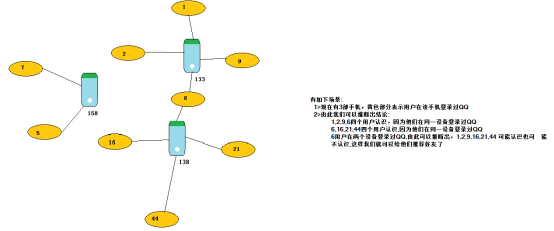
一、使用graph做好友推荐

import org.apache.spark.graphx.{Edge, Graph, VertexId}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
//求共同好友
object CommendFriend {
def main(args: Array[String]): Unit = {
//创建入口
val conf: SparkConf = new SparkConf().setAppName("CommendFriend").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
//点的集合
//点
val uv: RDD[(VertexId,(String,Int))] = sc.parallelize(Seq(
(133, ("毕东旭", 58)),
(1, ("贺咪咪", 18)),
(2, ("范闯", 19)),
(9, ("贾璐燕", 24)),
(6, ("马彪", 23)),
(138, ("刘国建", 40)),
(16, ("李亚茹", 18)),
(21, ("任伟", 25)),
(44, ("张冲霄", 22)),
(158, ("郭佳瑞", 22)),
(5, ("申志宇", 22)),
(7, ("卫国强", 22))
))
//边的集合
//边Edge
val ue: RDD[Edge[Int]] = sc.parallelize(Seq(
Edge(1, 133,0),
Edge(2, 133,0),
Edge(9, 133,0),
Edge(6, 133,0),
Edge(6, 138,0),
Edge(16, 138,0),
Edge(44, 138,0),
Edge(21, 138,0),
Edge(5, 158,0),
Edge(7, 158,0)
))
//构建图(连通图)
val graph: Graph[(String, Int), Int] = Graph(uv,ue)
//调用连通图算法
graph
.connectedComponents()
.vertices
.join(uv)
.map{
case (uid,(minid,(name,age)))=>(minid,(uid,name,age))
}.groupByKey()
.foreach(println(_))
//关闭
}
}
二、用户标签数据合并Demo
测试数据
| 陌上花开 旧事酒浓 多情汉子 APP爱奇艺:10 BS龙德广场:8 多情汉子 满心闯 K韩剧:20 满心闯 喜欢不是爱 不是唯一 APP爱奇艺:10 装逼卖萌无所不能 K欧莱雅面膜:5 |
计算结果数据
| (-397860375,(List(喜欢不是爱, 不是唯一, 多情汉子, 多情汉子, 满心闯, 满心闯, 旧事酒浓, 陌上花开),List((APP爱奇艺,20), (K韩剧,20), (BS龙德广场,8)))) (553023549,(List(装逼卖萌无所不能),List((K欧莱雅面膜,5)))) |
import org.apache.spark.graphx.{Edge, Graph, VertexId}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object UserRelationDemo {
def main(args: Array[String]): Unit = {
//创建入口
val conf: SparkConf = new SparkConf().setAppName("CommendFriend").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
//读取数据
val rdd: RDD[String] = sc.textFile("F:\\dmp\\graph")
//点的集合
val uv: RDD[(VertexId, (String, List[(String, Int)]))] = rdd.flatMap(line => {
val arr: Array[String] = line.split(" ")
val tags: List[(String, Int)] = arr.filter(_.contains(":")).map(tagstr => {
val arr: Array[String] = tagstr.split(":")
(arr(0), arr(1).toInt)
}).toList
val filterd: Array[String] = arr.filter(!_.contains(":"))
filterd.map(nickname => {
if(nickname.equals(filterd(0))) {
(nickname.hashCode.toLong, (nickname, tags))
}else{
(nickname.hashCode.toLong, (nickname, List.empty))
}
})
})
//边的集合
val ue: RDD[Edge[Int]] = rdd.flatMap(line => {
val arr: Array[String] = line.split(" ")
val filterd: Array[String] = arr.filter(!_.contains(":"))
filterd.map(nickname => Edge(filterd(0).hashCode.toLong, nickname.hashCode.toLong, 0))
})
//构建图
val graph: Graph[(String, List[(String, Int)]), Int] = Graph(uv,ue)
//连通图算法找关系
graph
.connectedComponents()
.vertices
.join(uv)
.map{
case (uid,(minid,(nickname,list))) => (minid,(List(uid),List(nickname),list))
}
.reduceByKey{
case (t1,t2) =>
(
t1._1++t2._1 distinct ,
t1._2++t2._2 distinct,
t1._3++t2._3.groupBy(_._1).mapValues(_.map(_._2).reduce(_+_))
//.groupBy(_._1).mapValues(_.map(_._2).sum)
// list.groupBy(_._1).mapValues(_.map(_._2).foldLeft(0)(_+_))
)
}
.foreach(println(_))
//关闭
sc.stop()
}
}
三、用户标签数据合并
| package cn.bw.mock.tags |
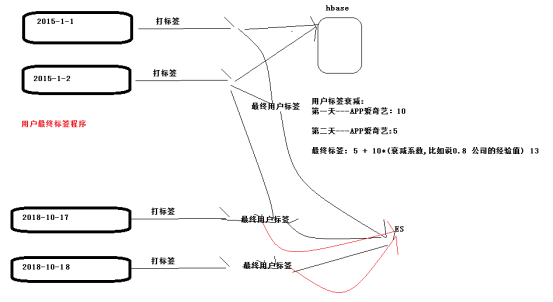
四、用户最终标签和衰减系数