例1. 若线性表中最常用的操作是在最后一个元素之后插入一个元素和删除第一个元素,则采用()存储方式最节省运算时间。
A. 单链表
B. 仅有头指针的单循环链表
C. 双链表
D. 仅有尾指针单循环链表
分析:尾指针可以将 “最后一个元素之后插入一个元素” 这个操作的时间复杂度降为O(1);单循环链表使得我们能通过尾指针的后继找到链表的第一个元素,所以 “删除第一个元素” 这个操作的时间复杂度也是O(1)。答案选D。
例2. 已知A=(a1,a2,…,am),B=(b1,b2,…,bn)均为顺序表,试编写一个比较A,B大小的算法。
分析:
- 算法的目标是分析两个表的大小,则算法中不应当破坏原表
- 按题意,表的大小指的是词典顺序,则不应当先比较两个表的长度
- 算法中的基本操作为:同步比较两个表中相应的数据元素。
int compare(Sqlist La,Sqlist Lb){
int i=0;
while(i<La.length&&i<Lb.length){
if(La.elem[i]==Lb.elem[i]) i++;
else if(La.elem[i]<Lb.elem[i])
return -1;
else return 1;
}
if(i>La.length&&i>Lb.length) return 0;
else if(i>Lb.length) return 1;
else return -1;
}
例3. 删除有序表中所有其值大于mink 且小于 maxk 的数据元素。
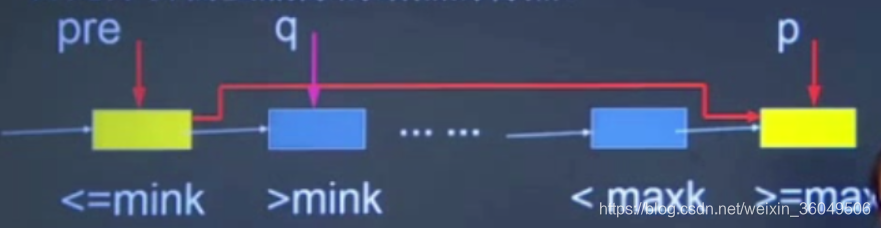
分析:由于是有序表,
- 先找到元素pre,pre<=mink,pre的后继q>mink;
- 再找到元素p,p>=maxk,p的前驱<maxk;
- 修改指针pre->next=q;
- 释放结点:
while(q!=p){
s=q->next;free(q);q=s;
}
完整代码:
void delete(LinkList& L,int mink,int maxk)
{
while(p&&p->data<=mink){
pre->p;p=p->next;
}
if(p){
while(p&&p->data<maxk) p=p->next;
q=pre->next;pre->next=p;
while(q!=p){s=q->next;free(q);q=s;}
}
}
例4. 考察线性表的逆置:
- 顺序表
以顺序表中心为轴进行旋转,移动n/2次。 - 链表
利用头插法从原链表构造逆序链表。
step1. 标志后继节点
step2. 修改指针(将*p插入在头结点之后)
step3. 重置结点*p(p重新指向原表中后继)
void inverse(LinkList& L){
//逆置带头结点的单链表L
p=L->next;L->next=NULL;
while(p){
succ=p->next;//step1
p->next=L->next;L->next=p;//step2
p=succ;//step3
}
}
整个操作并没有移动元素,只是修改了指针。
例5. 考察归并操作,头插法
将两个非递减有序的有序表归并为非递增的有序链表(利用原表结点)。
思路:归并+头插法
step1. 建立空表Lc
step2. 依次从La或Lb中”摘取“元素值较小的结点插入到Lc表中第一个结点之前直至其中一个表变空为止
step3. 继续将La或Lb其中一个表的剩余结点插入到Lc表的表头结点之后
step4. 释放La表和Lb表的表头结点
void union(LinkList& Lc,LinkList& La,LinkList& Lb){
Lc = new LNode; Lc->next=NULL;
pa=La->next;pb=Lb->next;//初始化
while(pa||pb){//归并
if(!pa) {q=pb;pb=pb->next;}
else if(!pb) {q=pa;pa=pa->next;}
else if(pa->data<=pb->data)
{q=pa;pa=pa->next;}
else{q=pb;pb=pb->next;}
q->next=Lc->next;Lc->next=q;//插入
}
delete La;delete Lb;//释放
}
例6. 已知A,B和C为三个有序链表,编写算法从A表删除B表和C表中共有的数据元素。
分析:
被删元素的特点
其它元素则为:
,这3个条件已经涵盖了所有不等的可能。
void Difference_L(LinkList& La,LinkList& Lb,LinkList& Lc){
pre=pa;pa=La->next;
pb=Lb->next;pc=Lc->next;
while(pa&&pb&&pc){
if(pa->data<pb->data){
pre=pa;pa=pa->next;
}
else if(pb->data<pc->data)
pb=pb->next;
else if(pc->data<pa->data)
pc=pc->next;
else{
pre->next=pa->next;delete pa;
pa=pre->next;
}
}
}
例7. 考察双向循环链表:
在双向循环链表的结点中,增加一个访问频度的数据域freq,编写算法实现LOCATE(L,x)。
注意算法的两个要点:
- 算法的基本操作应该是在链表中进行搜索,直至(p==L||p->data==x)为止。
- 在访问频度freq增1之后,需要将该结点调整到适当位置。向前搜索直至找到一个访问频度大于它的结点为止。
p=L->next;
while(p!=L&&p->data!=x)
p=p->next;//搜索元素值为x的结点*p
if(p==L) return NULL; //找了一圈没找到
q=p->prior;//要查找的结点的前驱
while(q!=L&&q->freq<p->freq) //搜索访问频度不小于它的结点*q
q=q->prior;
将结点*p从当前位置上删除;(双向链表,麻烦一些,头脑要清楚)
之后将结点*p插入在结点*q之后;
return p;
例8. 考察链表拆解:
已知L为没有头结点的单链表中第一个结点的指针,每个结点数据域存放一个字符,该字符可能是英文字母字符或数字字符或其它字符,编写算法构造3个以带头结点的单循环链表表示的线性表,使每个表中只含同一类字符。(要求用最少的时间和最少的空间)
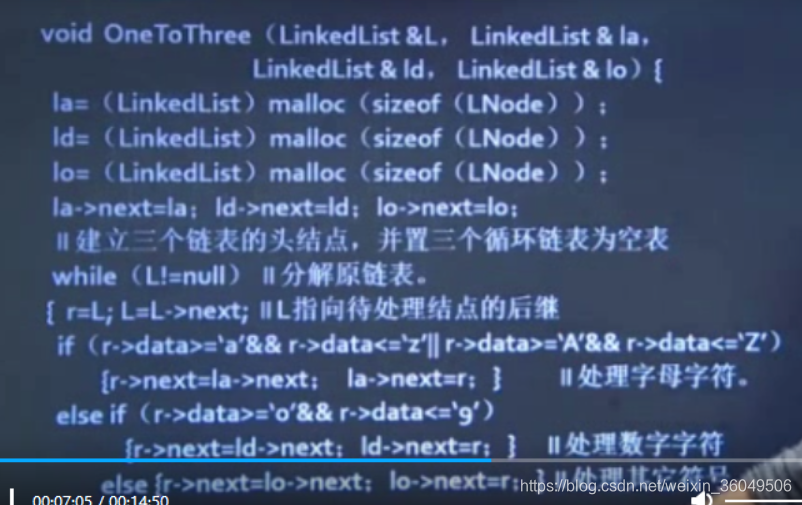
拆分的本质就是把满足不同条件语句的结点从原链表剥离,插入到不同的链表上,只需要修改指针,进行逻辑上的改变,不需要开辟新的物理空间。
总结:大多数的链表题(归并,合并,分解等)不需要另外开辟新的物理空间,只要修改那些满足条件语句的结点的指针,把它们从原来的链表上剥离,在插入到新建立的链表上即可。
例9.划分操作:

借助一趟快排的思想:
void Listchange(int A[],int n){
int i=0,j=n-1;
while(i<j){
while(A[i]%2==0) i++;
while(A[j]%2==1) j--;
if((A[i]%2==1)&&(A[j]%2==0)){
int tmp = A[i];
A[i]=A[j];
A[j]=tmp;
i++;
j--;
}
}
}

例10.
文件分配表FAT是管理磁盘空间的一种数据结构,用在以链接方式存储文件的系统中记录磁盘分配和跟踪空白磁盘块。整个磁盘仅设一张FAT表,其结构如下图所示。如果文件块号为2,查找FAT序号为2的内容得知物理块2的后继物理块是5;再查FAT序号为5的内容得知物理块5的后继物理块是7;接着继续查FAT序号为7的内容为“^”,即该文件结束标志,所以该文件由物理块2、5、7组成。
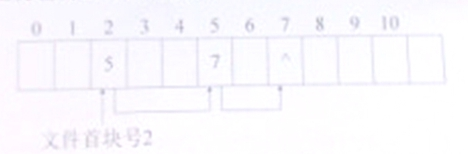
假设磁盘物理块大小为1KB,并且FAT序号以4bits为单位向上扩充空间。请计算下列两块磁盘的FAT最少需要占用多大的存储空间?
1)一块540MB的硬盘
2)一块1.2GB的硬盘
分析:这是假的链表题,实际上是一道计算题。
1)首先根据硬盘大小确定一个FAT序号要选多少位2进制进行表示,占用多少存储。FAT序号以4bits为单位向上扩充空间说明序号只能是4的倍数。物理块大小为1KB,说明540MB有540K个分区,由于 2^19 < 540K < 2^20,所以序号是20个bit,且满足20是4的倍数。每个序号需要20 / 8 = 2.5B的空间存储。
然后计算总的占用存储空间。540MB需要540K * 2.5B = 1350KB即1.35M 。
2)和1)同理。
1.2GB,即1200K个分区,2^20 < 1200K < 2^21,也就是需要21个bit才能存储,但是序号只能是4个倍数,所以需要24个bit,也就是3B的空间。
1.2GB需要1200K * 3B = 3600KB即3.6M。
例11. 适用于压缩存储稀疏矩阵的两种存储结构是 。
A. 三元组表和十字链表
B. 三元组表和邻接矩阵
C. 十字链表和二叉链表
D. 邻接矩阵和十字链表
答案:B
- 三元数组存储(行,列,值)
- 行指针链表(第一列为数组,用指针链接到本行下一个有意义的位置)
- 十字链表的形式可以理解成每一行是一个链表,而每一列又是一个链表https://blog.csdn.net/zhuyi2654715/article/details/6729783
例12. 下列哪些容器可以使用数组,但不能使用链表来实现?
A. 队列
B. 栈
C. 优先级队列
D. Map或者Dict
优先队列一般利用堆来实现,堆用数组来做的话,确实可以快很多,体现在用数组可以很快定位到父子节点,而链表的话,就没有那么方便了,但是这并不意味着链表不能做,可以,只是时间复杂度会比较高而已.
字典一般要求最好能在O(1)的时间就定位到要查询的值,如果采用链表的话,是不可能有这个好的时间复杂度的,字典一般用hash表来实现,在不碰撞的情况下,能够达到这么好的复杂度,用红黑树实现的map,查找的复杂度在log(N)左右. 用链表的话,硬要说的话,可以实现字典,但是效率不够,它在查找,插入等各种操作上都没有优势.
例13. 下列叙述中正确的是( )。
A. 在栈中,栈顶指针的动态变化决定栈中元素的个数
B. 在循环队列中,队尾指针的动态变化决定队列的长度
C. 在循环链表中,头指针和链尾指针的动态变化决定链表的长度
D. 在线性链表中,头指针和链尾指针的动态变化决定链表的长度
答案:A 解析:栈是限制仅在表的一端进行插入和删除的运算的线性表,通常称插入、删除的这一端为栈顶,另一端称为栈底。
例14 用邻接表表示图进行深度优先遍历时,通常是采用()来实现算法的。
A. 栈
B. 队列
C. 树
D. 图
答案:深度用栈,广度遍历用队列
例15 若广义表A满足Head(A) = Tail (A), 则A为
A. ( )
B. ( ( ) )
C. ( ( ), ( ) )
D.((( ),( ),( ))
广义表:
https://blog.csdn.net/kong_xz/article/details/79484843
选B(())
解析:(A)Head(A) ,Tail(A)无定义( B)Head(A)=() ,Tail(A)=()( C)Head(A)=() ,Tail(A)=(()) (D)Head(A)=(),Tail(A)=((),())
例16 在有n个结点的二叉链表中,值为非空的链域的个数为( )。
A. n-1
B. 2n-1
C. n+1
D. 2n+1
分析:二叉树一般有两种存储方式:(1)数组方式(2)链表方式。
使用链表存储的二叉树叫做二叉链表。通常的方法是链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别用来给出该结点左孩子和右孩子所在的链结点的存储地址。其结点结构为:
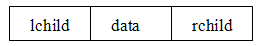
其中,data域存放某结点的数据信息;lchild与rchild分别存放指向左孩子和右孩子的指针,当左孩子或右孩子不存在时,相应指针域值为空(用符号∧或NULL表示)。如下图:
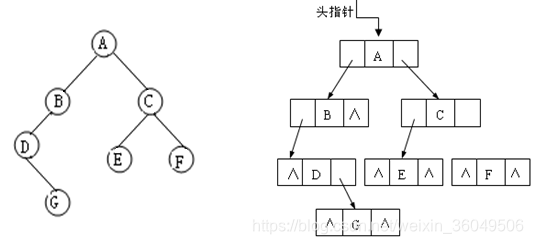
观察上边的结构,7个结点共有6个链域(指针域)不为空,所以猜测答案是n-1,对吗?
n个节点则有2n个链域,除了根节点没有被lchild和rchild指向,其余的节点必然会被指到.所以
空链域有2n-(n-1)=n+1;
非空链域有2n-(n+1)=n-1。
答案选A。
例17 带头结点head的单向循环链表L为空的判断条件是( )
A. head==NULL
B. head->next==NULL
C. head->next==head
D. head!=NULL
答案:C.空的单向循环链表的头结点指向自己
例18 一个长度为100的循环链表,指针A和指针B都指向了链表中的同一个节点,A以步长为1向前移动,B以步长为3向前移动,一共需要同时移动多少步A和B才能再次指向同一个节点____。
答案:A、B移动速度不同,B至少多比A多遍历一遍才能相遇,设移动x次,则
3* x - 1* x= 100 , x = 50