论文地址: Fast R-CNN
0. 摘要
该论文对上一篇R-CNN进行改进,在训练速度,推断速度和精度上都有了很大的提升。
1. 介绍
相比于分类,目标检测的计算代价大幅提升,这是因为目标检测除了分类还需要精准的定位,带来了两个方面的问题,涉及速度,精度和模型精简度的问题:
- 一是需要处理大量的提议框
- 二是这些候选框的得到粗糙定位后需要进一步精细化
该论文中提出了一个一阶段的训练方法来联合训练提议方法和空间位置回归,在当时的方法中缺德了state-of-art效果。
1.1 R-CNN and SPPnet
R-CNN提出使用深度卷积伸进网络对候选区域进行分类,但有一些缺点:
- 多阶段的训练:首先使用对数损失函数微调作用于候选框卷积神经网络,接着训练适用于卷积神经网络的SVM,然后进行边界位置狂的回归。
- 训练的时间和空间成本都很高:需要对每个图片的每个候选框进行特征提取且需要写到磁盘上
- 目标检测推断阶段速度慢:同理,每一张图像的每一个候选框都需要进行特征提取
SPPnets能够加速R-CNN,主要是通过共享一部分的计算,即它对于每一张图像只进行一次特征提取然后从特征图中对每一个候选框提取一个特征向量。
SPPnet也有一些缺点,它的训练也是多阶段的,提取特征,微调网络,训练SVM并且进行位置信息的回归。这一过程特征也需要写到磁盘上,但是他的微调不会更新sppnet的卷积层,这会限制非常深的卷积神经网络的精确度。
1.2 论文贡献
- 更高的目标检测质量mAP
- 单阶段的质量,使用多任务损失
- 训练能够更新所有的网络层
- 获取特征的过程不需要写入磁盘
2. Fast R-CNN架构和训练
下图是Fast R-CNN的模型架构,Fast R-CNN将整幅图片和一系列目标候选区域作为输入。首先网络处理图像产生一个特征图,然后对于每一个物体产生感兴趣区域,接着将所有的特征向量输入到全连接层产生连个分支,分别是类别分数和位置坐标。
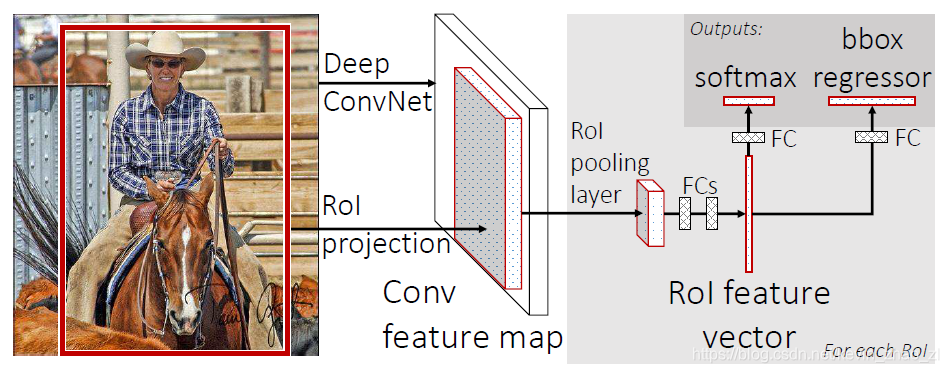
2.1 ROI(感兴趣区域)池化层
ROI池化层使用最大池化将特征图中的感兴趣区域转化为小的固定大小(
)的特征图,其中H和W是网络层的超参数,与任何感兴趣区域都无关。这篇论文中每一个ROI都是一个矩形窗口其具有,具有一个四元组的参数。
RoI最大池化
的RoI窗口划分为
个网格区域,每个小格的尺寸大约是
,然后对每个子窗口的网格进行最大池化。池化操作独立应用于每个特征图通道,池化层仅仅是空间金字塔池化层的一个特例,其只有一个金字塔层级,
2.2 从预训练模型初始化
论文对三种具有五个最大池化层和5到13个卷积层的ImageNet预训练的模型进行实验,使用与训练模型初始化Fast R-CNN后,这些网络会进行一下的修改:
- 最后一个最大池化层使用具有超参数H和W的RoI池化层来代替
- 网络最后的全连接层和softmax被能产生类别分数softmax和边界框的回归器代替
- 修改网络使其能接受两种数据输出即一系列的原始i图像和一系列的感兴趣区域
2.3 微调网络用于检测
Fasr R-CNN一个重要的特性是在后向传播的过程中会训练更新所有的网络层权重,相反,SPPNet不会更新空间金字塔池化层之下的各层权重,根本原因是SPP层在训练样本来自不同图像时训练代价极高,这是由于每一个RoI可能有很大的感受野,而前向传导过程必须处理全部的感受野,训练的输入经常时整个图片,过大。
论文提出的高效方法利用了特征共享。训练过程中,SGD的训练批次是分层取样的,首先是N张图片,接着从每张图片取R/N个RoIs。而且,来自同一张图片的RoIs会共享计算和存储。实际训练的时候这种方法并没有因为来自同一张图象的RoI相关而造成收敛过慢。
除了分层采样,Fast R-CNN还使用了流水线训练方法,即只有一个微调阶段来联合训练softmax分类器和边界框回归器,而不是分别训练softmax分类器,SVMs和回归器。具体的参数如下:
多任务损失:Fast R-CNN网络的输出包括两个,一个是描述每个RoI在K+1类(+背景)上的可能的概率分布,另一个是边界框回归偏差,类别k的边界框回归偏差可以定义为
。
对每一个待训练的RoI的gt类别u和gt边界框v,定义一个多任务损失来联合训练分类器和回归器:
其中
,对于
,u=0即该类为背景,损失具体为:
其中:
是一个
损失,相比于
,对离群点不敏感。当回归目标无界,使用
损失需要进行谨慎地学习率的调整以避免梯度爆炸,
损失则消除了这种敏感性。
损失函数中的超参数
用来对分类损失和定位损失进行权衡,论文中实验取1。
多批次采样:微调期间,SGD每个最小批次都是随机从两张图片(N=2)中构造的,取
,即从每张图片中取64个RoIs。从中选区25%的IoU大于0.5的RoIs组成带前景的样本,u
。其余的选择最大IoU的RoIs作为负样本,
。低于阈值0.1的样本作为启发式的难样本挖掘,训练时,图片以0.5的概率及进行水平切分。
RoI池化层的后向传导:RoI池化层后向传导函数计算每一个输入
的损失函数的偏导:
即对于每一个小批次中的RoI r和每个池化输出单元的
,偏导数
在i是由最大池化确定的对于
的取值,这个偏导在后向传播过程中已经由RoI池化层的顶层的后向传导函数计算。
SGD超参数:分类和回归的全连接层分别被初始化为0均值的高斯分布,标准差分别是0.01和0.001.偏置项被初始化为0.所有层的learning rate初始化为0.001,30k次迭代后,lr降至0.0001,再训练10k次。但训练大数据集时,迭代更多次。momentum初始化为0.9,weight_decay初始化为0.0005。
2.4 尺度不变性
文中探索了两种实现尺度不变性的物体检测的方法:一种通过蛮力学习,另一种是用图像金字塔
3.Fast R-CNN检测
3.1 截断SVD用于加速检测
对于整张图片分类,花在全连接层的时间要远小于卷积层。而对于检测任务,当ROIs的数量较大时,大约一半的时间都用于全连接层的计算。这时,我们可以对全连接层采用SVD(奇异值分解)的方法,减少其参数,从而加速运算速度。
4. 主要成果
- 在VOC07,2010和2012上均得到了state-of-the-art mAP结果
- 相比于RCNN和SPPnet更快的训练和测试过程
- 在VGG16上微调卷积层提高了mAP
5. Discussion
5.1 多任务训练有帮助吗?
单独分类,单独定位,联合:效果确实有提高
5.2 尺度不变性:蛮力法还是特征金字塔?
对比实验表明,蛮力方法(single scale)更好,multi-scale只能带来少量的mAP提升,却造成了大量计算时间的增加。这也同时验证了SPPnet中的结果:深度卷积网络善于直接学习尺度不变性。但这种不变性的来源却令人困惑。
5.3 更多的训练数据?!
5.4 SVMs是否比softmax更优秀?
不一定
5.5 更多的候选区域?
实验结果说明并非如此。这一点不通过实验恐怕很难解释,但似乎稀疏的候选区域结果会更好。