和hadoop一样,学习spark从WordCount开始。
- 启动Spark Shell
spark-shell是Spark自带的交互式Shell程序,方便用户进行交互式编程,用户可以在该命令行下用scala编写spark程序。
执行命令 bin/spark-shell
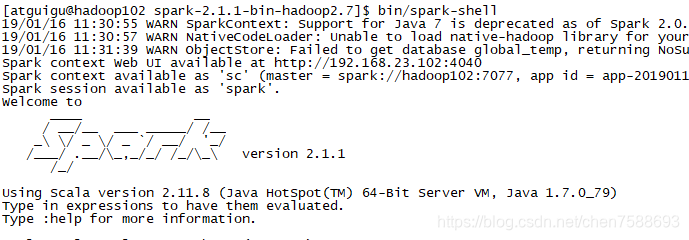
- 启动hdfs
上传一个文档到hdfs
- 编写WordCount
在Spark shell中用scala语言编写spark程序
sc.textFile("hdfs://hadoop02:9000/RELEASE").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("hdfs://hadoop02:9000/out1")
提交后,在hdfs中查看结果
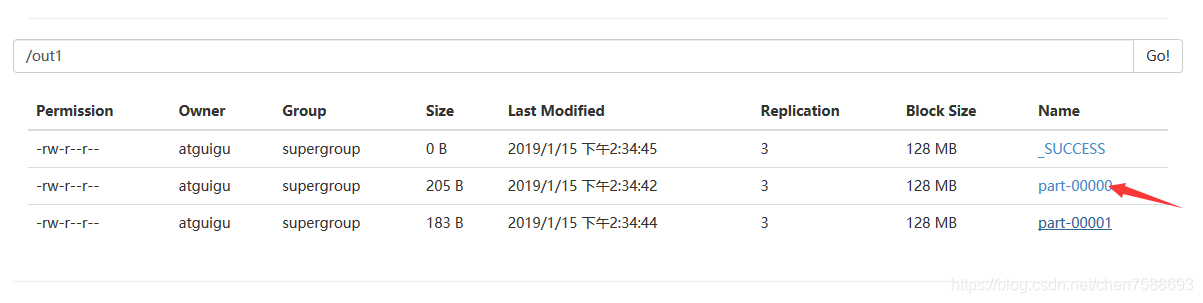
这就是执行后的WordCount结果。
- 代码解析:
sc 是SparkContext对象,该对象时提交spark程序的入口
textFile(hdfs://hadoop102:9000/RELEASE) 是hdfs中读取数据
flatMap(_.split(" "))先map在压平
map((_,1)) 将单词和1构成元组
reduceByKey(_+_) 按照key进行reduce,并将value累加
saveAsTextFile("hdfs:// hadoop102:9000/out1") 将结果写入到hdfs中