GraphX是Spark框架上的图计算组件,通过对Spark中RDD进行继承与扩展,引入了弹性分布式属性图,并针对该图提供了丰富的API。
GraphX基于Spark中RDD、DAG、高容错性等概念和特性,实现了图计算的高效性与健壮性。Graphx是一种基于内存的分布式的图计算库与图计算框架,用户不仅可以直接使用Graphx提供的经典计算算法库,还可以针对不同的业务需求开发相应的Graphx应用程序。
面向大数据的图计算模型都是对图数据进行分布式存储、并行计算和数据传输。通过图中顶点的数据以及与之相关联的边上的数据,产生消息并发送给相邻顶点。消息通过网络或其他方式传输,顶点在收到消息或状态后进行更新,产生新的图数据,处理流程如下
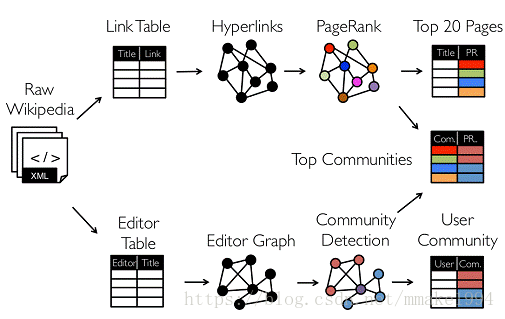
上层分支描述了图计算模型的一种处理流程:首先读取Wikipedia原始数据;然后转换成Link Table形式表视图;通过分析表中蕴含的关系将其转换为HyperLinks图视图;在此基础上应用PageRank算法对图中顶点的重要性进行评估;最后再以表的形式对计算结果进行表示与存储。中下层分支与上层分支类似,不同的是在转换出的图视图上应用了三角形计数用以实现社区发现,最后同样将计算结果以表的形式进行表示与存储。
图计算模型的处理流程大致分为以下几步:
第一步,读取原始数据。数据既可以来自于HDFS、Hive、Hbase、关系型数据库,也可以来自与Spark上的其他组件,例如Spark Streaming、Spark SQL。
第二步,将原始数据转换成表视图。
第三歩,将表视图转换成图视图。
第四步,在图视图上执行图计算算法。
第五步,将得到的结果再转换成表视图,便于表示与用户查询。
整个流程涉及了原始数据、图视图与表视图,以及两种视图的转换。