针对jieba分词作业做一个总结,方便以后查看。
中文分词
分词,即切词,在NLP文本预处理中经常使用一些方法来对文本进行分词,从而使文本从“字序列”升级到“词序列”。
为什么要进行分词?在中文中,一个个汉字有其自身的含义,但是组成词语时,其含义可能会发生很大的变化,使得之后进行文本处理任务时不能很好的理解句子的含义。(比如“和”,“平”,“和平”,三者的含义有很大的不同。)另外,从字序列升级成词序列,可以使模型能够得到更高级的特征。
分词算法有很多,比如正向最大匹配算法,逆向最大匹配算法,双向最大匹配算法,基于统计的分词方法,隐马尔可夫模型分词法,神经网络分词法等等。
jieba分词
jieba是一种常用的分词工具,在[GITHUB站](https://github.com/fxsjy/jieba)有详细的介绍。
分词过程
jieba分词有其自己的字典,也可以导入自定的字典。分词是根据字典来进行分词。(字典不准确时,会影响分词结果的好坏。)
分词时可以去除一些停用词(对句子含义不影响的符号,助词等)。
最简单的情况
说是最简单的情况,是因为,分词时没有去除停用词,只是简单地读取路径下文件并进行分词。也没有对分词后的结果进行保存文件。
import jieba
import os
import math
from collections import Counter
word_list=[]
path_tem="C:/Users/DR.KAT/Documents/NLP/1946年05月"
for file in os.listdir(path_tem):
file_tem = os.path.join(path_tem,file)
text=open(file_tem,encoding='utf-8').read()
seg_list=jieba.cut(text)
word_list+=seg_list
word_count = Counter(word_list)
result=0
word_num=len(word_list)
print("总词量",word_num)
for word in word_count:
percent = word_count[word]/word_num
result+=percent*math.log(percent,2)
result=-result
print("信息熵",result)
print(word_count,'\n')
去停用词
import os
import jieba
import math
import re
from collections import Counter
word_list=[]
def read_file(read_folder_path,stopwordspath):
global word_list
word_num=0
stopwords = {}.fromkeys([ line.rstrip() for line in open(stopwordspath,"r",encoding='utf-8')]) # 停用词表
folder_list = os.listdir(read_folder_path)
for file in folder_list:
dealpath = os.path.join(read_folder_path, file) #处理单个文件的路径
with open(dealpath,"r",encoding='utf-8') as f:
txtlist=f.read()
words=jieba.cut(txtlist,cut_all=False)
cutresult=""#定义分词并去停用词结果
for word in words:
if word not in stopwords:
if word != '\t':
cutresult += word#去停用词
cutresult += " "
word_list+=cutresult
word_num=len(word_list)
word_count = Counter(word_list)
return word_count
def put_entropy(word_count):
entropy = 0
for word in word_count:
word_count[word] /= len(word_list)
percent = word_count[word]
entropy += percent * math.log(percent, 2)
entropy=-entropy
return entropy
if __name__ == '__main__' :
stopwordspath='C:/Users/DR.KAT/Documents/NLP/NLPIR_stopwords.txt'
rfolder_path='C:/Users/DR.KAT/Documents/NLP/1946年05月'
a= read_file(rfolder_path,stopwordspath)
b= put_entropy(a)
print("总词量",word_num)
print("信息熵",b)
遇到的问题
出了许多错误,有的不知道是什么情况。。。
1.首先,文件路径输入有格式要求。使用os库进行文件读取时,“\”要写成"/"或者在路径前加r(表示按原字符含义)。
2.变量定义问题,在函数前定义变量,可以在函数内声明一下这是global变量,防止之后调用时出现问题。
3.python中有从属关系的格式要求(空格),要正确明确代码之间从属关系(敲好空格)
4.至今还不明白的 目录名无效的问题。。。
用到的库
os库,一个处理文件的库,在OS库操作有详细的说明。
信息熵
计算公式:
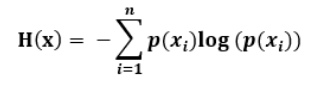
信息熵的介绍