1.算法原理
PageRank算法即网页排名算法,是Google创始人拉里· 佩奇和谢尔盖· 布林与1997年构建早期的搜索系统原型时提出的链接分析算法。自从Google在商业上获得巨大成功后,该算法引起了研究者们的广泛关注,目前很多重要的链接算法都是在PageRank算法基础上衍生出来的。PageRank算法是Google用来标识网页等级的重要依据,是Google衡量一个网站的好坏的唯一标准。对网页进行排名需要量化的依据,因此PageRank算法对每一个网页进行计算后得到一个在0到10范围内的值,即该网页的PageRank值,简称PR值。PR值越高说明网页越受欢迎,越重要。PageRank算法的核心步骤如下:
第1步,初始化
PageRank算法基于两个假设:数量假设和质量假设。首先通过链接关系构建Web图(网络中每个页面对应Web图中的一个顶点,若网页A中包含一条指向B的链接,则Web图中存在一条由顶点A指向顶点B的边);然后为Web图中的每个顶点设置初始的PR值(通常设定每个顶点的初始PR值为1/N,其中N为网络中网页的个数)
第2步,迭代计算
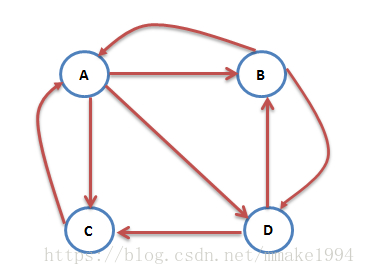
首先假设一个用户在访问某网页时,将其跳转到该网页上各超链接页面的概率相同。如下图,网页A链向网页B、C、D,所以根据假设,用户从A跳转到B、C、D的概率各位1/3。PageRank算法在每一轮迭代计算的过程中,将每个网页当前的PR值平均分配到该网页指向的超链接页面上,这样每个网页便获得了相应的权值;再将这些权值求和,即得到该网页的新PR值。当每个网页的PR值都获得更新后,就完成了一轮迭代。
第3步,结束
随着每一轮的迭代计算,网页中PR值会不断得到更新。当迭代达到一定次数,或者每个网页的PR值固定不变,再或者PR值收敛至某一范围内时,算法停止。算法停止时每个网页的PR值就是该网页最终的PR值。
GraphX提供了静态和动态PageRank的实现方法,这些方法在PageRank对象中。静态的PageRank运行固定次数的迭代,而动态的PageRank一直运行直到收敛为止。
2.案例分析
社交网络中的用户数据spark-1.4.0-bin-hadoop2.4/graphx/users.txt中,用户之间的关系数据在spark-1.4.0-bin-hadoop2.4/graphx/followers.txt中
users.txt内容如下:
1,BarackObama,Barack Obama 2,ladygaga,Goddess of Love 3,jeresig,John Resing 4,justinbieber,Justin Bieber 6,matei_zaharia,Matei Zaharia 7,odersky,Matin Odersky 8,anonsys
followers.txt内容如下:
2 1 4 1 1 2 6 3 7 3 7 6 6 7 3 7
首先以users.txt中的用户作为定点、followers.txt中的关系作为边集创建图;然后通过图直接调用PageRank算法计算出每个顶点的PR值,即用户的重要性;最后结合用户的属性信息对结果输出展示。
package spark
import org.apache.log4j.{Level,Logger}
import org.apache.spark.graphx.{Graph, GraphLoader}
import org.apache.spark.{SparkConf, SparkContext}
object GraTest {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("PageRankTest").setMaster("local[2]")
val sc = new SparkContext(conf)
//
val graph = GraphLoader.edgeListFile(sc,"/home/mark/spark-1.4.0-bin-hadoop2.4/graphx/followers.txt")
/**/
val ranks = graph.pageRank(0.001).vertices
//
val users = sc.textFile("/home/mark/spark-1.4.0-bin-hadoop2.4/graphx/users.txt").
map {
line =>
val fields = line.split(",")
(fields(0).toLong, fields(1))
}
//
val ranksByUsername = users.join(ranks).map {
case(id , (username,rank)) => (username,rank)
}
//
println(ranksByUsername.collect().mkString("\n"))
}
}