祖玛是一款曾经风靡全球的游戏,其玩法是:在一条轨道上初始排列着若干个彩色珠子,其中任意三个相邻的珠子不会完全同色。此后,你可以发射珠子到轨
道上并加入原有序列中。一旦有三个或更多同色的珠子变成相邻,它们就会立即消失。这类消除现象可能会连锁式发生,其间你将暂时不能发射珠子。

开发商最近准备为玩家写一个游戏过程的回放工具。他们已经在游戏内完成了过程记录的功能,而回放功能的实现则委托你来完成。
游戏过程的记录中,首先是轨道上初始的珠子序列,然后是玩家接下来所做的一系列操作。你的任务是,在各次操作之后及时计算出新的珠子序列。
输入描述:
第一行是一个由大写字母’A’~'Z’组成的字符串,表示轨道上初始的珠子序列,不同的字母表示不同的颜色。
第二行是一个数字n,表示整个回放过程共有n次操作。
接下来的n行依次对应于各次操作。每次操作由一个数字k和一个大写字母Σ描述,以空格分隔。其中,Σ为新珠子的颜色。若插入前共有m颗珠子,则k ∈ [0, m]表示新珠子嵌入之后(尚未发生消除之前)在轨道上的位序。
输出描述:
输出共n行,依次给出各次操作(及可能随即发生的消除现象)之后轨道上的珠子序列。
如果轨道上已没有珠子,则以“-”表示。
样例输入:
ACCBA
5
1 B
0 A
2 B
4 C
0 A
样例输出:
ABCCBA
AABCCBA
AABBCCBA
——
A
全代码:
# include<iostream>
# include<stdio.h>
using namespace std;
const int N = 10;
char str[100];
struct Node
{
char data;
Node *next;
Node *prior;
};
class LinkList
{
public:
LinkList(char a[], int n); //有参构造函数,使用含有n个元素的数组a初始化单链表
~LinkList(); //析构函数
void Insert(int n, char a);//插入
Node * Get(int i); //获取线性表第i个位置上的元素结点地址
void Delete(Node * l,Node* r); //删除两节点间的元素
void PrintList(bool boo);//输出结果
void GoThrough();//遍历整个链表删除重复项
private:
Node * front; //头指针
Node * tail;
};
LinkList::LinkList(char a[], int n)//构造链表
{
front = new Node;
tail = new Node;
tail->next = NULL;
Node *r = front;//初始化头结点
for (int i = 0; i < n; i++)
{
Node *s = new Node;
s->data = a[i];
s->next = tail;// 生成新结点
r->next = s;// 链接在尾结点后面
s->prior = r;
tail->prior = s;
r = s;// 尾指针后移
}
}
LinkList::~LinkList() //析构函数
{
Node *p = NULL; //初始化工作指针p
while (front->next != NULL) //要释放的结点存在
{
p = front->next; //暂存要释放的结点
p->prior = front;
delete front; //释放结点
front = p; //移动工作指针
}
}
void LinkList::Insert(int i, char x)
{
Node * p = front; //初始化工作指针
//若不是在第1个位置插入,得到第i个元素的地址。
if (i != 1) p = Get(i);
if (p != NULL)
{
Node * s = new Node ;//建立新结点
s->data= x;
s->next = p->next;
s->prior=p;
p->next = s; //将新结点插入到p所指结点的后面
s->next->prior = s;
}
else throw "插入位置错误";
}
Node *LinkList::Get(int i)
{
Node *p = front; //初始化工作指针
int j = 1;
if (i != 1)
while (j!=i && p != NULL)
{
p = p->next;
j++;
};
if (p == NULL) throw "位置非法";
return p;
}
void LinkList::PrintList(bool boo)
{
static int count;
Node *p = front->next;
if (p==tail)
{
str[count++] = '-';
}
else
{
while (p->next)
{
str[count++] = p->data;
p = p->next;
}
}
str[count++] = '\n';
if (boo)
{
cout << "Outcome:" << endl;
str[count] = '\0';
cout << str;
count = 0;
}
};
void LinkList::Delete(Node * l, Node *r)
{
Node *s = l;
Node *t =NULL;
Node *R1 = r->next;
//l->prior->next = r->next;
while (s != R1)
{
t = s->next;
s->prior->next = t;
t->prior = s->prior;
delete s;
s = t;
}
}
void LinkList::GoThrough()
{
Node * first = front->next;
Node * second = first->next;
while (first->next!= tail)
{
if (first->data != second->data)
{
if (first->next->next!=second&&first->next!=second)
{
Delete(first, second->prior);
first = front;
second = first->next;
}
else
{
first = first->next;
second = first->next;
}
}
else
{
if(second->next!=NULL)
second = second->next;
}
}
}
int main()
{
int lens;
int turn;
char a[N];
cout << "Start Zuma:";
cin >> a;
lens = strlen(a);
LinkList zuma(a, lens);
cout << "Turns:";
cin >> turn;
for (int i = 0; i < turn; i++)
{
int ts;
char cs;
do
{
cin >> ts >> cs;
} while (cs <'A'&&cs> 'Z');
zuma.Insert(ts + 1, cs);
zuma.GoThrough();
zuma.PrintList(i==turn-1?true:false);
}
}构造函数
LinkList::LinkList(char a[], int n)//构造链表
{
front = new Node;
tail = new Node;
tail->next = NULL;
Node *r = front;//初始化头结点
for (int i = 0; i < n; i++)
{
Node *s = new Node;
s->data = a[i];
s->next = tail;// 生成新结点
r->next = s;// 链接在尾结点后面
s->prior = r;
tail->prior = s;
r = s;// 尾指针后移
}
}浅析:
(1)双链表的构造方式,便于前后查找;
(2)首、尾结点的建立,有首有尾,任何时刻都能将整个链表拎起,便于遍历全链表的循环删除操作;
析构函数
LinkList::~LinkList() //析构函数
{
Node *p = NULL; //初始化工作指针p
while (front->next != NULL) //要释放的结点存在
{
p = front->next; //暂存要释放的结点
p->prior = front;
delete front; //释放结点
front = p; //移动工作指针
}
}浅析:
(1)由于尾结点的存在,所以while判断语句的条件换为“front->next != NULL”,其余操作任与传统双链表相同。
插入
void LinkList::Insert(int i, char x)
{
Node * p = front; //初始化工作指针
//若不是在第1个位置插入,得到第i个元素的地址。
if (i != 1) p = Get(i);
if (p != NULL)
{
Node * s = new Node ;//建立新结点
s->data= x;
s->next = p->next;
s->prior=p;
p->next = s; //将新结点插入到p所指结点的后面
s->next->prior = s;
}
else throw "插入位置错误";
}(没有什么特殊的,常规操作)
获取元素位置
Node *LinkList::Get(int i)
{
Node *p = front; //初始化工作指针
int j = 1;
if (i != 1)
while (j!=i && p != NULL)
{
p = p->next;
j++;
};
if (p == NULL) throw "位置非法";
return p;
}(没有什么特殊的,只要记住用的时候注意一下i,j的初始值设定)
输出
(这是一个挺新颖的函数,我以前没有用过这种方法)
void LinkList::PrintList(bool boo)
{
static int count;
Node *p = front->next;
if (p==tail)
{
str[count++] = '-';
}
else
{
while (p->next)
{
str[count++] = p->data;
p = p->next;
}
}
str[count++] = '\n';
if (boo)
{
cout << "Outcome:" << endl;
str[count] = '\0';
cout << str;
count = 0;
}
};浅析:
(1)接口使用bool类型,便于判断是否循环到了最后一组,使结果可以在一起输入过后一起输出。
(2)用数组记录下来所有字符
(3)用static计数
(4)在相应位置录入’\n’即可满足回车的需求
PS:也可以试试freopen(),存到文件里
遍历
(前方压轴出场的是核心代码!)
void LinkList::GoThrough()
{
Node * first = front->next;
Node * second = first->next;
while (first->next!= tail)
{
if (first->data != second->data)
{
if (first->next->next!=second&&first->next!=second)
{
Delete(first, second->prior);
first = front;
second = first->next;
}
else
{
first = first->next;
second = first->next;
}
}
else
{
if(second->next!=NULL)
second = second->next;
}
}
}
浅析:
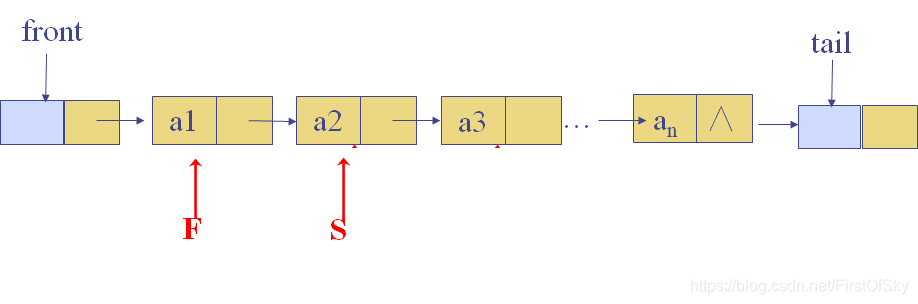
开始循环判断,直到F->next=tail:
1.如果F的值与S的值相等且S->next不为空
则S向右移动
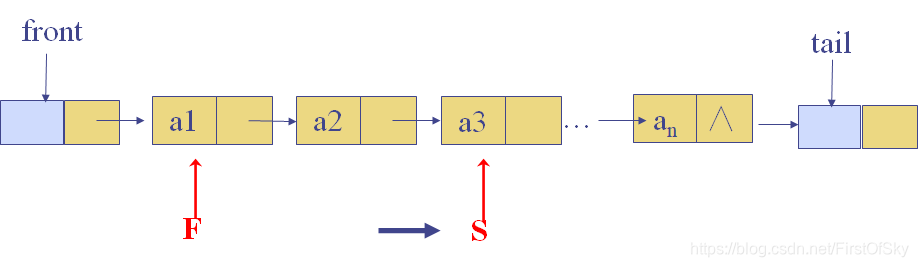
2.如果F的值不等于S的值:
判断是否有三个或三个以上的重复(F的下一个不是S,F的下一个的下一个也不是S,这样就可以确定F与S之间有三个或三个以上重复元素了):
(1)若有,则删除(函数)F和S->prior中的结点,每完成一次操作删除后就将指针复原指回头。
(2)若无,则F移向下一位,S移向F的下一位
删除
void LinkList::Delete(Node * l, Node *r)
{
Node *s = l;
Node *t =NULL;
Node *R1 = r->next;
//l->prior->next = r->next;
while (s != R1)
{
t = s->next;
s->prior->next = t;
t->prior = s->prior;
delete s;
s = t;
}
}浅析:
(1)单独成立一个函数,便于代码重用
(2)用结点作为参数,删除结点(包括结点本身)之间的结点
总算完成了这zuma…感动到哭泣
