通常我们在学习一门语言的时候,写的第一个程序就是Hello World。而在学习Hadoop时,我们要写的第一个程序就是词频统计WordCount程序。
一、MapReduce简介
1.1 MapReduce编程模型
MapReduce采用”分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单地说,MapReduce就是”任务的分解与结果的汇总”。
在Hadoop中,用于执行MapReduce任务的机器角色有两个:
- JobTracker用于调度工作的,一个Hadoop集群中只有一个JobTracker,位于master。
- TaskTracker用于执行工作,位于各slave上。
在分布式计算中,MapReduce框架负责处理了并行编程中分布式存储、工作调度、负载均衡、容错均衡、容错处理以及网络通信等复杂问题,把处理过程高度抽象为两个函数:map和reduce,map负责把任务分解成多个任务,reduce负责把分解后多任务处理的结果汇总起来。
需要注意的是,用MapReduce来处理的数据集(或任务)必须具备这样的特点:待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。
1.2 MapReduce工作过程
对于一个MR任务,它的输入、输出以及中间结果都是<key, value>键值对:
- Map:
<k1, v1>——>list(<k2, v2>) - Reduce:
<k2, list(v2)>——>list(<k3, v3>)
MR程序的执行过程主要分为三步:Map阶段、Shuffle阶段、Reduce阶段,如下图:
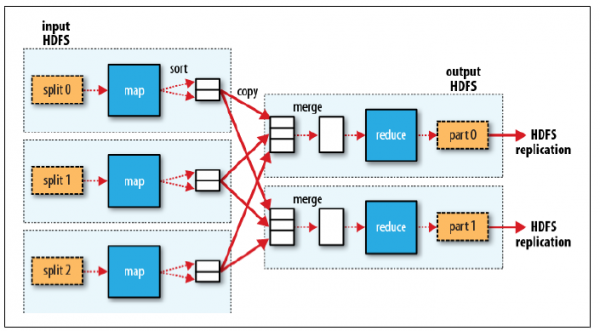
Map阶段
分片(Split):map阶段的输入通常是HDFS上文件,在运行Mapper前,FileInputFormat会将输入文件分割成多个split ——1个split至少包含1个HDFS的Block(默认为64M);然后每一个分片运行一个map进行处理。
执行(Map):对输入分片中的每个键值对调用
map()函数进行运算,然后输出一个结果键值对。- Partitioner:对
map()的输出进行partition,即根据key或value及reduce的数量来决定当前的这对键值对最终应该交由哪个reduce处理。默认是对key哈希后再以reduce task数量取模,默认的取模方式只是为了避免数据倾斜。然后该key/value对以及partitionIdx的结果都会被写入环形缓冲区。
- Partitioner:对
溢写(Spill):map输出写在内存中的环形缓冲区,默认当缓冲区满80%,启动溢写线程,将缓冲的数据写出到磁盘。
- Sort:在溢写到磁盘之前,使用快排对缓冲区数据按照partitionIdx, key排序。(每个partitionIdx表示一个分区,一个分区对应一个reduce)
- Combiner:如果设置了Combiner,那么在Sort之后,还会对具有相同key的键值对进行合并,减少溢写到磁盘的数据量。
合并(Merge):溢写可能会生成多个文件,这时需要将多个文件合并成一个文件。合并的过程中会不断地进行 sort & combine 操作,最后合并成了一个已分区且已排序的文件。
Shuffle阶段:广义上Shuffle阶段横跨Map端和Reduce端,在Map端包括Spill过程,在Reduce端包括copy和merge/sort过程。通常认为Shuffle阶段就是将map的输出作为reduce的输入的过程
Copy过程:Reduce端启动一些copy线程,通过HTTP方式将map端输出文件中属于自己的部分拉取到本地。Reduce会从多个map端拉取数据,并且每个map的数据都是有序的。
Merge过程:Copy过来的数据会先放入内存缓冲区中,这里的缓冲区比较大;当缓冲区数据量达到一定阈值时,将数据溢写到磁盘(与map端类似,溢写过程会执行 sort & combine)。如果生成了多个溢写文件,它们会被merge成一个有序的最终文件。这个过程也会不停地执行 sort & combine 操作。
Reduce阶段:Shuffle阶段最终生成了一个有序的文件作为Reduce的输入,对于该文件中的每一个键值对调用
reduce()方法,并将结果写到HDFS。
二、运行WordCount程序
在运行程序之前,需要先搭建好Hadoop集群环境,参考《Hadoop+HBase+ZooKeeper分布式集群环境搭建》。
2.1 源代码
WordCount可以说是最简单的MapReduce程序了,只包含三个文件:一个 Map 的 Java 文件,一个 Reduce 的 Java 文件,一个负责调用的主程序 Java 文件。
我们在当前用户的主文件夹下创建wordcount_01/目录,在该目录下再创建src/和classes/。 src 目录存放 Java 的源代码,classes 目录存放编译结果。
TokenizerMapper.java
package com.lisong.hadoop;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
IntWritable one = new IntWritable(1);
Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException,InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}IntSumReducer.java
package com.lisong.hadoop;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException,InterruptedException {
int sum = 0;
for(IntWritable val:values) {
sum += val.get();
}
result.set(sum);
context.write(key,result);
}
}WordCount.java
package com.lisong.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if(otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "wordcount");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}以上三个.java源文件均置于 src 目录下。
2.2 编译
Hadoop 2.x 版本中jar不再集中在一个 hadoop-core-*.jar 中,而是分成多个 jar。编译WordCount程序需要如下三个 jar:
$HADOOP_HOME/share/hadoop/common/hadoop-common-2.4.1.jar
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.4.1.jar
$HADOOP_HOME/share/hadoop/common/lib/commons-cli-1.2.jar使用javac命令进行编译:
$ cd wordcount_01
$ javac -classpath /home/hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jar:/home/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.6.0.jar:/home/hadoop/hadoop/share/hadoop/common/lib/commons-cli-1.2.jar -d classes/ src/*.java- -classpath,设置源代码里使用的各种类库所在的路径,多个路径用
":"隔开。 - -d,设置编译后的 class 文件保存的路径。
- src/*.java,待编译的源文件。
2.3 打包
将编译好的 class 文件打包成 Jar 包,jar 命令是 JDK 的打包命令行工具。
$ jar -cvf wordcount.jar classes打包结果是 wordcount.jar 文件,放在当前目录下。
2.4 执行
执行hadoop程序的时候,输入文件必须先放入hdfs文件系统中,不能是本地文件。
1 . 先查看hdfs文件系统的根目录:
$ hadoop/bin/hadoop fs -ls /
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2015-07-28 14:38 /hbase可以看出,hdfs的根目录是一个叫/hbase的目录。
2 . 然后利用put将输入文件(多个输入文件位于input文件夹下)复制到hdfs文件系统中:
$ hadoop/bin/hadoop fs -put input /hbase3 . 运行wordcount程序
$ hadoop/bin/hadoop jar wordcount_01/wordcount.jar WordCount /hbase/input /hbase/output提示找不到 WordCount 类:Exception in thread "main" java.lang.NoClassDefFoundError: WordCount…
因为程序中声明了 package ,所以在命令中也要 com.lisong.hadoop.WordCount 写完整:
$ hadoop/bin/hadoop jar wordcount_01/wordcount.jar com.lisong.hadoop.WordCount /hbase/input /hbase/output其中 “jar” 参数是指定 jar 包的位置,com.lisong.hadoop.WordCount 是主类。运行程序处理 input 目录下的多个文件,将结果写入 /hbase/output 目录。
4 . 查看运行结果
$ hadoop/bin/hadoop fs -ls /hbase/output
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2015-07-28 18:05 /hbase/output/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 33 2015-07-28 18:05 /hbase/output/part-r-00000可以看到/hbase/output/目录下有两个文件,结果就存在part-r-00000中:
$ hadoop/bin/hadoop fs -cat /hbase/output/part-r-00000
Google 6
Java 2
baidu 3
hadoop 4三、WordCount程序分析
3.1 Hadoop数据类型
Hadoop MapReduce操作的是键值对,但这些键值对并不是Integer、String等标准的Java类型。为了让键值对可以在集群上移动,Hadoop提供了一些实现了WritableComparable接口的基本数据类型,以便用这些类型定义的数据可以被序列化进行网络传输、文件存储与大小比较。
- 值:仅会被简单的传递,必须实现
Writable或WritableComparable接口。 - 键:在Reduce阶段排序时需要进行比较,故只能实现
WritableComparable接口。
下面是8个预定义的Hadoop基本数据类型,它们均实现了WritableComparable接口:
| 类 | 描述 |
|---|---|
| BooleanWritable | 标准布尔型数值 |
| ByteWritable | 单字节数值 |
| DoubleWritable | 双字节数 |
| FloatWritable | 浮点数 |
| IntWritable | 整型数 |
| LongWritable | 长整型数 |
| Text | 使用UTF8格式存储的文本 |
| NullWritable | 当<key,value>中的key或value为空时使用 |
3.2 源代码分析
3.2.1 Map过程
package com.lisong.hadoop;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
IntWritable one = new IntWritable(1);
Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException,InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}Map过程需要继承org.apache.hadoop.mapreduce包中 Mapper 类,并重写其map方法。
public class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>其中的模板参数:第一个Object表示输入key的类型;第二个Text表示输入value的类型;第三个Text表示表示输出键的类型;第四个IntWritable表示输出值的类型。
作为map方法输入的键值对,其value值存储的是文本文件中的一行(以回车符为行结束标记),而key值为该行的首字母相对于文本文件的首地址的偏移量。然后StringTokenizer类将每一行拆分成为一个个的单词,并将<word,1>作为map方法的结果输出,其余的工作都交有 MapReduce框架 处理。
注:StringTokenizer是Java工具包中的一个类,用于将字符串进行拆分——默认情况下使用空格作为分隔符进行分割。
3.2.2 Reduce过程
package com.lisong.hadoop;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException,InterruptedException {
int sum = 0;
for(IntWritable val:values) {
sum += val.get();
}
result.set(sum);
context.write(key,result);
}
}Reduce过程需要继承org.apache.hadoop.mapreduce包中 Reducer 类,并 重写 reduce方法。
public class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable>其中模板参数同Map一样,依次表示是输入键类型,输入值类型,输出键类型,输出值类型。
public void reduce(Text key, Iterable<IntWritable> values, Context context)reduce 方法的输入参数 key 为单个单词,而 values 是由各Mapper上对应单词的计数值所组成的列表(一个实现了 Iterable 接口的变量,可以理解成 values 里包含若干个 IntWritable 整数,可以通过迭代的方式遍历所有的值),所以只要遍历 values 并求和,即可得到某个单词出现的总次数。
3.2.3 执行作业
package com.lisong.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if(otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "wordcount");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}在MapReduce中,由Job对象负责管理和运行一个计算任务,并通过Job的一些方法对任务的参数进行相关的设置,此处:
- 设置了使用
TokenizerMapper.class完成Map过程中的处理,使用IntSumReducer.class完成Combine和Reduce过程中的处理。 - 还设置了Map过程和Reduce过程的输出类型:key的类型为Text,value的类型为IntWritable。
任务的输出和输入路径则由命令行参数指定,并由FileInputFormat和FileOutputFormat分别设定。
- FileInputFormat类的很重要的作用就是将文件进行切分 split,并将 split 进一步拆分成key/value对
- FileOutputFormat类的作用是将处理结果写入输出文件。
完成相应任务的参数设定后,即可调用
job.waitForCompletion()方法执行任务。
3.2.4 WordCount流程
1)将文件拆分成splits,由于测试用的文件较小,所以每个文件为一个split,并将文件按行分割形成<key,value>对,key为偏移量(包括了回车符),value为文本行。这一步由MapReduce框架自动完成,如下图:
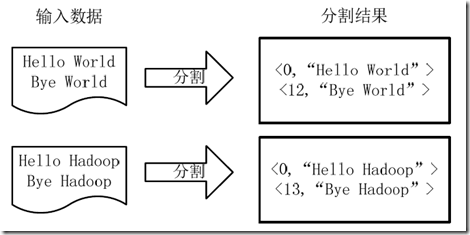
2)将分割好的<key,value>对交给用户定义的map方法进行处理,生成新的<key,value>对,如下图所示:
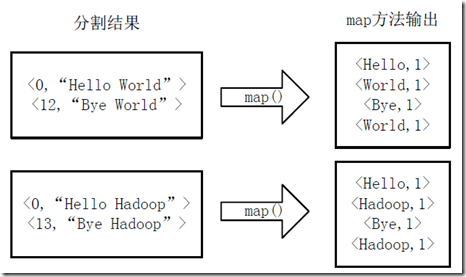
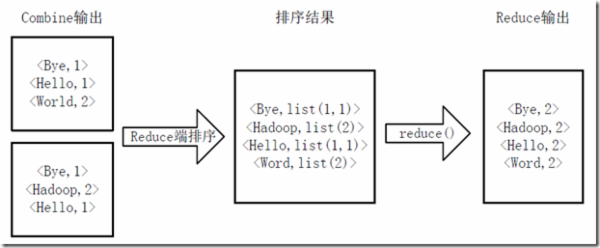
3)得到map方法输出的<key,value>对后,Mapper会将它们按照key值进行排序,并执行Combine过程,将key值相同的value值累加,得到Mapper的最终输出结果。如下图:
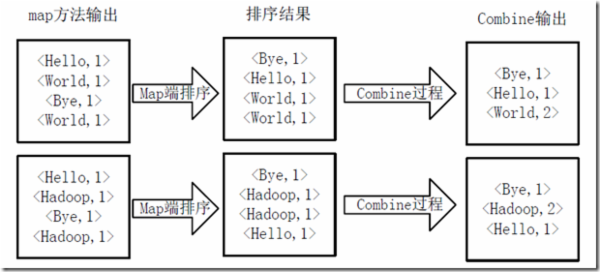
4)Reducer先对从Mapper接收的数据进行排序,再交由用户自定义的reduce方法进行处理,得到新的<key,value>对,并作为WordCount的输出结果,如下图:
个人站点:http://songlee24.github.com
参考:
[1] 实战Hadoop:开启通向云计算的捷径
[2]《了解MapReduce核心Shuffle》