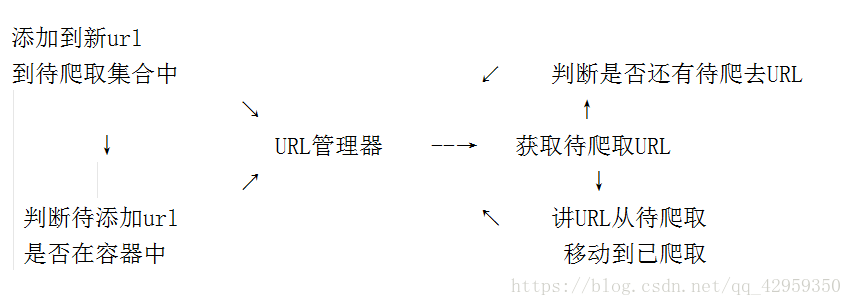
URL管理器 : 实现方式

网页下载器

网页下载器 - urllib2
- urllib2下载网页的方法1:

直接请求
response = urllib2.urlopen(‘http://www.baidu.com’)
获取状态码,如果是200表示获取成功
print response.getcode()
读取内容
cont = response.read()
第二种方法
-
urllib2下载网页方法2: 添加data、http header
url data header ↘ ↓ ↙ urllib2.Request ↓ urllib2.urlopen(request)
操作代码
import urllib2
#创建Request对象
request = urllib2.Request(url)
#添加数据
request.add_header(‘User-Agent’, ‘Mozilla/S.0’)
发送请求获取结果
response = urllib2.urlopen(request)
第三种办法(登陆才能访问)
urllib2下载网页方法3: 添加特殊场景的处理器
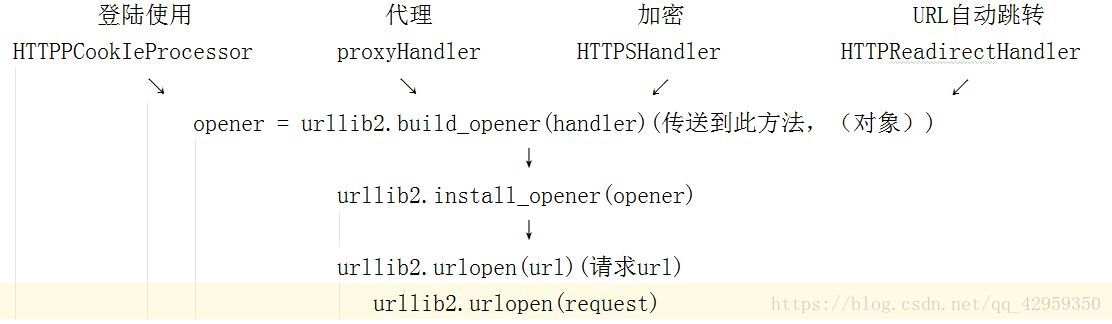
操作代码
import urllib2, cookielib
创建cookie容器
cj = cookielib.CookieJar()
创建1个opener
opener = urllib2.build_opener(urllib2.HTTPCookiePRocessor(cj))
给urllib2安装opener
urllib2.install_opener(opener)
使用带有cookie的urllib2访问网页
response = urllib2.urlopen(“http://www.baidu.com/”)