推荐系统:
离线层:对海量数据离线计算.MapReduce spark
近线层:利用流式处理对海量数据进行实时加工风暴
online layer:负责在线计算处理,相对简单的逻辑运算.WebPy。
一致性哈希算法:为了解决因特网中的热点HostPot问题
最基本的海量数据思想:分而治之思想:
- 。按数据量划分传统的哈希:分布式的mysql
- 按流量划分。一致性hash算法:新浪网流量例子
- 按大计算.MapReduce。
一个地图对应一个分裂分片
MapReduce是一个处理海量数据的分布式计算框架,该框架解决了:
- 数据分布式存储
- 容错性
- 作业调度
- 机器间通信等复杂问题
MapReduce不负责存储数据,数据存储在HDFS上,HDFS的特点:
- 可扩展
- 可靠行
- 并发处理
MapReduce的思想是什么:分而治之的思想,该思想解决了数据可以切割计算的应用问题;
地图:分,把复杂的问题分解为若干个简单任务
减少:合
MapReduce的的计算框架的流程:
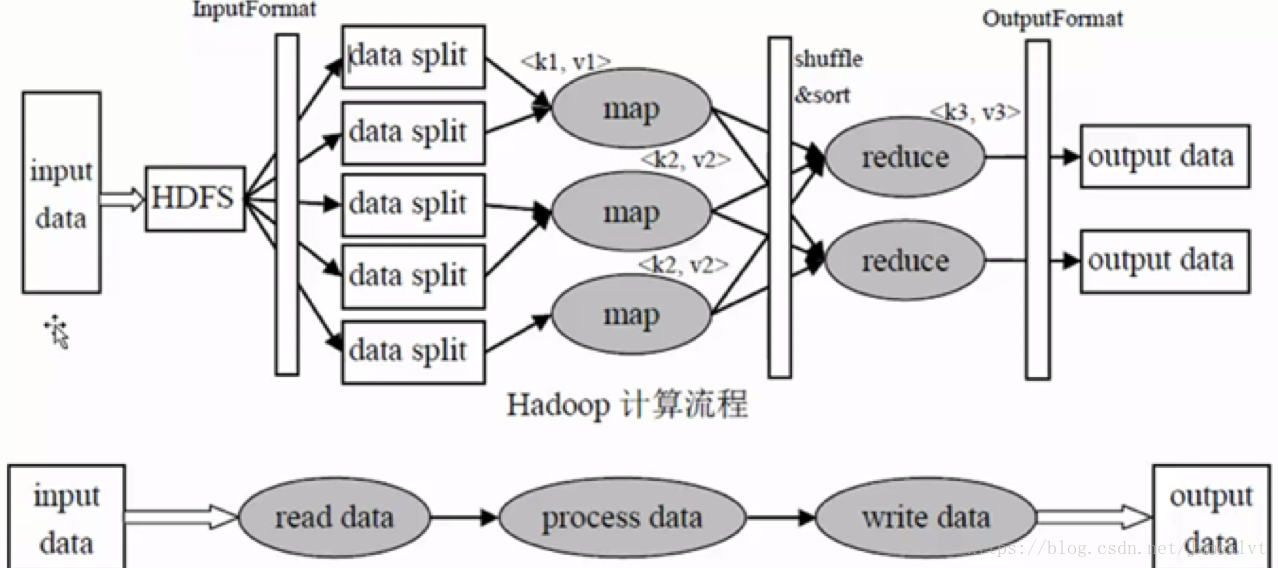
InputFormat(MR最基础的类库之一):
- 计算框架中的split包含后一个Block中的开头的部分的数据(解决记录跨Block的问题)
- recordReader 每读取一条记录,调用一次map函数。
Shuffle :
包含partion,sort,spill,Meger,Combiner 性能优化大有可为的地方
- Partitioner是整个Shuffle中的一个部分,该部分决定数据又哪个Reducer处理,从而分区,比如采取Hash法,有n个reducer ,数据{“are”,1} 对key “are” 去做hash 即 对n取模生成m 那么生成{m, key,value},该partion就是m,决定去哪个桶
- Spill 溢写,每次溢写都会生成文件,溢出的数据到磁盘前对数据进行key排序sort,以及合并combiner。把数据从内存搬到磁盘
- Sort 缓冲区数据按照key排序
- Combiner 数据合并,相同的key数据,vlaue值合并,减少输出传输量。相当于部分reducer功能在memoryBuffer中做了。不能乱用该功能。
MapReduce :
- JobTracker 主进程,负责接收客户作业,提供监控工作节点功能,一个MapReduce集群只有一个JobTracker
- TaskTracker 工作节点,由jobtracker提供任务,并周期性向jobtracker提供工作状态,每个工作节点只有一个taskTracker,但是一个集群有多个taskTracker ,只有一个jobTracker
MapReduce 默认先进先出的队列调度模式(FIFO模式):
- 先看优先级
- 在看开始时间
- 最后看JOBid号
MapReduce采用多进程的并发方式,优点:多进程的并发方式这种模型便于每个任务占用资源进行控制调配,进程空间是独特的,缺点:多进程这种方式很大一部分限制了那些低延迟的任务,适合用于批量操作,高吞吐离线的。
MapReduce物理配置:
- 合适的狭槽(图/减速器个数,默认都是2),设置的时候可以设置成CPU核数-1
- 磁盘情况
MapReduce Map注意⚠️
:
- 地图的个是拆分的份数,而拆分的份数是记录的个数
- 压缩文件是不需要做分割的,不可切分
- 非压缩文件和程序文件可以切分
- dfs.block.size决定块的大小
对于单个的MapReduce
地图的个数最好为集群插槽的倍数
减少的个数最好为集群槽的个数,倍数
MapReduce和HDFS同时部署在一个集群中,因为使数据本地化,就近原则
通常一个集群包含三个角色(主,从客户端)
多副本,目的是容错,数据层面做到高可用