Mapreduce的Shuffle过程
今天来谈一谈, shuffle过程, shuffle中文翻译是洗牌, 是在map 和reduce之间的一套可编写程序,就像可插拔的组件一样,我们可以编写一些程序来替换它们,以达到我们的需求目的。以下是详细的shuffle过程。
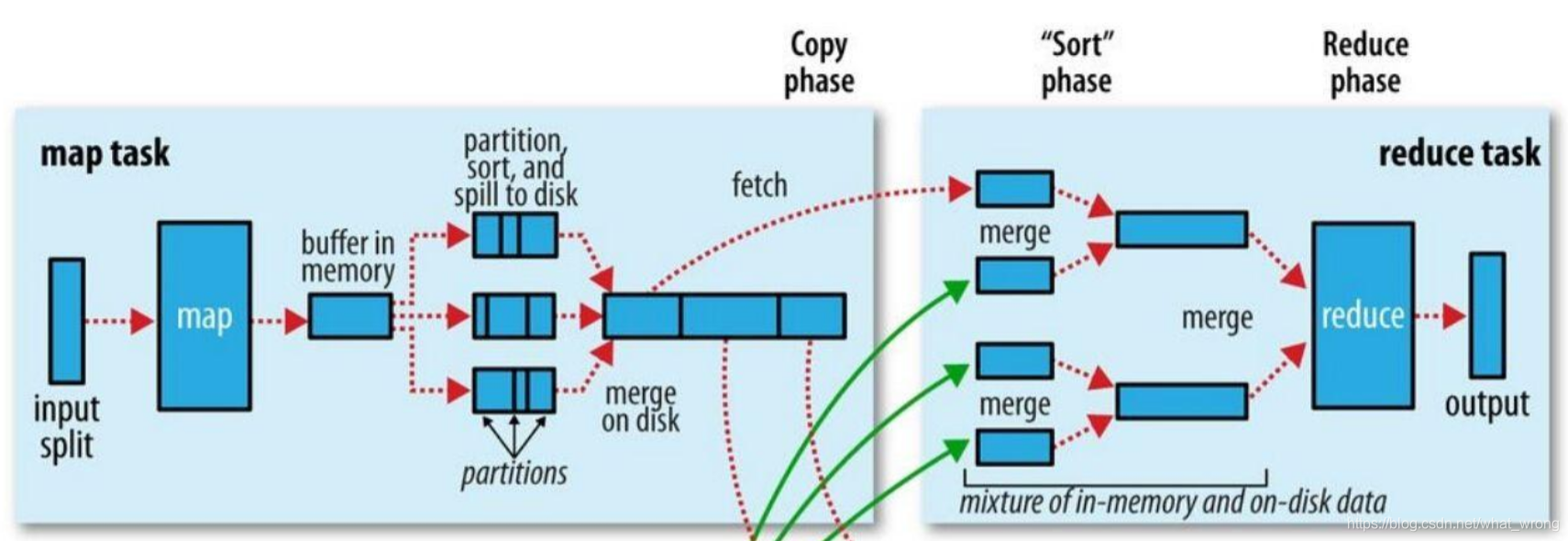
一般需要我们编程的过程有 Combiner, Partition, sort 以及 group。
Combiner:
这个过程实际上是对mapreduce过程的优化, 把一部分reducer要做的工作挪到mapper上去做, 由于一般mapper的数量远远大于reducer的数量,可以提高机器的运行速度。 由于我们学习是不会用到太多mapper,而且并不是所有mapreduce都使用combiner(一般只有求和, 求最值适用, 求平均不适用), 故不做深究。
Partition:
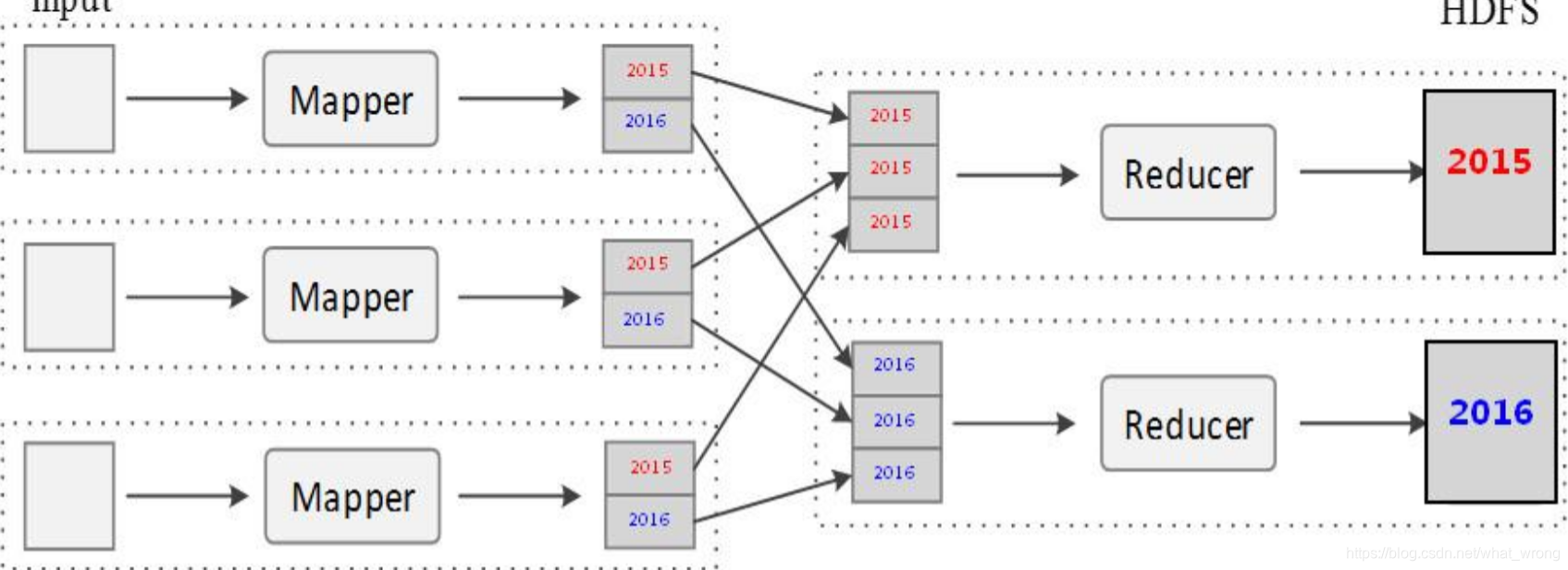
Partition 是实现对文件的分类输出,如下图,实现按年份不同将结果输出到不同文件中。
接下来看段代码:
public static class YearPartitioner extends Partitioner<Text, IntWritable> {
@Override
public int getPartition(Text key, IntWritable value, int numPartitions) {
//根据年份对数据进行分区,返回不同分区号
if (key.toString().startsWith("2015"))
return 0 % numPartitions;
else if (key.toString().startsWith("2016"))
return 1 % numPartitions;
else
return 2 % numPartitions;
}
}
其实我们主要需要重写的类就是这个Partitioner类, 然后实现它的getPartition函数就OK了。注意在getPartition的参数中,key 和value是从map端发送过来的,numPartitions 是我们设置的reducer数量,也就是输出文件数量。 然后在这个函数中按照我们的逻辑编写我们的分类标准, 比如我的分类标准就是判断value中存储的字符是以2015、2016还是其他字符为首,然后返回对于的reducer编号(可以认为返回对应的分区),最后注意要在main函数中完成对应的partition配置,具体如下:
job.setPartitionerClass(YearPartitioner.class); //自定义分区方法
job.setNumReduceTasks(10); //设置reduce任务的数量,该值传递给Partitioner.getPartition()方法的numPartitions参数
sort
想要实现自定义的排序, 我们必须先了解到,shuffle过程中实现了对数据自动按Key值升序排列。因此要想实现按照我们需求的排序,我们必须自定义自己的Key 类型,由于写入到hdfs过程中需要序列化,key必须要用到Writable类型,同时需要按照我们设想的方式排序,必须要用到comparable类型, 综上,我们自定的Key值类型需要是WritableComparable类型,以下是一个例子:
public static class MyKey implements WritableComparable<MyKey> {
private String date;
private int num;
public String getDate() {
return date;
}
public void setDate(String date) {
this.date = date;
}
public int getNum() {
return num;
}
public void setNum(int num) {
this.num = num;
}
public MyKey() {
}
public MyKey(String date, int num) {
this.date = date;
this.num = num;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(date);
out.writeInt(num);
}
@Override
public void readFields(DataInput in) throws IOException {
date = in.readUTF();
num = in.readInt();
}
@Override
public int compareTo(MyKey o) {
if (!date.equals(o.date))
return date.compareTo(o.date);
else
return o.num-num;
}
}
public static class DateSort3Mapper extends Mapper<Object, Text, MyKey, NullWritable> {
public void map(Object key, Text value, Context context )
throws IOException, InterruptedException {
String[] strs = value.toString().split(" ");
MyKey myKey = new MyKey(strs[0], Integer.parseInt(strs[1]));
context.write(myKey, NullWritable.get()); //将自定义的myKey作为Map KEY输出
}
}
第一个MyKey类就是我们自定义的Key类,在这个类中,由于要实现序列化和可比较, 我们必须重写write,readFields和compareTo方法,前两个没什么好说的,在compareTo中,我们的逻辑是先比较date,date不同,就返回date.compareTo(o.date)(按date升序排列), date相同就比较num, 返回o.num-num(按num降序排列)。至于MyKey的使用,就如mapper写到。
Group:
一般我们都采用默认的分组, 也就是按key值分组, 把key值相同的数据组和起来,形成类似:
Summer <1,2,5>
Jerry <2,6>
Rick <1,2,3,4>
Morty <2>
现在我们也可以自定义自己的 Group类(继承自WritableComparator)
public static class MyGroup extends WritableComparator {
public MyGroup() { //注册比较方法
super(Text.class, true);
}
@SuppressWarnings("rawtypes")
@Override
public int compare(WritableComparable a, WritableComparable b) {
String d1 = a.toString();
String d2 = b.toString();
if (d1.startsWith("2015"))
d1 = "2015";
else if (d1.startsWith("2016"))
d1 = "2016";
else
d1 = "2017";
if (d2.startsWith("2015"))
d2 = "2015";
else if (d2.startsWith("2016"))
d2 = "2016";
else
d2 = "2017";
return d1.compareTo(d2); //将原本KEY(年月日)的比较变成年份的比较
}
}
在这个例子中, 我们的分组标准是年份是否相同(key的前4个字符是否相同),相同的归到同一组。同样要注意main函数中要加入group的配置
job.setGroupingComparatorClass(MyGroup.class); //设置自定义分组类