基于CNN的图像识别
基于CNN的图像识别
以CNN为基础完成一个CIFAR-10图像识别应用
CNN相关基础理论
卷积神经网络概述
CNN(Convolutional Neural Network,卷积神经网络)是DNN(深度神经网络)中一个非常重要的并且应用广泛的分支,CNN自从被提出,在图像处理领域得到了大量应用。
-
卷积神经网络结构
卷积神经网络按照层级可以分为5层:数据输入层、卷积层、激活层、池化层和全连接层。
-
数据输入层
数据输入层主要是对原始图像数据进行预处理
- 去均值:把输入数据各个维度都中心化为0,其目的是把样本数据的中心拉回到坐标系原点上。
- 归一化:对数据进行处理后将其限定在一定的范围内,这样可以减少各维度数据因取值范围差异而带来的干扰。
- PCA:通过提取主成分的方式避免数据特征稀疏化。
-
-
卷积层
卷积层通过卷积计算将样本数据进行降维采样,以获取具有空间关系特征的数据。
-
激活层
激活层对数据进行非线性变换处理,目的是对数据维度进行扭曲来获得更多连续的概率密度空间。
在CNN中,激活层一般采用的激活函数是ReLU,它具有收敛快、求梯度简单等特点。
-
池化层
池化层夹在连续的卷积层中间,用于压缩数据的维度以减少过拟合。
池化层使得CNN具有局部平移不变性,当需要处理那些只关注某个特征是否出现而不关注其出现的具体位置的任务时,局部平移不变性相当于为神经网络模型增加了一个无限强大的先验输入,这样可以极大地提高网络统计效率。
当采用最大池化策略时,可以采用最大值来代替一个区域的像素特征,这样就相当于忽略了这个区域的其他像素值,大幅度降低了数据采样维度。
-
全连接层
和常规的DNN一样,全连接层在所有的神经网络层级之间都有权重连接,最终连接到输出层。
在进行模型训练时,神经网络会自动调整层级之间的权重以达到拟合数据的目的。
卷积神经网络三大核心概念
-
稀疏交互
稀疏交互是指在深度神经网络中,处于深层次的单元可能与绝大部分输入是间接交互的。
例如: 金字塔模型,塔顶尖的点与塔底层的点就是一个间接交互的关系。如果特征信息是按照金字塔模型的走向从底层向上逐步传播的,那么可以发现,对于处在金字塔顶尖的点,它的视野可以包含所有底层输入的信息。
因为CNN具有稀疏交互性,可以通过非常小的卷积核来提取巨大维度图像数据中有意义的特征信息,因此稀疏交互性使CNN中的输出神经元之间的连接数呈指数级下降,这样神经网络计算的时间复杂度也会呈指数级下降,进而可以提高神经网络模型的训练速度。
-
参数共享
参数共享是指在一个模型的多个函数中使用相同的参数,在卷积计算中参数共享可以使神经网络模型只需要学习一个参数集合,而不需要针对每一个位置学习单独的参数集合。
参数共享可以显著降低需要存储的参数数量,进而提高神经网络的统计效率。
-
等变表示
等变表示是指当一个函数输入改变时,其输出也以同样的方式改变
这个特性的存在说明:卷积函数具备等变性,经过卷积计算之后可以等变地获取数据的特征信息。
TensorFlow 2.0 API
tf.keras.Sequential
Sequential是一个方法类,可以帮助我们轻而易举地以堆叠神经网络层的方式集成构建一个复杂的神经网络模型。
Sequential提供了丰富的方法,利用这些方法可以快速地实现神经网络模型的网络层级集成、神经网络模型编译、神经网络模型训练和保存,以及神经网络模型加载和预测。
-
神经网络模型的网络层级集成
使用Sequential().add()方法来实现神经网络层级的集成,可以根据实际需要将tf.keras.layers中的各类神经网络层级添加进去
import tensorflow as tf model = tf.keras.Sequential() #使用add方法集成神经网络层级 model.add(tf.keras.layers.Dense(256, activation="relu")) model.add(tf.keras.layers.Dense(128, activation="relu")) model.add(tf.keras.layers.Dense(2, activation="softmax"))完成了三个全连接神经网络层级的集成,构建了一个全连接神经网络模型。
-
神经网络模型编译
在完成神经网络层级的集成之后需要对神经网络模型进行编译,只有编译后才能对神经网络模型进行训练。
对神经网络模型进行编译是将高阶API转换成可以直接运行的低阶API
Sequential().compile()提供了神经网络模型的编译功能
model.compile(loss="sparse_categorical_crossentropy", optimizer= tf.keras.optimizers.Adam(0.01), metrics=["accuracy"] )在compile方法中需要定义三个参数,分别是loss、optimizer和metrics。
- loss参数用来配置模型的损失函数,可以通过名称调用tf.losses API中已经定义好的loss函数
- optimizer参数用来配置模型的优化器,可以调用tf.keras.optimizers API 配置模型所需要的优化器
- metrics参数用来配置模型评价的方法,如accuracy、mse等。
-
神经网络模型训练和保存
在神经网络模型编译后,可以使用准备好的训练数据对模型进行训练
Sequential().fit()方法提供了神经网络模型的训练功能。
Sequential().fit()有很多集成的参数需要配置,其中主要的配置参数如下:
-
x:配置训练的输入数据,可以是array或者tensor类型。
-
y:配置训练的标注数据,可以是array或者tensor类型。
-
batch_size:配置批大小,默认值是32。
-
epochs:配置训练的epochs的数量。
-
verbose:配置训练过程信息输出的级别,共有三个级别,分别是0、1、2。
- 0代表不输出任何训练过程信息
- 1代表以进度条的方式输出训练过程信息
- 2代表每个epoch输出一条训练过程信息。
-
validation_split:配置验证数据集占训练数据集的比例,取值范围为0~1
-
validation_data:配置验证数据集。如果已经配置validation_split参数,则可以不配置该参数。
如果同时配置validation_split和validation_data参数,那么validation_split参数的配置将会失效。
-
shuffle:配置是否随机打乱训练数据。当配置steps_per_epoch为None时,本参数的配置失效。
-
initial_epoch:配置进行fine-tune时,新的训练周期是从指定的epoch开始继续训练的。
-
steps_per_epoch:配置每个epoch训练的步数
可以使用save()或者save_weights()方法保存并导出训练得到的模型
在使用这两个方法时需要分别配置以下参数:

-
-
神经网络模型加载和预测
当需要使用模型进行预测时,可以使用tf.keras.models中的load_model()方法重新加载已经保存的模型文件。
在完成模型文件的重新加载之后,可以使用predict()方法对数据进行预测输出。
在使用这两个方法时需要分别进行如下参数配置:

tf.keras.layers.Conv2D
使用Conv2D可以创建一个卷积核来对输入数据进行卷积计算,然后输出结果,其创建的卷积核可以处理二维数据。
Conv1D可以用于处理一维数据,Conv3D可以用于处理三维数据。
在进行神经网络层级集成时,如果使用该层作为第一层级,则需要配置input_shape参数。
在使用Conv2D时,需要配置的主要参数如下:
-
filters:配置输出数据的维度,数值类型是整型。
-
kernel_size:配置卷积核的大小。这里使用的是二维卷积核,因此需要配置卷积核的长和宽。
数值是包含两个整型元素值的列表或者元组。
-
strides:配置卷积核在做卷积计算时移动步幅的大小,分为X、Y两个方向的步幅。
数值是包含两个整型元素值的列表或者元组,当 X、Y 两个方向的步幅大小一样时,只需要配置一个步幅即可。
-
padding:配置图像边界数据处理策略。SAME表示补零,VALID表示不进行补零。
-
在进行卷积计算或者池化时都会遇到图像边界数据处理的问题,当边界像素不能正好被卷积或者池化的步幅整除时,只能在边界外补零凑成一个步幅长度,或者直接舍弃边界的像素特征。
-
data_format:配置输入图像数据的格式,默认格式是channels_last,也可以根据需要设置成channels_first。
图像数据的格式分为**channels_last(batch, height, width, channels)和channels_first(batch, channels, height, width)**两种。
-
dilation_rate:配置使用扩张卷积时每次的扩张率。
-
activation:配置激活函数,如果不配置则不会使用任何激活函数。
-
use_bias:配置该层的神经网络是否使用偏置向量
-
kernel_initializer:配置卷积核的初始化
-
bias_initializer:配置偏置向量的初始化
tf.keras.layers.MaxPool2D
MaxPool2D的作用是对卷积层输出的空间数据进行池化,采用的池化策略是最大值池化。
在使用MaxPool2D时需要配置的参数如下:
-
pool_size:配置池化窗口的维度,包括长和宽。数值是包含两个整型元素值的列表或者元组。
-
strides:配置卷积核在做池化时移动步幅的大小,分为 X、Y 两个方向的步幅。数值是包含两个整型元素值的列表或者元组,默认与pool_size相同。
-
padding:配置处理图像数据进行池化时在边界补零的策略。SAME表示补零,VALID表示不进行补零。
在进行卷积计算或者池化时都会遇到图像边界数据的问题,当边界像素不能正好被卷积或者池化的步幅整除时,就只能在边界外补零凑成一个步幅长度,或者直接舍弃边界的像素特征。
-
data_format:配置输入图像数据的格式,默认格式是channels_last,也可以根据需要设置成channels_first。
在进行图像数据处理时,图像数据的格式分为channels_last(batch, height, width, channels)和channels_first(batch, channels, height, width)两种。
tf.keras.layers.Flatten与tf.keras.layer.Dense
-
Flatten将输入该层级的数据压平,不管输入数据的维度数是多少,都会被压平成一维。
这个层级的参数配置很简单,只需要配置data_format即可。
data_format可被设置成channels_last或channels_first,默认值是channels_last。
-
Dense提供了全连接的标准神经网络。
tf.keras.layers.Dropout
对于Dropout在神经网络模型中具体作用的认识,业界分为两派
- 一派认为Dropout极大简化了训练时神经网络的复杂度,加快了神经网络的训练速度
- 另一派认为Dropout的主要作用是防止神经网络的过拟合,提高了神经网络的泛化性。
简单来说,Dropout的工作机制就是每步训练时按照一定的概率随机使神经网络的神经元失效,这样可以极大降低连接的复杂度。
同时由于每次训练都是由不同的神经元协同工作的,这样的机制也可以很好地避免数据带来的过拟合,提高了神经网络的泛化性。
在使用Dropout时,需要配置的参数如下:
- rate:配置神经元失效的概率。
- noise_shape:配置Dropout的神经元。
- seed:生成随机数
tf.keras.optimizers.Adam
Adam是一种可以替代传统随机梯度下降算法的梯度优化算法,它是由OpenAI的Diederik Kingma和多伦多大学的Jimmy Ba在2015年发表的ICLR论文(Adam:A Method for Stochastic Optimization)中提出的。
Adam具有计算效率高、内存占用少等优势,自提出以来得到了广泛应用。
Adam和传统的梯度下降优化算法不同,它可以基于训练数据的迭代情况来更新神经网络的权重,并通过计算梯度的一阶矩估计和二阶矩估计来为不同的参数设置独立的自适应学习率。
Adam适用于解决神经网络训练中的高噪声和稀疏梯度问题,它的超参数简单、直观并且只需要少量的调参就可以达到理想的效果。
官方推荐的最优参数组合为(alpha=0.001, beta_1=0.9, beta_2=0.999, epsilon=10E-8),在使用时可以配置如下参数。
- learning_rate:配置学习率,默认值是0.001。
- beta_1:配置一阶矩估计的指数衰减率,默认值是0.9。
- beta_2:配置二阶矩估计的指数衰减率,默认值是0.999。
- epsilon:该参数是一个非常小的数值,防止出现除以零的情况。
- amsgrad:配置是否使用AMSGrad。
- name:配置优化器的名称。
项目工程结构设计
整个项目工程结构分为两部分:
- 文件夹
- 代码文件
把所有的Python代码文件放在根目录下
其他静态文件、训练数据文件和模型文件等都放在文件夹中。
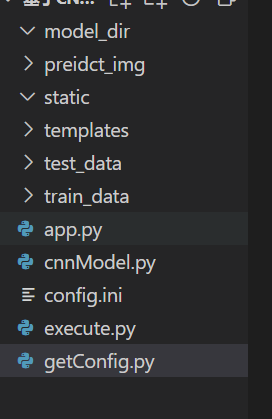
项目分为四个部分:配置工具、CNN模型、执行器和应用程序。
- 配置工具提供了将神经网络超参数配置动作通过配置文件进行调整的功能
- CNN模型是为了完成本项目的需求而设计的卷积神经网络
- 执行器中定义了训练数据读取、训练模型保存、模型预测等一系列方法
- 应用程序是一个基于Flask的简单Web应用程序,用于人机交互。
文件夹中:
- model_dir 存放的是训练结果模型文件,也是在预测时加载模型文件的路径
- predict_img 存放的是上传的图像,通过调用预测程序进行预测
- train_data 存放的是训练数据
- test_data : 存放测试数据
- static和templates存放的是Web应用程序所需的HTML、JS等静态文件
项目实现代码
工具类实现
定义一个工具类来读取配置文件中的配置参数,当需要调参时,只需对配置文件中的参数进行调整即可
# 引入configparser包,是Python中用于读取配置文件的包。
# 配置文件的格式可以为:[](其中包含的为section)
神经网络超参数的配置文件:
[strings]
#Mode: train, test, serve配置执行器的工作模式
mode = train
#配置模型文件的存储路径
working_directory = model_dir
#配置训练文件的路径
dataset_path=train_data/
[ints]
#配置分类图像的种类数量
num_dataset_classes=10
#配置训练数据的总大小
dataset_size=50000
#配置图像输入的尺寸
im_dim=32
num_channels = 3
#配置训练文件的数量
num_files=5
#配置每个训练文件中的图像数量
images_per_file=10000
#配置批训练数据的大小
batch_size=32
[floats]
#配置Dropout神经元失效的概率
rate=0.5
import configparser
#定义读取配置文件函数,分别读取section的配置参数,section包括ints、floats、strings
def get_config(config_file='config.ini'):
parser=configparser.ConfigParser()
parser.read(config_file)
#获取整型参数,按照key-value的形式保存
_conf_ints = [(key, int(value)) for key, value in parser.items ('ints')]
#获取浮点型参数,按照key-value的形式保存
_conf_floats = [(key, float(value)) for key, value in parser.items ('floats')]
#获取字符型参数,按照key-value的形式保存
_conf_strings = [(key, str(value)) for key, value in parser.items ('strings')]
#返回一个字典对象,包含读取的参数
return dict(_conf_ints + _conf_floats + _conf_strings)
cnnModel实现
采用tf.keras这个高阶API类,定义了3层卷积神经网络,输出维度分别是32、64、128
最后在输出层定义一层全连接神经网络,输出维度是10
在定义卷积神经网络过程中,按照一个卷积神经网络标准的结构进行定义,使用最大池化(maxpooling)策略进行降维特征提取,使用Dropout防止过拟合。
引入所需要的依赖包: tensorflow、numpy以及自定义配置获取包getConfig
import tensorflow as tf
import numpy as np
import getConfig
#初始化一个字典,用于存放配置获取函数返回的配置参数
gConfig={
}
gConfig=getConfig.get_config(config_file='config.ini')
#定义cnnModel方法类,object类型,这样在执行器中可以直接实例化一个CNN进行训练
class cnnModel(object):
def __init__(self , rate):
#定义Droupt神经元失效的概率
self.rate=rate
#定义一个网络模型,这是使用tf.keras.Sequential进行网络模型定义的标准形式
def createModel(self):
#实例化一个Sequnential,接下来就可以使用add方法来叠加所需的网络层
model=tf.keras.Sequential()
'''
添加一个二维卷积层,输出数据维度为32,卷积核维度为3×3。
输入数据维度为[32,32,3],这里的维度是WHC格式的,意思是输入图像像素为32×32的尺寸,使用3通道也就是RGB的像素值。
同样,如果图像是64×64尺寸的,则可以设置输入数据维度为[64,64,3]
'''
model.add(tf.keras.layers.Conv2D(32, (3,3), kernel_initializer='he_normal', strides=1, padding='same', activation='relu',input_shape=[32,32,3], name="conv1"))
#添加一个二维池化层,使用最大值池化,池化维度为2×2。也就是说,在一个2×2的像素区域内取一个像素最大值作为该区域的像素特征
model.add(tf.keras.layers.MaxPool2D((2,2), strides=1,padding='same', name="pool1"))
#添加一个批量规范化层BacthNormalization
model.add(tf.keras.layers.BacthNormalization())
#添加第二个卷积层,输出数据维度为64,卷积核维度是2×2
model.add(tf.keras.layers.Conv2D(64, (3,3), kernel_initializer='he_normal', strides=1, padding='same',activation='relu', name="conv2"))
#添加第二个二维池化层,使用最大值池化,池化维度为2×2
model.add(tf.keras.layers.MaxPool2D((2,2), strides=1,padding='same', name="pool2"))
#添加一个批量规范化层BacthNormalization
model.add(tf.keras.layers.BacthNormalization())
#添加第三个卷积层,输出数据维度为128,卷积核维度是2×2
model.add(tf.keras.layers.Conv2D(128, (3,3), kernel_initializer='he_normal', strides=1, padding='same',activation='relu', name="conv3"))
#添加第三个二维池化层,使用最大值池化,池化维度为2×2
model.add(tf.keras.layers.MaxPool2D((2,2), strides=1,padding='same', name="pool3"))
#添加一个批量池化层BacthNormalization
model.add(tf.keras.layers.BacthNormalization())
#添加第四个卷积层,输出数据维度为128,卷积核维度是2×2
#model.add(tf.keras.layers.Conv2D(256, (3,3), kernel_initializer='he_normal', strides=1, padding='same',activation='relu', name="conv4"))
#添加第四个二维池化层,使用最大值池化,池化维度为2×2
#model.add(tf.keras.layers.MaxPool2D((2,2), strides=1,padding='same', name="pool4"))
#添加一个批量池化层BacthNormalization
#model.add(tf.keras.layers.BacthNormalization())
'''
在经过卷积和池化完成特征提取之后,紧接着就是一个全连接的深度神经网络。在将数据输入深度神经网络之前主要进行数据的Flatten操作,就是将之前
长、宽像素值三个维度的数据压平成一个维度,这样可以减少参数的数量。因此在卷积层和全连接神经网络之间添加一个Flatten层
'''
model.add(tf.keras.layers.Flatten(name="flatten"))
#添加一个Dropout层,防止过拟合,加快训练速度
model.add(tf.keras.layers.Dropout(rate=self.rate, name="d3"))
#最后一层作为输出层,因为是进行图像的10分类,所以输出数据维度是10,使用softmax作为激活函数。
# softmax是一个在多分类问题上使用的激活函数,
#如果是二分类问题,则sotfmax和sigmod的作用是类似的
model.add(tf.keras.layers.Dense(10, activation='softmax'))
#在完成神经网络的设计后,我们需要对网络模型进行编译,生成可以训练的模型。
# 在进行编译时,需要定义损失函数(loss)、优化器(optimizer)、模型评价标准(metrics)
# 这些都可以使用高阶API直接调用
model.compile(loss="categorical_crossentropy", optimizer=tf.keras.optimizers.Adam(), metrics=["accuracy"])
return model
执行器实现
执行器的主要作用是读取训练数据、实例化神经网络模型、循环训练神经网络模型、保存神经网络模型和调用模型完成预测。
在执行器的实现上需要定义以下函数:
- read_data函数用于读取训练集数据
- create_model函数用于进行神经网络的实例化
- train函数用于进行神经网络模型的循环训练和保存
- predict函数用于进行模型加载和结果预测
#导入所需要的依赖包
import tensorflow as tf
import numpy as np
from cnnModel import cnnModel
import os
import pickle
import getConfig
label_names_dict=classes = ('plane', 'car', 'bird', 'cat', 'deer','dog', 'frog', 'horse', 'ship', 'truck')
gConfig = {
}
#调用get_config读取配置文件中的参数
gConfig=getConfig.get_config(config_file="config.ini")
#定义数据读取函数,在这个函数中完成数据读取、格式转换操作
def read_data(dataset_path, im_dim, num_channels, num_files,images_per_file):
#获取文件夹中的数据文件名
# ['data_batch_1', 'data_batch_2', 'data_batch_3', 'data_batch_4', 'data_batch_5']
files_names = os.listdir(dataset_path)
#获取训练集中训练文件的名称
"""
在CIFAR-10中已经为我们标注和准备好了数据。
在训练集中一共有50000个训练样本,放到5个二进制文件中,每个样本有 3072个像素点,维度是32×32×3
"""
#创建空的多维数组用于存放图像二进制数据
# 总的文件个数,图像w, 图像h,channels
dataset_array = np.zeros(shape=(num_files * images_per_file, im_dim, im_dim, num_channels))
#创建空的数组用于存放图像的标注信息
dataset_labels = np.zeros(shape=(num_files * images_per_file), dtype=np.uint8)
index = 0
#从训练集中读取二进制数据并将其维度转换成32×32×3
for file_name in files_names:
if file_name[0:len(file_name)-1] == "data_batch_":
print("正在处理数据 : ", file_name)
data_dict = unpickle_patch(dataset_path + file_name)
# 获取数据
images_data = data_dict[b"data"]
#print(images_data.shape)
#将格式转换为32×32×3形状
images_data_reshaped = np.reshape(images_data,newshape= (len(images_data), im_dim, im_dim, num_channels))
#将维度转换后的图像数据存入指定数组内
dataset_array[index * images_per_file:(index + 1) * images_per_file, :, :, :] = images_data_reshaped
#将维度转换后的标注数据存入指定数组内
dataset_labels[index * images_per_file: (index + 1) * images_per_file] = data_dict[b"labels"]
index = index + 1
return dataset_array, dataset_labels # 返回数据
#定义pickle文件格式的数据读取函数,pickle是一个二进制文件,我们需要读取其中的数据并将数据放入一个字典中
def unpickle_patch(file):
#打开文件,读取二进制文件,返回读取到的数据
patch_bin_file = open(file, 'rb')
patch_dict = pickle.load(patch_bin_file, encoding='bytes')
patch_bin_file.close()
return patch_dict
#定义模型实例化函数,主要判断是否有预训练模型,如果有则优先加载预训练模型;
#判断是否有已经保存的训练文件,如果有则加载该文件继续训练,否则构建实例化神经网络模型进行训练。
def create_model():
#判断是否存在预训练模型
if 'pretrained_model'in gConfig:
model=tf.keras.models.load_model(gConfig['pretrained_model'])
return model
#判断是否存在模型文件,如果存在则加载该模型文件并继续训练;如果不存在则新建模型相关文件
ckpt=tf.io.gfile.listdir(gConfig['working_directory'])
if ckpt:
model_file=os.path.join(gConfig['working_directory'],ckpt[-1])
print("Reading model parameters from %s" % model_file)
model=tf.keras.models.load_model(model_file)
return model
else:
model=cnnModel(gConfig['rate'])
model=model.createModel()
return model
#定义训练函数
def train():
#读取训练集的数据,根据read_data函数的参数定义需要传入dataset_path、im_dim、num_channels、num_files、images_per_file
dataset_array, dataset_labels = read_data(dataset_path=gConfig['dataset_path'], im_dim=gConfig['im_dim'], num_channels=gConfig['num_channels'], num_files=gConfig ['num_files'], images_per_file=gConfig['images_per_file'])
#对训练输入数据进行归一化处理,取值范围为(0,1)
dataset_array= dataset_array.astype('float32')/255
#对标注数据进行one-hot编码
dataset_labels=tf.keras.utils.to_categorical(dataset_labels,10)
#实例化一个神经网络模型
model=create_model()
#开始进行模型训练
model.fit(dataset_array, dataset_labels, verbose=1, epochs=100, validation_split=0.2)
#将完成训练的模型保存起来
filename=gConfig["modelfile"]
print(filename)
checkpoint_path = os.path.join(gConfig['working_directory'], filename)
model.save(checkpoint_path)
if gConfig['mode']=='server':
#获取最新的模型文件路径
ckpt=os.listdir(gConfig['working_directory'])[0]
checkpoint_path = os.path.join(gConfig['working_directory'], ckpt )
#加载模型文件
model=tf.keras.models.load_model(checkpoint_path)
#定义预测函数,加载所保存的模型文件并进行预测
def predict(data):
#对数据进行预测
predicton=model.predict(data)
#使用argmax获取预测结果
index=tf.math.argmax(predicton[0]).numpy()
#返回预测的分类名称
return label_names_dict[index]
if __name__=='__main__':
if gConfig['mode']=='train':
train()
elif gConfig['mode']=='server':
print('请运行app.py')
对训练数据进行归一化处理
Web应用实现
Web应用的主要功能包括完成页面交互、图片格式判断、图片上传以及预测结果的返回展示。
使用Flask这个轻量级Web应用框架来实现简单的页面交互和预测结果展示功能。
import flask
import werkzeug
import os
import execute
import getConfig
import flask
import numpy as np
from PIL import Image
gConfig = {
}
gConfig = getConfig.get_config(config_file='config.ini')
secure_filename = ""
#实例化一个Flask应用,命名为imgClassifierWeb
app = flask.Flask("imgClassifierWeb")
#定义预测函数
def CNN_predict():
#全局声明一个文件名
global secure_filename
#从本地目录中读取需要分类的图片
img = Image.open(os.path.join(app.root_path, secure_filename))
#将读取的像素格式转换为RGB,并分别获取RGB通道对应的像素数据
r, g, b=img.split()
#分别将获取的像素数据放入数组中
r_arr=np.array(r)
g_arr=np.array(g)
b_arr=np.array(b)
#将三个数组进行拼接
img=np.concatenate((r_arr, g_arr, b_arr))
#对拼接后的数据进行维度变换和归一化处理
image=img.reshape([1,32,32,3])/255
#调用执行器execute的predict函数对图像数据进行预测
predicted_class=execute.predict(image)
#将返回的结果用页面模板渲染出来
return flask.render_template(template_name_or_list="prediction_result.html", predicted_class=predicted_class)
app.add_url_rule(rule="/predict/", endpoint="predict", view_func=CNN_predict)
def upload_image():
global secure_filename
if flask.request.method == "POST": #设置request的模式为POST
#获取需要分类的图片
img_file = flask.request.files["image_file"]
#生成一个没有乱码的文件名
secure_filename = werkzeug.utils.secure_filename(img_file.filename)
print(secure_filename)
#获取图片的保存路径
img_path = os.path.join(app.root_path, secure_filename)
#将图片保存在应用的根目录下
img_file.save(img_path)
print("图片上传成功.")
return flask.redirect(flask.url_for(endpoint="predict"))
return "图片上传失败"
#增加图片上传的路由入口
app.add_url_rule(rule="/upload/", endpoint="upload", view_func=upload_image, methods=["POST"])
def redirect_upload():
return flask.render_template(template_name_or_list="upload_image.html")
#增加默认主页的路由入口
app.add_url_rule(rule="/", endpoint="homepage", view_func=redirect_upload)
if __name__ == "__main__":
app.run(host="0.0.0.0", port=7777, debug=False)
程序下载
https://download.csdn.net/download/first_bug/85447520
参考
《走向TensorFlow2.0》