1.基于内存实现了数据的复用与快速读取
具有较多迭代次数是图计算算法的一个重要特点。在海量数据背景下,如何保证图计算算法的执行效率是所有图计算模型面对的一个难题。基于MapReduce的图计算模型在进行迭代计算过程中,中间数据的操作都是基于磁盘展开的。这使得数据的转换和复制开销非常大,其中包括序列化开销等。除此之外,许多与图结构信息相关的数据无法进行重用,这使得系统不得不反复读取一些相同的数据对图进行重构。相对于传统的图计算模型,GraphX得益于Spark中的RDD和任务调度策略,能够对图数据进行缓存和Pipline操作,实现了图的复用与快速运算。
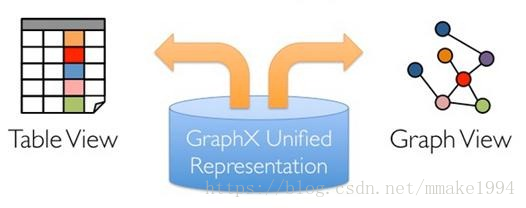
2.统一了图视图和表视图
传统图计算模型都是将表视图和图视图分别进行实现的,这意味着图计算模型要针对不同的视图分别进行维护,而且视图间的转换也比较烦琐。GraphX通过弹性分布式属性图统一了表视图和图视图,即两种视图对应同一物理存储但是各自具有独立的操作,这使得操作更具有灵活性和高效性,如下图,基于GraphX执行图计算任务,一方面用户不必再对不同的组件进行学习、部署、维护和管理,降低运维成本;另一方面更有利于实现基于内存的Pipeline操作。
此外,在GraphX中还提出了一种路由表(routing table)。该表描述了图存储时的一些元数据信息,记录了顶点所在的物理位置以及顶点间的关系。利用该路由表能够极大地提高图计算的执行效率。
3.能与Spark框架上的组件无缝集成
仅从图计算性能方面对比,目前性能最好的模型仍然是GraphLab。但是单一组件或单一性能无法决定整个系统的综合处理能力。尤其是在大数据背景下,任何数据处理业务都需要同一平台上的多个组件通过相互协作来完成,例如海量数据的获取、表示、分析、查询、可视化以及数据通信等各环节对应着一系列专用的组件。然而不同组件之间在集成性方面存在着很大差异。由于GraphX是Spark上的一个组件,能与Spark Streaming、Spark SQL和SparkMLlib等进行无缝衔接,例如可以利用SparkSQL进行ETL,然后将处理后的数据传给GraphX进行计算;或者GraphX与MLlib结合对图数据进行深度挖掘,这些都是Spark一栈式解决方案的具体应用,而Garph、GraphLab等则不具备这一特点。因此,在Spark平台上进行图计算,首选GraphX.