一.写数据
DataXceiver的writeBlock方法用于客户端(Client或DataNode)的写数据请求。
二.单一流程
- 读取客户端发送过来的消息(下文称之为“请求参数”)
- blockId:要写入块的block id。
- generationStamp:要写入块的block generationStamp。
- pipelineSize:num of datanodes in entire pipeline.整个管道里的datanode数,默认为3。
- isRecovery:是不是恢复操作。
- clientName:如果是DataNode到DataNode的请求,clientName为空。
- hasSrcDataNode:is src node info present.标识上一节点是DataNode。
- DatanodeInfo:如果hasSrcDataNode,读取此DatanodeInfo。
- numTargets:目标节点的数量。如果是Client的请求,则目标节点为3;如果是DataNode1的请求,则目标节点为2。
- DatanodeInfo[]:每个目标节点。
- checksum:校验数据。

- 根据上面要写入的block创建BlockReceiver。
- 创建流链,确保DataNode1到DataNode3都是通的。
- mirrorOut:stream to next target
- mirrorIn:reply from next target
- mirrorNode:the name:port String of next target
- mirrorSock:socket to next target
- replyOut:stream to prev target
- in:stream from prev target

- 调用BlockReceiver.receiveBlock(各种流)读取客户端数据写到本地,和读数据协议是一样的,参考http://zy19982004.iteye.com/blog/1881733。

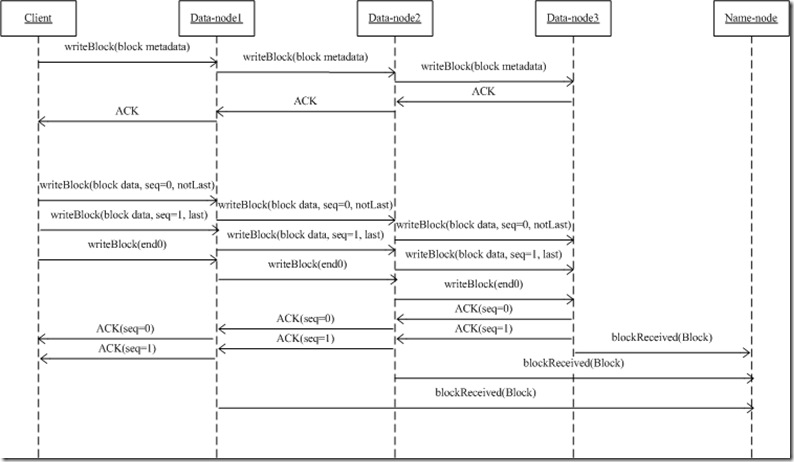
三.整个流程
- 上述二是在某一节点上发生的行为,在整个写过程中,每个节点都会发生这个行为,于是形成了下列一个流程图。
- 当前节点会把writeBlock时接受到的请求参数通过mirrorOut继续发生给下一节点;下一节点收到请求,解析请求(二过程),决定是否发生AC应答...
- 如果整个流通道建立了,DataNode1读取client的数据,写到硬盘上,并同时把此数据流继续发送给DataNode2...边收边传
- 当前节点是怎么知道下一节点的?从客户端发生过来的流里面,读取到了目标节点DatanodeInfo[],mirrorNode = targets[0].getName();