为什么要学Mapreduce?
Mapreduce 是Hadoop 学习中最重要的一环,只有学好了mapreduce, 才能游刃有余的解决hdfs中的各种难题。 目前, 笔者刚学完一轮mapreduce, 现在分享一下心得。
一段代码(wordcount)
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount2 {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context ) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
// 配置mapreduce的环境
String namenode_ip = "192.168.17.10";
String hdfs = "hdfs://" + namenode_ip + ":9000";
Configuration conf = new Configuration();
conf.set("fs.defaultFS", hdfs);
conf.set("mapreduce.app-submission.cross-platform", "true");
// 配置mapreduce中各个阶段对应的任务
String jobName = "WordCount2";
Job job = Job.getInstance(conf, jobName);
job.setJarByClass(WordCount2.class);
//job.setJar("export\\WordCount2.jar");
job.setMapperClass(TokenizerMapper.class);
// job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置输入输出的文件路径
String dataDir = "/expr/wordcount/data";
String outputDir = "/expr/wordcount/output";
Path inPath = new Path(hdfs + dataDir);
Path outPath = new Path(hdfs + outputDir);
FileInputFormat.addInputPath(job, inPath);
FileOutputFormat.setOutputPath(job, outPath);
FileSystem fs = FileSystem.get(conf);
if(fs.exists(outPath)) {
fs.delete(outPath, true);
}
// 开始运行
System.out.println("Job: " + jobName + " is running...");
if(job.waitForCompletion(true)) {
System.out.println("success!");
System.exit(0);
} else {
System.out.println("failed!");
System.exit(1);
}
}
}
其中/expr/wordcount/data中文件内容如下:
goodbye world
hello world
goodbye world
hello world
输出到/expr/wordcount/output中的结果文件内容如下:
goodbye 1
hadoop 1
hello 3
world 3
这段代码比较长,接下来分成两段解释一下。
Mapper段:
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { //构建mapper类
private final static IntWritable one = new IntWritable(1); // 定义一个IntWritable对象
private Text word = new Text(); // 定义一个Text对象
public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { // 编写map函数
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
1.由于Mapper的任务是读取/expr/wordcount/data中的文件,并记录每一行数据的各个单词出现的个数并且输出到reducer,所以参数类型就是<Object, Text, Text, IntWritable>, 其中Object记录目前正在处理的输入文件所在行的偏移量, Text(1)记录目前处理行所在行的内容, Text(2)记录要输出到reduce的Key值, IntWritable 记录相应Key值出现的次数。
2.在map 函数中, 先用StringTokenizer 类型的 itr 把目前正在处理的行(即value中的内容)储存起来, 由于StringTokenizer默认是按空格分割, itr中的内容就变成一个个单词,最后再用一个循环把该行的所有单词按key value写到context中去了, 例如goodbye world就变成:
goodbye 1
world 1
Reducer段:
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
1.在reduce函数中, 首先定义sum 用于作为统计次数的计数器,然后开始一个循环,把所有同一组的(即key值相同,至于为什么key值相同的自动变为同一组,就要考虑到mapreduce 的shuffle过程)value 累加起来,最后将key sum 变成对应的Text和IntWritable写到context(可以认为输出到/expr/wordcount/output中)。
至于main中的代码都是一些hdfs环境的配置, 一般可以直接copy,然后根据实际稍加修改即可, 故不做解释
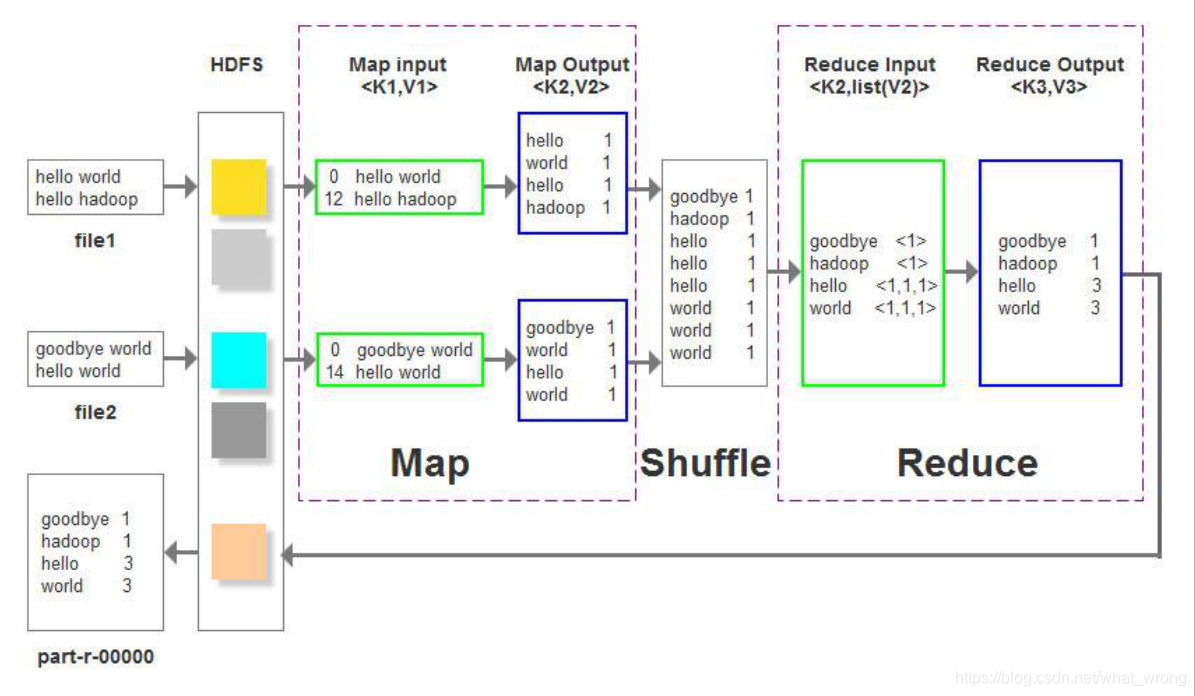
最后附加一份wordcount全过程的图片一张(含shuffle过程)