在hadoop生态中,wordcount是hadoop世界的第一个hello world程序。
wordcount程序是用于对文本中出现的词计数,从而得到词频,本例中的词以空格分隔。
关于mapper、combiner、shuffler、reducer等含义请参照Hadoop权威指南里的说明。
1、hadoop平台搭建
参照之前的帖子搭一个伪分布式的hadoop就可以。链接:https://www.cnblogs.com/asker009/p/9126354.html
2、新建一个普通console程序,引入maven框架。
引入hadoop核心依赖,注意hadoop平台用的3.1版本,引入的依赖尽量使用这个版本,以免出现版本兼容问题
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.0</version>
</dependency>
检查版本
[hadoop@hp4411s ~]$ hadoop version Hadoop 3.1.0 Source code repository https://github.com/apache/hadoop -r 16b70619a24cdcf5d3b0fcf4b58ca77238ccbe6d Compiled by centos on 2018-03-30T00:00Z Compiled with protoc 2.5.0 From source with checksum 14182d20c972b3e2105580a1ad6990 This command was run using /opt/hadoop/hadoop-3.1.0/share/hadoop/common/hadoop-common-3.1.0.jar
3、编写mapper
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * @Author: xu.dm * @Date: 2019/1/29 16:44 * @Description: 读取采用空格分隔的字符,并且每个词计数为1 */ public class WordCountMapper extends Mapper<Object, Text, Text, IntWritable> { @Override protected void map(Object key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] words = line.split(" "); for (String word : words) { System.out.println(word); context.write(new Text(word), new IntWritable(1)); } } }
4、编写reducer
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * @Author: xu.dm * @Date: 2019/1/29 16:44 * @Description:累加由map传递过来的计数 */ public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for(IntWritable val:values) { sum+=val.get(); } context.write(key,new IntWritable(sum)); } }
5、关于shuffle过程,shuffle过程是由hadoop系统内部完成,shuffle是在map和reduce之间,对map的结果进行清洗、组合的过程。
借用hadoop权威指南里的一个图来类比说明

假设我们的数据样本是:
那么在map阶段形成的数据是:
hadoop 1 hadoop 1 abc 1 abc 1 test 1 test 1 wow 1 wow 1 wow 1 ... ...
经过shuffle后大概是这样:
hadoop [1,1] abc [1,1] test [1,1] wow [1,1,1] ... ...
其中还有排序什么的。
shuffle其实就是性能关键点。shuffle的结果传递给reduce,reduce根据需求决定如何处理这些数据,本例中就是简单的求和。
6、程序入口,任务调度执行等
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static void main(String[] args) throws Exception { if(args.length!=2) { System.err.println("使用格式:WordCount <input path> <output path>"); System.exit(-1); } Configuration conf =new Configuration(); Job job = Job.getInstance(conf,"word count"); job.setJarByClass(WordCount.class); job.setMapperClass(WordCountMapper.class); // job.setCombinerClass(WordCountReducer.class); job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job,new Path(args[0])); FileOutputFormat.setOutputPath(job,new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
7、放入hadoop平台中执行
1、打成wordcount.jar包
2、上传jar包到hadoop用户目录下
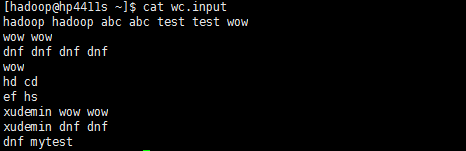
3、在hadoop用户目录下,用vi生成一个测试文档wc.input,里面随意填入一些词,用空格分隔词。本例中是:
[hadoop@hp4411s ~]$ cat wc.input
hadoop hadoop abc abc test test wow
wow wow
dnf dnf dnf dnf
wow
hd cd
ef hs
xudemin wow wow
xudemin dnf dnf
dnf mytest
4、将wc.input上传到hdfs文件系统中的/demo/input
hadoop fs -mkdir -p /demo/input
hadoop fs -put wc.input /demo/input
hadoop fs -ls /demo/input
5、用hadoop执行jar包,输出结果到/demo/output,注意output目录不能存在,hadoop会自己建立这个目录,这是hadoop内部的一个机制,如果有这个目录,程序无法执行。
hadoop jar wordcount.jar /demo/input /demo/output
6、查看运行结果,目录下有_SUCCESS文件,表示执行成功,结果在part-r-00000中
[hadoop@hp4411s ~]$ hadoop fs -ls /demo/output
Found 2 items
-rw-r--r-- 1 hadoop supergroup 0 2019-01-30 03:42 /demo/output/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 73 2019-01-30 03:42 /demo/output/part-r-00000
7、查看part-r-00000
[hadoop@hp4411s ~]$ hadoop fs -cat /demo/output/part-r-00000
abc 2
cd 1
dnf 7
ef 1
hadoop 2
hd 1
hs 1
mytest 1
test 2
wow 6
xudemin 2
8、关于combiner,上述执行job的时候,程序注释了一段代码// job.setCombinerClass(WordCountReducer.class);
在Hadoop中,有一种处理过程叫Combiner,与Mapper和Reducer在处于同等地位,但其执行的时间介于Mapper和Reducer之间,其实就是Mapper和Reducer的中间处理过程,Mapper的输出是Combiner的输入,Combiner的输出是Reducer的输入。
combiner是什么作用?
因为hadoop的数据实际上是分布在各个不同的datanode,在mapper后,数据需要在从datanode上传输,如果数据很大很多,则会在网络上花费不少时间,而combiner可以先对数据进行处理,减少传输量。
处理的方式是自定义的,本例中,combiner可以先对数据累加,实际上是执行了WordCountReducer类的内容,但是combine因为不是最后阶段,所以它只是帮组程序先累加了部分数据,并没有累加所有数据。
实际已经减少了mapper传递的kv数据量,最终到reducer阶段需要累加的数据已经减少了。
注意:combine是不会改变最终的reducer的结果,它是一个优化手段
用hadoop权威指南里天气数据的例子更深入解释:
例如获取历年的最高温度例子,以书中所说的1950年为例,在两个不同分区上的Mapper计算获得的结果分别如下: 第一个Mapper结果:(1950, [0, 10, 20]) 第二个Mapper结果:(1950, [25, 15]) 如果不考虑Combiner,按照正常思路,这两个Mapper的结果将直接输入到Reducer中处理,如下所示: MaxTemperature:(1950, [0, 10, 20, 25, 15]) 最终获取的结果是25。 如果考虑Combiner,按照正常思路,这两个Mapper的结果将分别输入到两个不同的Combiner中处理,获得的结果分别如下所示: 第一个Combiner结果:(1950, [20]) 第二个Combiner结果:(1950, [25]) 然后这两个Combiner的结果会输出到Reducer中处理,如下所示 MaxTemperature:(1950, [20, 25]) 最终获取的结果是25。 由上可知:这两种方法的结果是一致的,使用Combiner最大的好处是节省网络传输的数据,这对于提高整体的效率是非常有帮助的。 但是,并非任何时候都可以使用Combiner处理机制,例如不是求历年的最高温度,而是求平均温度,则会有另一种结果。同样,过程如下, 如果不考虑Combiner,按照正常思路,这两个Mapper的结果将直接输入到Reducer中处理,如下所示: AvgTemperature:(1950, [0, 10, 20, 25, 15]) 最终获取的结果是14。 如果考虑Combiner,按照正常思路,这两个Mapper的结果将分别输入到两个不同的Combiner中处理,获得的结果分别如下所示: 第一个Combiner结果:(1950, [10]) 第二个Combiner结果:(1950, [20]) 然后这两个Combiner的结果会输出到Reducer中处理,如下所示 AvgTemperature:(1950, [10, 20]) 最终获取的结果是15。 由上可知:这两种方法的结果是不一致的,所以在使用Combiner时,一定是优化的思路,但是不能影响到最终结果。