本文来自提案JVET-T0069《SSIM based CNN model for in-loop filtering》,目前大部分基于深度学习的视频编码研究都是优化客观指标,然而对于人眼视觉来说更高的客观指标有时候并不意味着更高的主观效果。因此,该提案提出神经网络模型CNNLF(convolutional neural network based in-loop filter)来进行主观优化。
简介
CNNLF用于环路滤波阶段,处于deblocking之后,SAO之前,如Fig.1所示。
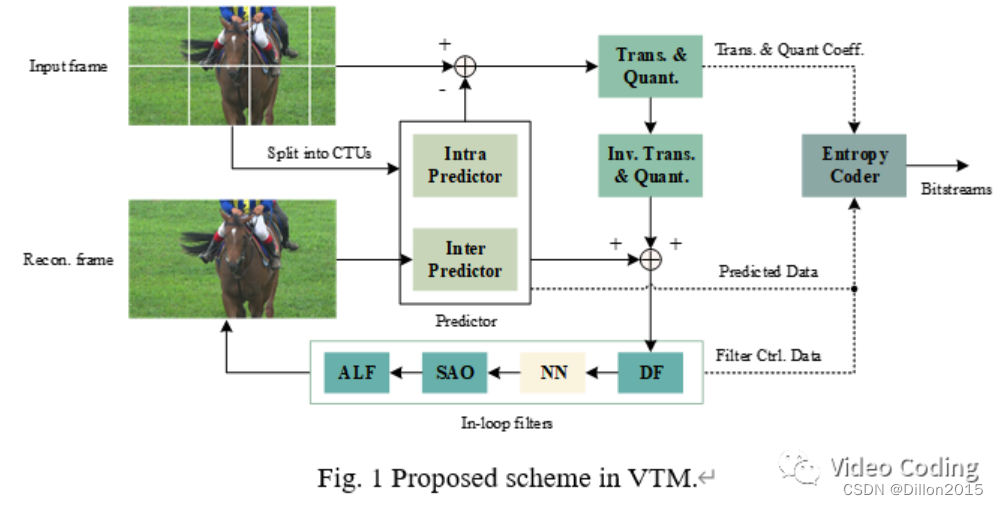
重建帧首先会使用DF滤波处理,然后经过CNNLF模型处理,最后送入SAO进一步处理。该方法作用于块级,通过RDO决定是否对块使用CNNLF处理,因此需要在码流中传递一个标志位表示是否使用了CNNLF。
网络结构
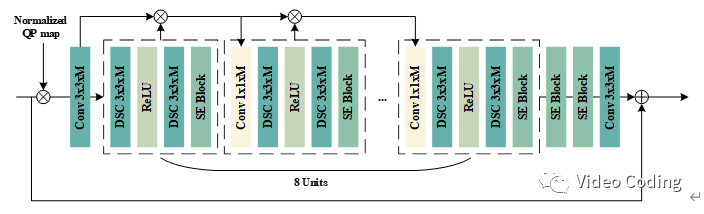
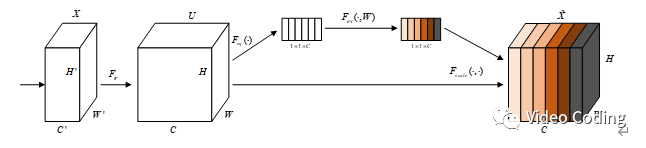
整个网络结构如图所示,由8个残差单元(3x3卷积)构成,除了最后一个卷积层生成3维输出外,其他卷积层都生成64维特征。最后有两个SE块和一个3x3卷积连接在网络后用于自适应的混合特征生成最终重建图像。注意,第一个残差单元中没有使用1x1卷积。网络中的短接可以促进浅层特征的流动。
残差单元
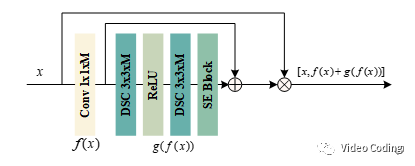
如上图,残差单元由一个1x1卷积层和两个3x3卷积层构成,激活函数为ReLU,其中单元里还有两个短接和一个SE块(squeeze-and-excitation block)。
短接将1x1卷积的输出和3x3卷积的输出相加可以学习残差。下式中x是输入,F(x)是整个输出,f()表示1x1卷积操作,g()表示残差学习。
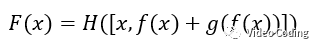
SE块结构如下图,它将特征处理为多通道形式。它通过显示建模特征通道间的依赖关系来自适应的校准特征通道,有利于模型学习压缩信息。
训练
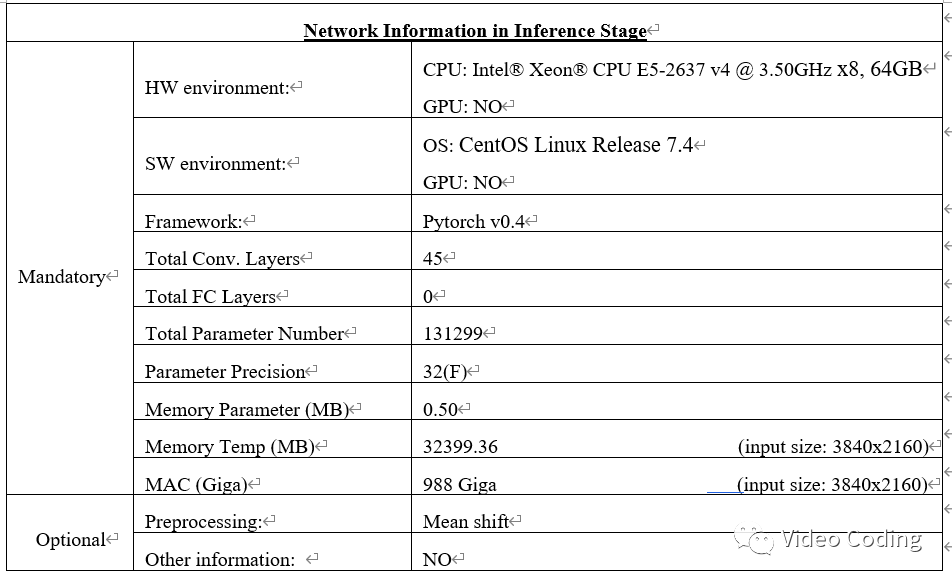
模型使用DIV2K数据集训练,包含800张训练图像,100张验证图像,所有图像都使用VTM10.0在AI配置下编码,QP={22,27,32,37}。对于不同QP只训练一个模型。且训练指标使用SSIM,测试指标使用VMAF,因为VMAF不连续所以不适合在训练中使用。训练配置如表1,其中loss函数使用了SSIM和L1 loss的加权,这里使用了两套权重参数(0.2,0.8)和(0.8,0.2)

实验结果
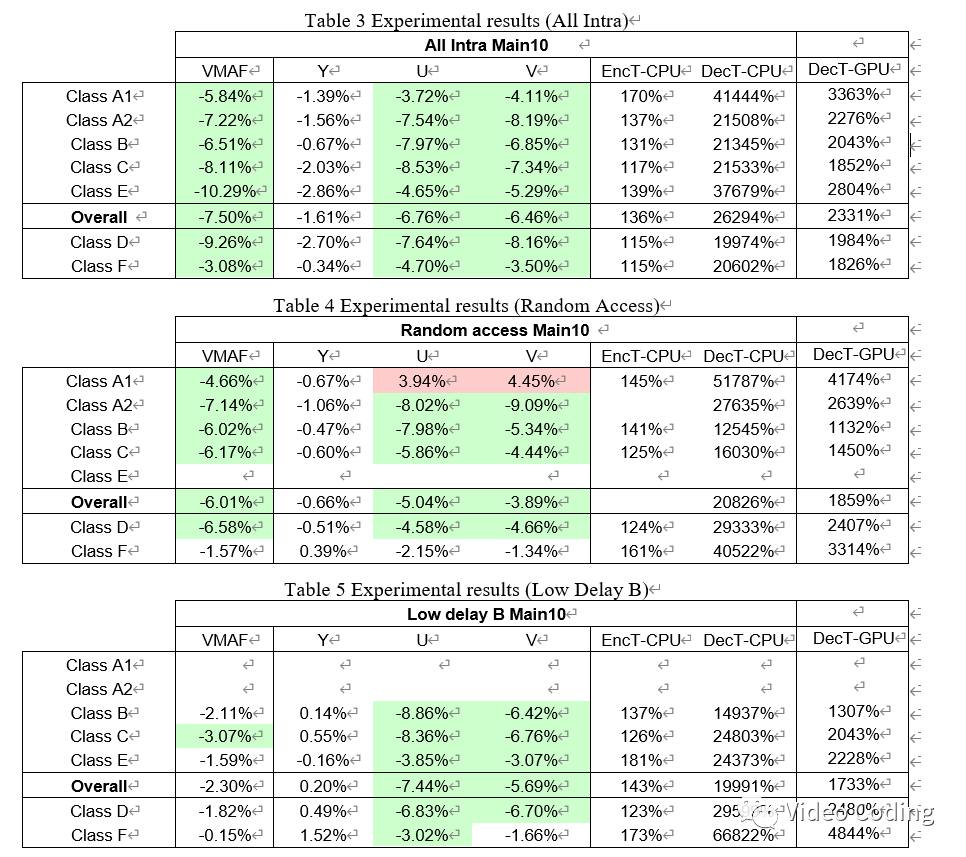
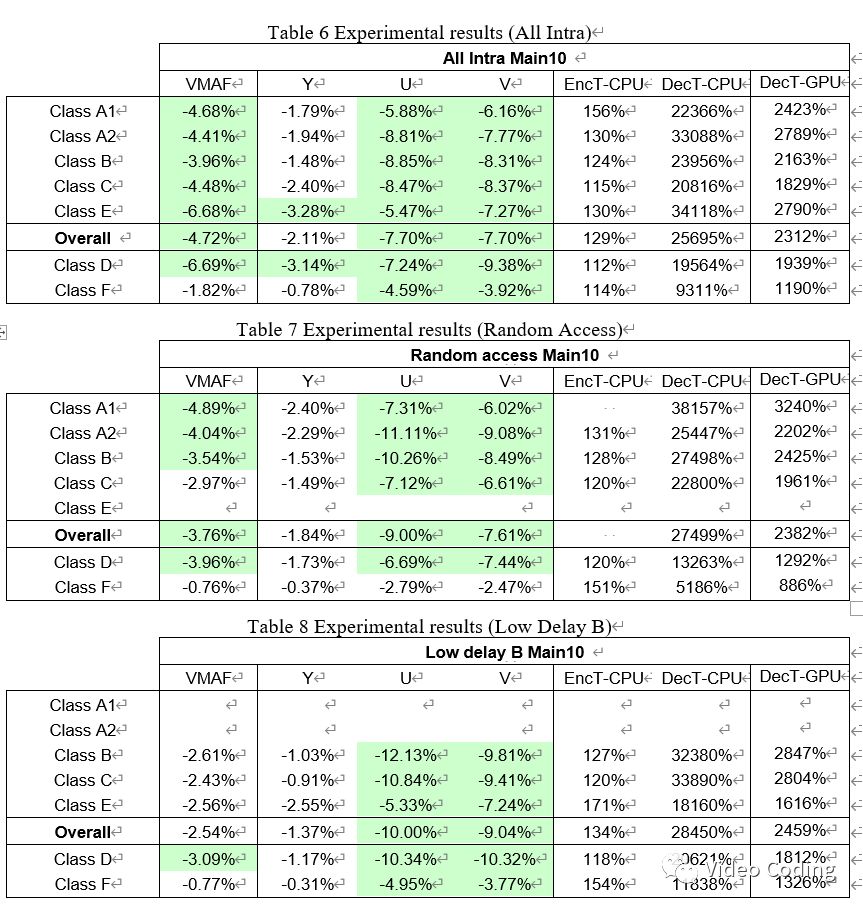
实验测试配置为AI、RA和LDB,QP={22,27,32,37}。其中由于计算复杂度较高,RA配置只跑第一个GOP。YUV编码时不使用GPU,解码会用GPU和CPU各解码一遍。
Loss = 0.8 x SSIM + 0.2 x L1
Loss = 0.2 x SSIM + 0.8 x L1
感兴趣的请关注微信公众号Video Coding
