摘要: 背景与目标 光学字符识别 ( Optical Character Recognition, OCR ) 是将图像中的手写或打印文本转换为机器编码文本,以获取图像中文字及版面信息的过程。其目的是将图片中的文字识别出来,以便进一步对文字进行处理。
背景与目标
光学字符识别 ( Optical Character Recognition, OCR ) 是将图像中的手写或打印文本转换为机器编码文本,以获取图像中文字及版面信息的过程。其目的是将图片中的文字识别出来,以便进一步对文字进行处理。
最早的 OCR技术可追溯到 1914 年,Emanuel Goldberg 开发了一种手持式的扫描仪,当这种扫描仪扫过打印的文档时,会产生相对应的特定字符;20 世纪 30 年代,传统的模板匹配算法被应用于英文字母和数字的识别;至今,OCR 技术已得到了长足的发展,新的 OCR 算法层出不穷,并逐渐由传统算法向深度学习算法过渡。随着智能手机的出现,OCR 技术被广泛应用于各种场合,例如:识别护照文件、发票、银行卡、身份证、名片和营业执照等,目前,OCR 技术是模式识别、人工智能和计算机视觉等研究的热门领域。
身份证信息提取是 OCR领域的一个重要应用,随着数字化金融的发展,在线支付,网上理财等业务蓬勃发展,OCR 技术可以准确快速的从用户拍摄的身份证图片中提取性别、籍贯、出生年月、身份证号等信息,以方便用户进行身份鉴权和认证,有效解决了身份证信息录入问题,能够快速、高效的处理数据,大大提高了效率。
身份证 OCR识别流程
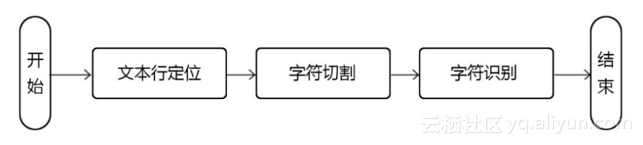
在本系统设计中,身份证 OCR识别主要经过三个过程,文本行定位,字符切割及字符识别 ( 见下图 )。由于身份证图片的背景较为单一,且身份证文字为黑色字符,与背景相差较大,所以在进行文本行定位及字符切割时采用传统方法便可获得比较良好的结果。
由于目前大多数字符识别算法是针对单独字符进行识别,根据粗略统计,身份证中常用的中文字符种类数量约 6500 个,使用传统方法在如此庞大种类数量的图片进行识别且获得较高的准确率十分困难。近年来,深度学习技术在图像识别领域被广泛利用并获得了突破性的进展。
在 2012 年的 ImageNet 大赛中,Alex 使用的卷积神经网络 ( CNN ) 获得了 84%的识别准确率,远远高于此前两年 74%的准确率,从那时开始,凭借其在图像识别领域优异的表现,CNN 已然发展成为了图像识别技术中最为行之有效的方法之一 。
在实现身份证 OCR中,图像处理部分采用了计算机视觉库 OpenCV 进行相应的图像处理,进行字符识别的 CNN 网络则使用以 Tensorflow 为后端的 Keras进行搭建及训练。
文本行定位
对于身份证这种存在纹理背景、光照不均匀以及模糊倾斜等强烈干扰的复杂图像,如何快速定位文本行及准确切割字符是至关重要的。在此系统中,对于文本行的定位可以分为 3 个步骤:首先根据水平投影定位出身份证号码行,其次根据垂直投影除去身份证照片区域,最后再根据水平投影定位出身份证文本信息行。

通过观察身份证图像可以发现,身份证号码与上面的个人信息和照片之间有明显较大的间隔,所以利用这个间隔,可以方便的将身份证号码先分割开来。首先为了减小背景对定位的干扰,对收集到的彩色图像进行灰度化、标准化,随后采用投影算法对图像进行投影,其原理利用图像的像素分布直方图进行分析,投影峰中从下向上首个明显的高峰段区域即为身份证号码区域。具体代码如下:
#导入需要的库。
import cv2
import numpy as np
#从文件路径中读入图片。
file_path = '/path to your image'
img = cv2.imread(file_path, 1)
#对图片做灰度化转换。
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#再进行图片标准化,将图片数组的数值统一到一定范围内。函数的参数
#依次是:输入数组,输出数组,最小值,最大值,标准化模式。
cv2.normalize(img, img, 0, 255, cv2.NORM_MINMAX)
#使用投影算法对图像投影。
horizontal_map = np.mean(img, axis=1)
用户使用手机进行拍摄时,得到的图像可能存在一定的旋转角度及光照不均匀等问题,为了降低此类问题对定位和识别的影响,需要依次使用 CLAHE 算法 进行光照校正、Canny 算法 进行边缘检测,以及 Radon 变换 获得旋转角度,随后按照上一步得到的旋转角度进行旋转校正。关于 Radon 变换的实现代码如下:
#导入需要的库。
import imutils
import numpy as np
#定义 Radon 变换函数,检测范围-90 至 90,间隔为 0.5:
def radon_angle(img, angle_split=0.5):
angles_list = list(np.arange(-90., 90. + angle_split,
angle_split))
#创建一个列表 angles_map_max,存放各个方向上投影的积分最大
#值。我们对每个旋转角度进行计算,获得每个角度下图像的投影,
#然后计算当前指定角度投影值积分的最大值。最大积分值对应的角度
#即为偏转角度。
angles_map_max = []
for current_angle in angles_list:
rotated_img = imutils.rotate_bound(img, current_angle)
current_map = np.sum(rotated_img, axis=1)
angles_map_max.append(np.max(current_map))
adjust_angle = angles_list[np.argmax(angles_map_max)]
return adjust_angle
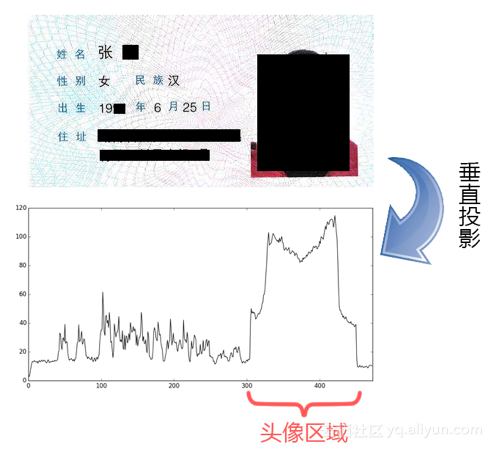
旋转校正过后,同理,将分割身份证号码后剩下的身份证图像进行列投影。此处通过计算垂直方向的像素均值来获得图像相应方向的投影值,投影峰中从右向左首个高峰段区域即为身份证照片所在列的位置,下图为投影切割的示意图:
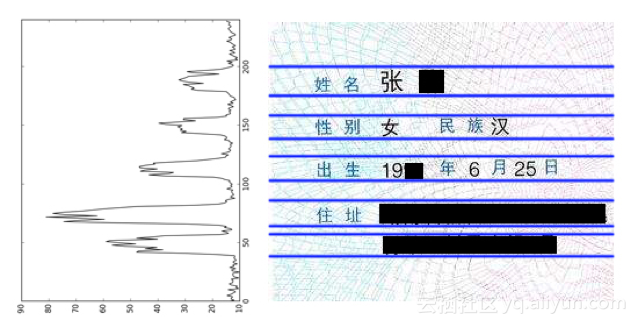
去除身份证照片之后,剩余部分即为所需的身份文本信息,由于身份证的规格是统一的,我们可以去掉文本周围的空白部分,进一步缩减文本图像部分的面积。通过对身份证上的字符排列情况观察可知,在有文字信息的行上有较多的黑色像素,而字符的行与行之间有明显的间隙,在对图像进行水平投影时,有文字信息的行会形成明显的峰,行之间的间隙会形成明显的峰谷。这样即可确定出各行文字所在水平区域的大致位置。
字符切割
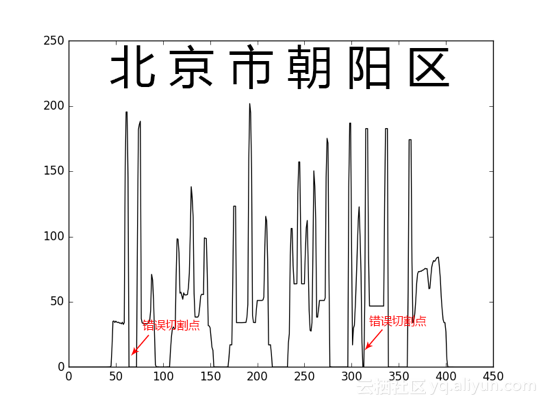
获得文本行后,需要进行单个字符的切割,将每个字符切割出来后以便于后续字符识别。字符分割最简便的方法是利用连续等间距的框作为模板来分割,但是对于实际的身份证图像来说,身份证住址信息常常含有数字和中文字符,字符个数也不能确定,所以,采用等间距的模板来分割单个字符不能得到理想的效果,由于所以本系统中对于单个字符的切割采用了垂直投影切割算法,并利用局部最值法得到最佳切割位置。但是中文字符中经常会出现左右结构或左中右结构的字符,如:“北”,“川”和“小”等。在进行投影切割时,这些字符经常会被误切割成两个或三个字符。
为解决这一问题,我们对单个字符的宽度统计分析,以字符宽度为判断标准,将切割后的字符通过字符识别模型进行合并,从而解决被从中间切断字符的问题。
字符识别
字符图片预处理
获得单个字符后,为获得最佳的识别效果,在使用 CNN 卷积神经网络进行训练和识别前,我们需要对图像进行一定的预处理步骤,包括图像增强、截断阈值化、图像边缘切除以及图像分辨率的统一。
- 图像增强
图像增强主要是为了突出图像中需要的信息,并且减弱或者去除不需要的信息,削弱干扰和噪声,从而使有用的信息得到加强,便于区分或解释。图像增强的方法有很多种,本文主要采用直方图均衡化技术。
直方图均衡化技术是通过对原图像进行某种变换,重新分配图像像素值,把原始图像的灰度直方图从比较集中的某个灰度区间转化为在全部灰度范围内均匀分布的形式,从而使原始图像的直方图改变成均匀分布的直方图,达到增强图像整体对比度的效果。
- 截断阈值化
该阈值化类型如下式所示:
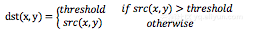
首先选定一个阈值,根据该阈值对图像作如下处理:图像中大于该阈值的像素点被设定为该阈值,小于该阈值的保持不变。
- 图像边缘切除
这一步的目的是去除单个字符上下左右多余的空白区域。具体的做法是,通过找到图像每一行和每一列上存在黑色像素的上下左右边缘位置,从而对图像边缘进行切除。 - 图像分辨率统一
最后,我们需要把所有的单个字符图片的分辨率统一缩放成 32*32 的大小,便于输入到神经网络中。
#首先,进行直方图均衡化操作。
enhance_img = cv2.equalizeHist(img)
#再对图片做截断阈值化,函数的参数依次是:输入数组,设定的阈值,像素最大值,阈值类型。
ret, binary_img = cv2.threshold(enhance_img, 127, 255,
cv2.THRESH_TRUNC)
#图像边缘切除处理。
width_val = np.min(binary_img, axis=0)
height_val = np.min(binary_img, axis=1)
left_point = np.min(indices(width_val, lambda
x:x<cutThreahold))
right_point = np.max(indices(width_val, lambda
x:x<cutThreahold))
up_point = np.max(indices(height_val, lambda
x:x<cutThreahold))
down_point = np.min(indices(height_val, lambda
x:x<cutThreahold))
prepare_img = binary_img[down_point:up_point+1,
left_point:right_point+1]
#将图像的分辨率统一。
img_rows, img_cols = prepare_img.shape[:2]
standard_img = np.ones((32, 32), dtype='uint8') * 127
resize_scale = np.max(prepare_img.shape[:2])
resized_img = cv2.resize(prepare_img, (int(img_cols * 32 /
resize_scale), int(img_rows * 32 /
resize_scale)))
img_rows, img_cols = resized_img.shape[:2]
offset_rows = (32 - img_rows) // 2
offset_cols = (32 - img_cols) // 2
for x in range(img_rows):
for y in range(img_cols):
newimg[x +offset_height, y +offset_width] =
img_resize[x, y]模型训练
在将单个字符经过上述预处理后,我们就得到了由很多个单个字符组成的样本集。该项目共采用身份证图片约 5 万张,用于实际训练的单个字符样本数约 75 万张,共涵盖数字、汉字及英文字母 6935 种,可覆盖身份证常用字符的 99.9%以上。经过上述的预处理后,我们得到的每张单个字符样本为 32*32 像素大小,通道数为 1 的灰度图片。因此,每张图可以看作有 32*32*1 = 1,024 个特征,作为卷积神经网络的输入。神经网络的输出为当前输入的样本属于各个字符的概率,如果神经网络认为该输入越像某个字符,则输出的概率值越接近于 1,通过对比和排序选出最高概率的字符,从而实现识别的目的。
我们通过 Keras来搭建卷积神经网络,训练字符识别模型。我们将搭建一个具有五层结构的卷积神经网络,它由三个卷积层、一个全连接层和一个输出层组成。其中,第一个卷积层即起到了输入层的作用,参数 input_shape 即表示输入神经网络的数据形状,在这里就是我们预处理后的图片数组的形状 (32, 32, 1)。
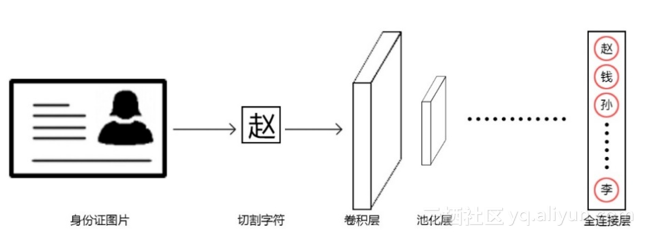
取决于计算机的硬件,我们的神经网络训练过程可能要花几分钟至数小时的时间。得到了模型后,我们需要测试并观察模型在验证集上的准确率。在本次项目中,我们的字符识别模型对单个字符的识别准确率达到了 99.5%,对于身份证姓名识别的准确率为 99.0%,对于地址的识别准确率为 75.5%,对于签发机构的识别准确率为 82.5%,均达到了较理想的水平。图为 CNN 结构示意图:
#导入 Keras相关库。
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.convolutional import Convolution2D,
MaxPooling2D
#模型初始化。
model = Sequential()
#创建第一个卷积层。
model.add(Convolution2D(16, 3, 3, border_mode='valid',
input_shape=(32, 32, 1)))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#创建第二个卷积层。
model.add(Convolution2D(32, 3, 3, border_mode='valid'))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#创建第三个卷积层。
model.add(Convolution2D(32, 3, 3, border_mode='valid'))
model.add(Activation('tanh'))
#创建全连接层。
model.add(Flatten())
model.add(Dense(128, init= 'he_normal'))
model.add(Activation('tanh'))
#创建输出层,使用 Softmax函数输出属于各个字符的概率值。
model.add(Dense(output_dim=nb_classes, init= 'he_normal'))
model.add(Activation('softmax'))
#设置神经网络中的损失函数和优化算法。
model.compile(loss='poisson', optimizer='adam',
metrics=['accuracy'])
#开始训练,并设置批尺寸和训练的步数。
model.fit(data,label_matrix,batch_size=2500,nb_epoch=50,
shuffle=True, verbose=1)小结
本章的任务是识别身份证照片中的文字信息。在实际应用场景中,采集到的身份证照片质量往往参差不齐,存在各类比如拍摄角度偏斜、光照条件不佳等问题,对后续的神经网络训练与识别任务产生极大的干扰。幸运的是,通过一些图像领域的专业处理方法,我们可以在一定程度上减弱图像质量带来的影响,这些方法可以都有助于我们得到较为规整的单个数字与汉字图片,从而形成我们的训练样本。
有了训练样本后,我们创建一个深层的卷积神经网络 CNN,来训练字符识别模型。卷积神经网络由多层网络结构组成,特别适合图像识别等任务,但缺点是需要极大量的训练数据集。对于每一条的输入,神经网络模型会输出它属于所有字符类别各自的概率,我们认为概率值最大的字符类别即为实际的预测结果。最终,我们的模型取得了单个字符 99.5%的识别准确率。
另外,在训练字符识别模型的过程中一个无法避免的问题是训练样本不平衡,比如一些生僻的汉字就很难甚至根本无法获得足量的真实训练样本,对这类字符的识别准确率会受到很大影响。我们的解决方法是通过一些图像处理手段用程序生成更多的样本,例如在已有的少量真实样本上加入噪点、改变光照、变换角度等,将真实样本和人造样本混在一起训练,也取得了良好的效果。
本文摘自笔者和同事所著《Python 机器学习实战》,本文作者为寇莉
版权声明:本文内容由互联网用户自发贡献,版权归作者所有,本社区不拥有所有权,也不承担相关法律责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:[email protected] 进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
【云栖快讯】云栖专辑 | 阿里开发者们的第17个感悟:无细节不设计,无设计不架构 详情请点击
评论 (3)点赞 (1)收藏 (0)
分享到:
相关文章
- python+flask搭建CNN在线识别手写中文网站
- 做跨界的跳跃,不惧怕学习,不惧怕失败 —— 阿里云 MV…
- 【独家】一文读懂文字识别(OCR)
- 用风格迁移搞事情!超越艺术字:卷积神经网络打造最美汉字
- 团队拙作《Python机器学习实战》
- 深度学习入门笔记系列 ( 八 ) ——基于 tensor…
- 深度学习应用:入门篇(下)
- Android+TensorFlow+CNN+MNIST…
- 西邮Linux小组免试题——继续挑战
- python基础1
网友评论
![]()
xinxini2018-06-13 09:21:22
..
![]()
xinxini2018-06-14 08:53:25
我有个问题请教可以么
![]()
1906433605091933 2018-08-07 09:27:11
请问下 文字分割部分的代码能补全吗 投影法截取出每行的数据