先前在Windows上倒腾了一份Scala的开发环境,然后换到Mac环境上,重新来了一遍,为了防止自己的再度忘记,记录在本博客中。
好,废话不说,开始。
1:Intellij IDEA的安装
习惯用Eclipse了,最近才开始使用Intellij IDEA,感觉功能还是很强大的;这里只讲述具体的安装,我安装的是community版本,2017.3.15的版本,最近更新的社区版本了。
里面有windows版本和eclipse版本,我使用的是mac版本。
2:安装scala插件
这个花费了不少的时间,国内的网速实在太慢,下载地址放在此处,资源无法上传,大家只能自己下载了。
链接:https://pan.baidu.com/s/11jw27AnVwS8RfLebdU6ckw 密码:hb5i
具体操作情况如下:
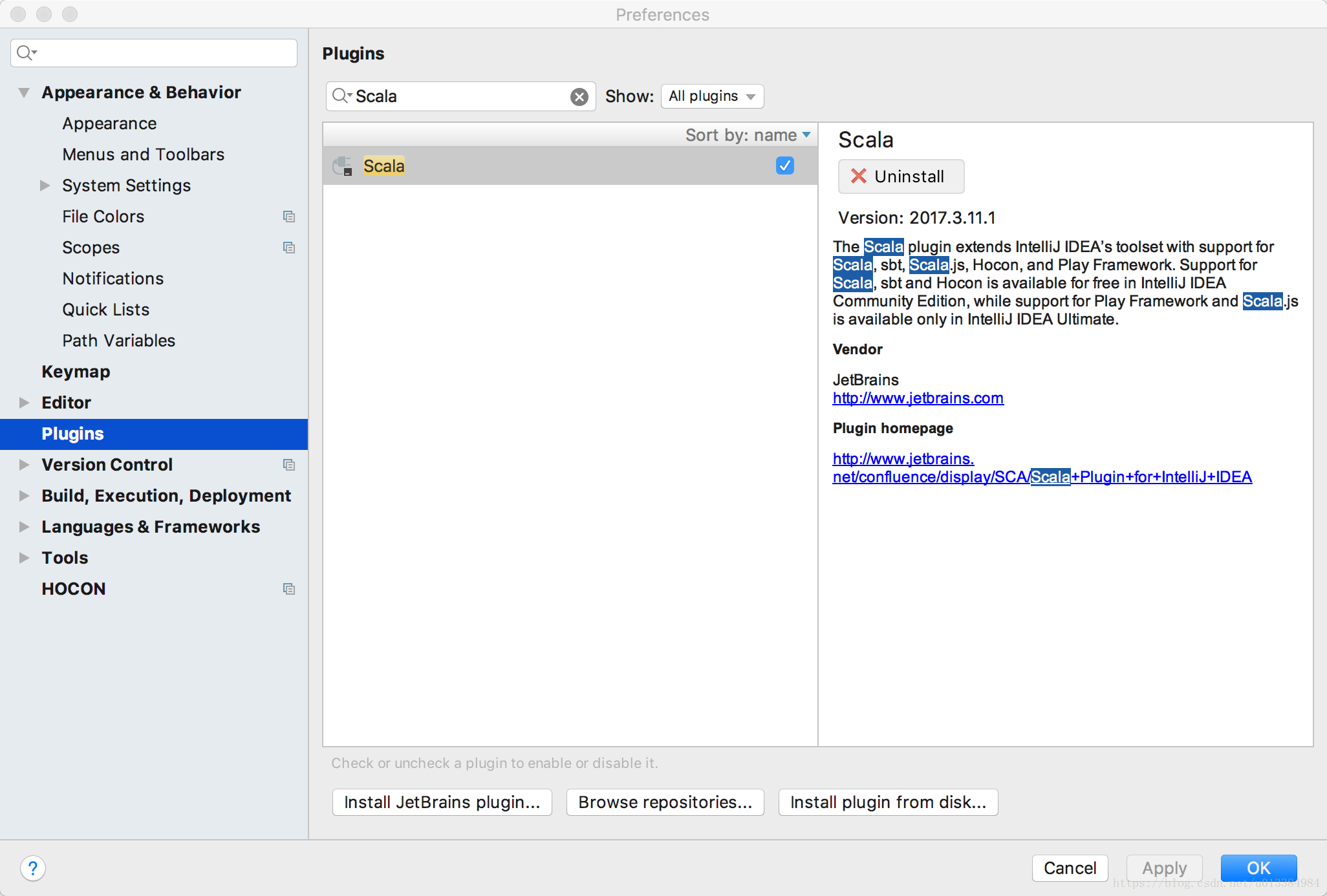
如图所示,打开preference,点击Plugins,接着搜索scala,最新兼容版本是2017.3.11的scala,这个下载非常慢,所以点击从本地安装即可。
注意,这里安装的必须是压缩包,文件夹无法导入的。
安装之后,基本都会让重启的,重启一下即可。
3:开始第一个spark程序
重启之后,新建一个工程,看网上大多说的都是直接新建scala工程,我试了下,很多情况下都会导致运行配置搞不懂,因此自己想了个办法,新建了个Maven工程,如下:
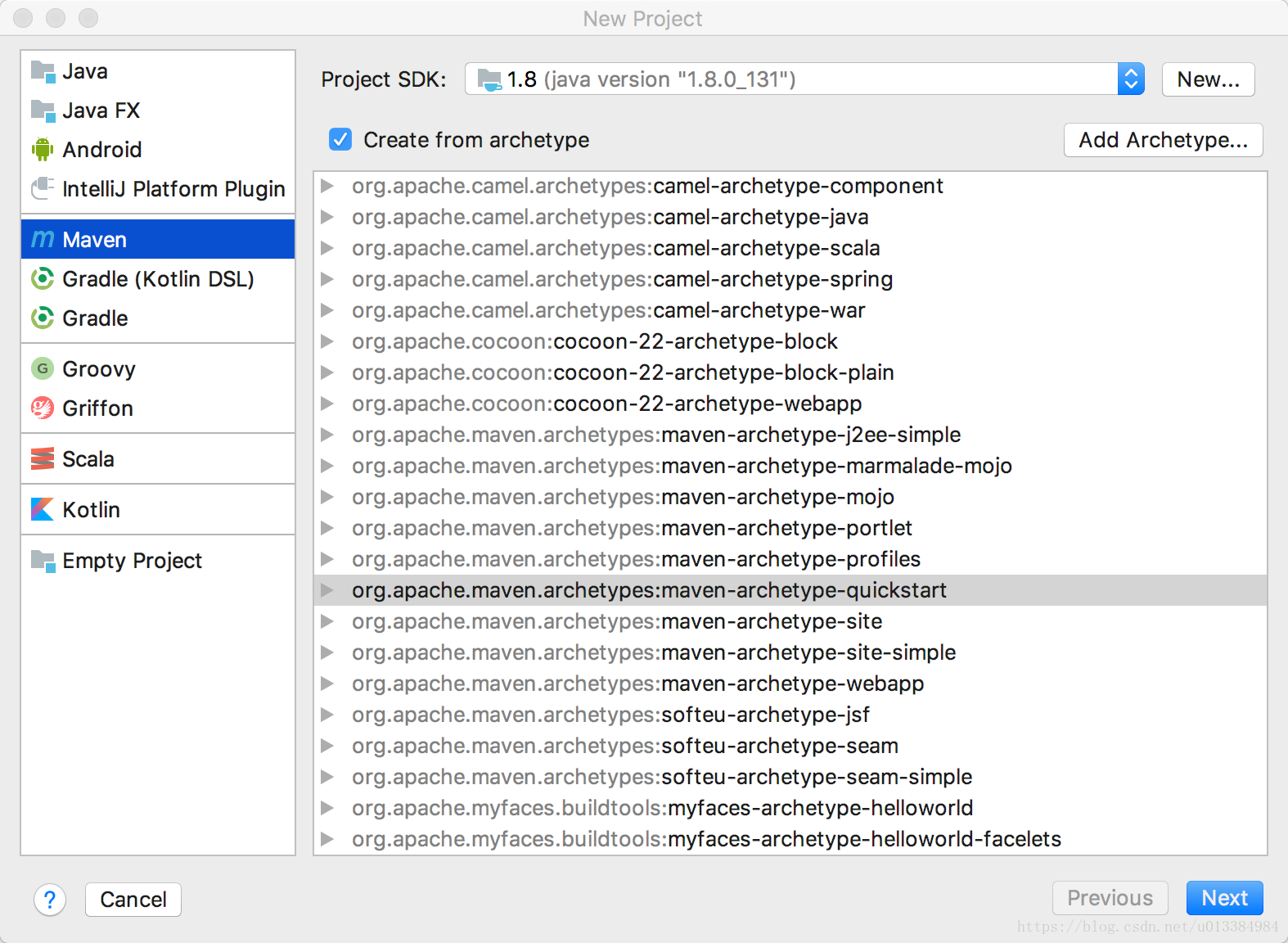
这么新建一个工程之后,我们通过maven就可以很完美地启动一个类了。
点击之后,开始工程的新建:
接着,一路下去,一个maven工程就会创建完毕。
接着,就是我们真正编写一个新的spark工程的代码了。
通常来说,这个逻辑新建的maven工程,都会默认引入junit测试包,不用管它。
4:为我们的maven工程,导入sdk环境
这个环境,可以自己下载,然后让idea自动识别即可,我这边用的是sdk 2.11.0。
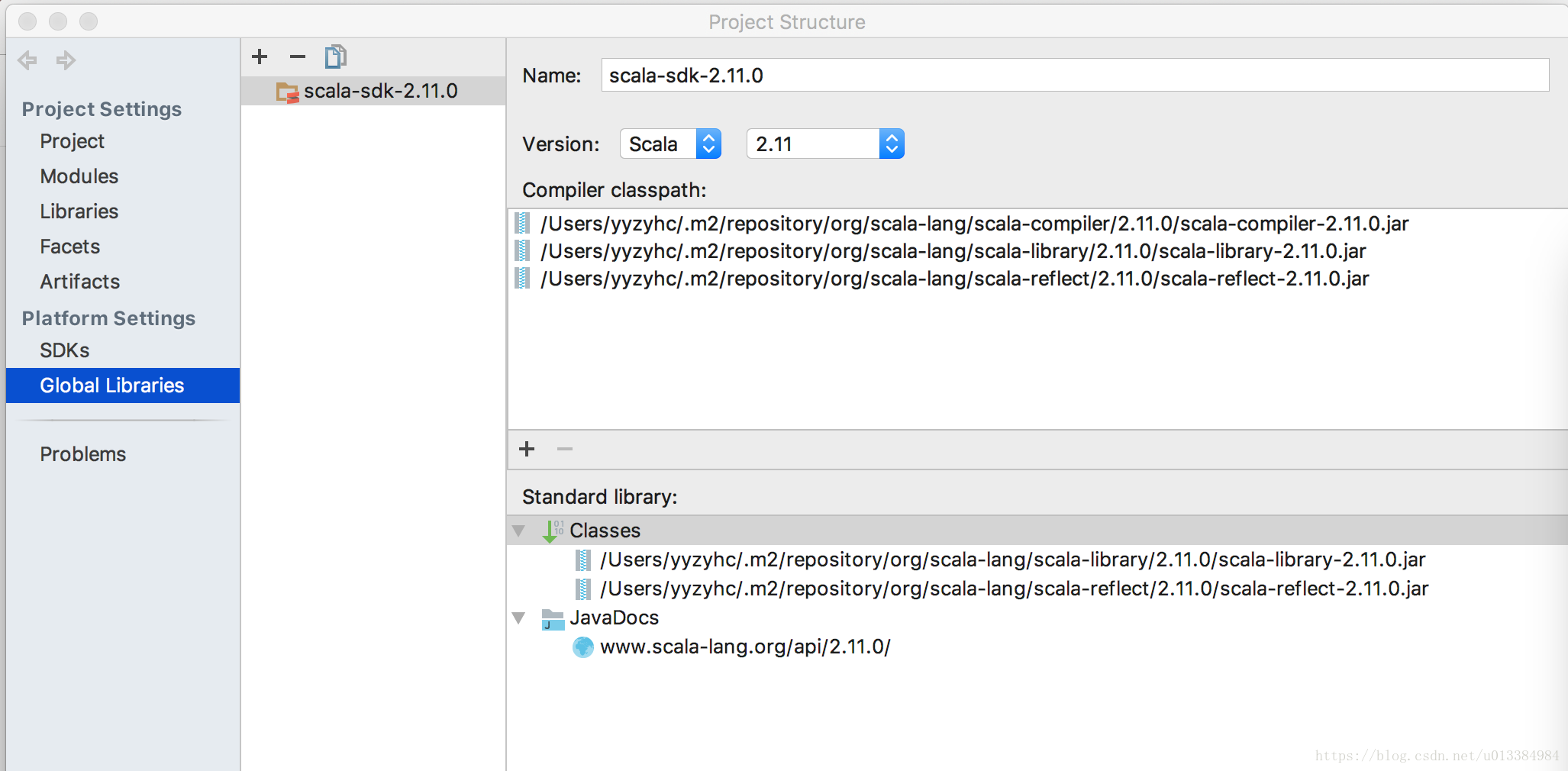
注意,是在Global Libraries内导入的Scala sdk。
5:这个导入完毕之后,基本环境就搭建完毕了,接下来,修改pom文件,增添我们的spark-core。
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.yuzhao.yang</groupId>
<artifactId>secondscala</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>secondscala</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.2.0</version>
</dependency>
</dependencies>
</project>
6:如此配置文件之后,maven导入完毕,开始第一个scala程序。
package com.yuzhao.yang
import org.apache.spark.{SparkContext, SparkConf}
object AnotherTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local[4]")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(List(1,2,3))
print(rdd1.reduce(_+_)
}
}
至此,一个成功的scala环境搭建完毕,可以展开你的spark之旅了。