1 算法分类
机器学习算法很多,按照是否有标注,以及要解决的问题特点,按照如下规则分类。
- 有监督学习
- 分类问题
- 决策树:
- 支持向量机
- 朴素贝叶斯:条件概率
- 集成学习(多个分类算法的结合)
- Boosting:弱学习提升为强学习
- Bagging, 随机森林:并行多个分类算法,最终进行集成
- 序列问题
- HMM隐马尔科夫模型
- MEMM最大熵马尔科夫
- CRF条件随机场
- 回归预测
- 线性回归
- 分类问题
- 无监督学习
- 聚类
- 半监督学习,强化学习
- 迁移学习
2 算法介绍
决策树
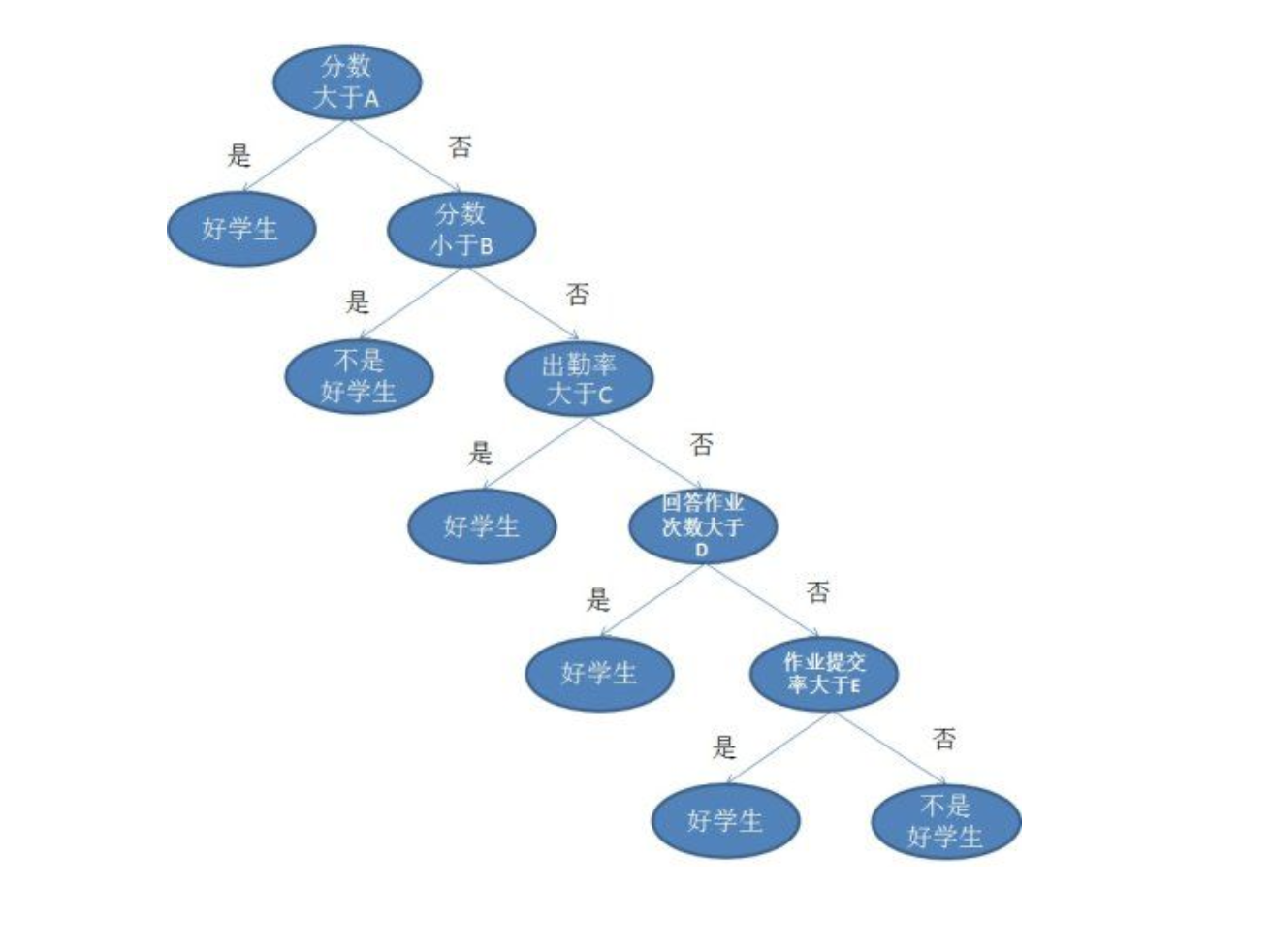
常用在分类问题中,有监督学习。包含一个根节点和一些内部节点,他们表示决策条件。叶子节点则表示决策结果。从根节点到每个叶子节点都形成了一个决策序列。样本集从根节点开始判断,即可得到最终结果。最终结果不符合标注,则产生误差。通过调整内部节点的决策条件,比如下图中的A B C D E的值,可以使得样本误差最小。从而得到最佳决策树。
随机森林
说到决策树,就不得不说随机森林了。决策树是一棵树,而随机森林则是很多决策树组成的森林。树之间完全独立,无关联。随机森林的训练过程如下
- 如果样本集个数为N,则有放回的选择N个样本,作为一颗决策树的训练样本。由于是又放回的,故里面可能有重复,实际样本会小于N,从而防止过拟合。
- 样本属性如果为M(例如上面决策树中的学生,有分数、出勤率、回答作业次数和作业提交率,共计4个属性),则选择m个属性作为决策树的节点,其中m远小于M。然后从根节点开始进行分裂,得到一颗决策树
- 利用又放回抽样得到的N个样本,对包含m个内部节点的决策树,进行训练,调整m个内部节点的决策条件,使得误差最小。这样就得到了一颗决策树。
- 重复1~3步骤,这样可以得到大量的决策树,形成随机森林。
随机森林的预测过程如下
- 将输入放到随机森林的每一颗决策树上,从根节点开始进行决策判断,得到多个分类结果
- 统计分类结果,选择最多的为最终输出。
相比决策树,随机森林充分发挥群众优势,少数服从多数的思想。通过多颗决策树,三个臭皮匠赛过诸葛亮,提高了预测精度。其优点有
- 通过随机抽样和随机属性选取,减少了单颗决策树的过拟合问题。
- 通过随机抽样和随机属性选取,大大提高了泛化能力,抗噪声能力也加强了。
- 森林内的树之间完全独立,容易并行训练和并行预测,提高训练和预测速度。
- 随机森林不仅可以做有监督学习,还可以做无监督聚类,使用范围很广,没有明显缺点。
一般情况下,在不知道该使用哪种机器学习算法的时候,可以使用随机森林。它使用范围很广,没有明显缺点。
K近邻
K近邻也是应用于分类领域,同样是一种少数服从多数的思想,其步骤如下
- 对输入数据,在样本集中找到K个离他最近的数据
- 根据这些数据的标注,选择类别最多的为最终输出。
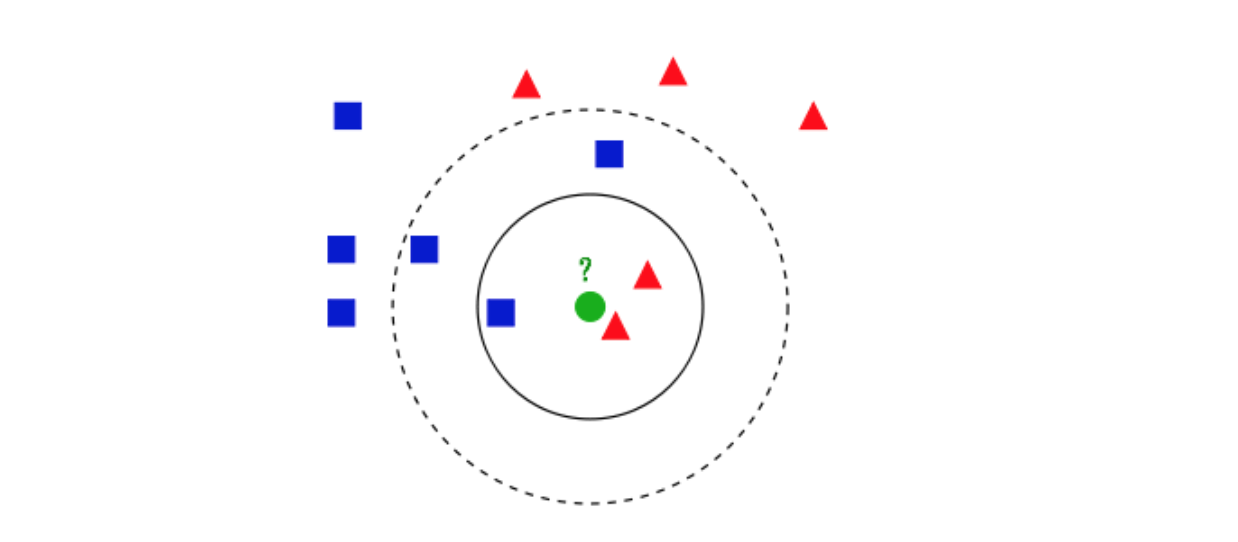
如上图,蓝色方框和红色三角是样本数据,他们属于两种不同的分类。绿色圆圈为输入,需要预测它属于哪个分类。如果K=3,则我们找到绿色圆圈最近的三个样本数据,即两个红色和一个蓝色。由于红色数目多于蓝色,故判定最终结果为红色。
K近邻算法很简单,要注意的有
- 最近邻可以使用距离还进行计算,距离的算法有绝对值距离,欧式距离等多种,一般使用欧式距离,即平方根距离。
- 样本数据的每个属性特征,必须做归一化,使得他们同等重要。
- K选择过小容易有噪声,选择过大容易过拟合。K的选择要通过不断调整。
支持向量机SVM
支持向量机support vector machine,同样是有监督分类的一种算法。可以简单理解为,训练阶段,它通过一根直线或曲线,将两个分类完全隔离开。预测阶段,判断数据属于曲线的那一边,则为哪个分类。
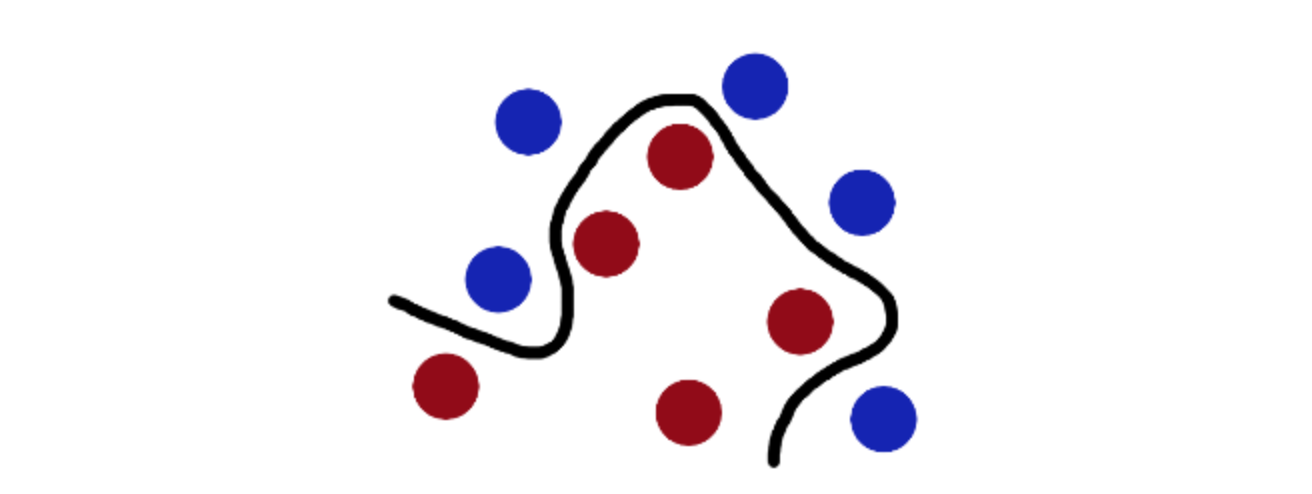
曲线两边的空白margin越多,则训练得到的这条线的误差越小,泛化能力越强。故SVM准确度取决于离他最近的点。如下
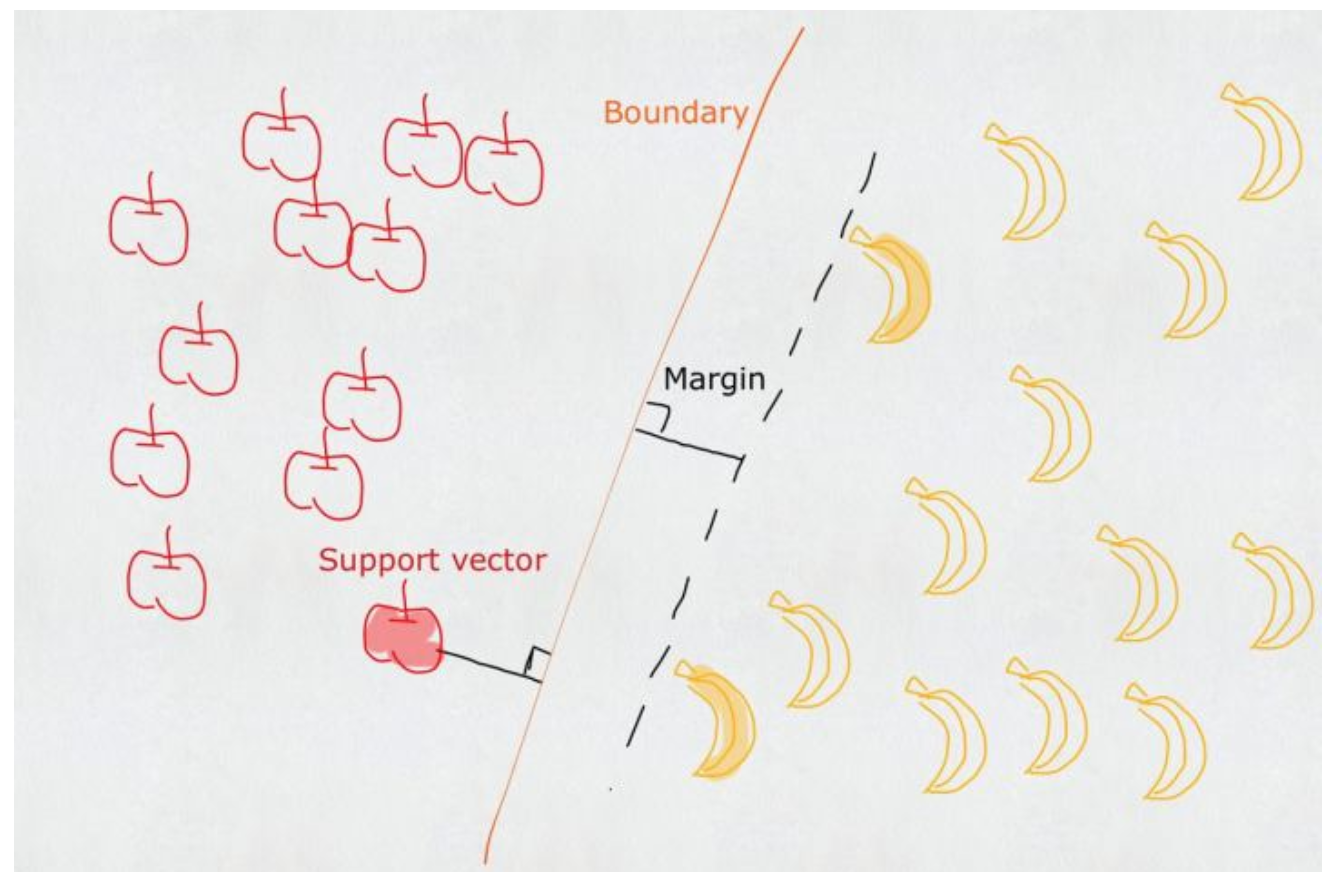
找到这些最近的点,即可得到最终的分隔线。
深度学习
深度学习神经网络是当前的热点,大大降低了机器学习的先验知识门槛,泛化能力很强。它需要大量的数据,进行大规模计算,从而得到最终的模型。这儿就不单独展开了。
隐马尔科夫模型HMM
适用于序列问题中,故在自然语言处理中应用十分广泛。jieba分词和词性标注,都使用了隐马尔科夫模型。任何一个HMM都可以由一个五元组来描述:观测序列,隐藏序列,隐藏态起始概率,隐藏态之间转换概率(转移概率),隐藏态表现为观测值的概率(发射概率)。其中起始概率,转移概率和发射概率可以通过大规模样本统计来得到。
例如在分词中,HMM的五元组分别为
- 观测序列:语句本身,我们能看见的
- 隐藏序列:由BMES构成的分词标注序列,上篇文章详细讲解了的。每个汉字可以由BMES来进行标注,B表示词语的开始,M词语中间,E词语结束,S单字词语。比如“有意见分歧”对应的标注有两种,为SBEBE和BESBE,分别对应分词序列“有/意见/分歧”和“有意/见/分歧”。
- 发射概率:隐藏值到观测值的概率,比如S是汉字“有”的概率。
- 起始概率:隐藏值起始概率,起始只能是B或者S,通过语料大规模训练可以得到B和S作为起始的概率。结果为{‘B’: 0.769, ‘E’: 0, ‘M’: 0, ‘S’: 0.231},可见起始为B的概率要远大于S,这也符合我们通常情况。
- 转移概率:隐藏值之间转移的概率,比如B->E, 表示为P(E|B), B->M, 表示为p(M|B)
下面来看预测时,HMM的工作过程。以“有意见分歧”这个语句进行分词举例。最终我们要得到这个观测语句的隐藏序列,也就是BEMS序列。
- 计算第一个字,也就是“有”分别为BEMS四个隐藏态的概率。通过发射概率和起始概率的乘积得到。
- p1(B|“有”) = p(B起始概率) * p(“有” -> B)
- p1(E|“有”) = p(E起始概率) * p(“有” -> E) = 0
- p1(M|“有”) = p(M起始概率) * p(“有” -> M) = 0
- p1(S|“有”) = p(S起始概率) * p(“有” -> S)
- 计算第2个字,也就是“意”分别为BEMS四个隐藏态的概率。
- p2(B|“意”) = p1(B) x p2(B -> B) x p2(“意” -> B) + p1(S) x p2(S -> B) x p2(“意” -> B)
- p2(E|“意”) = p1(B) x p2(B -> E) x p2(“意” -> E) + p1(S) x p2(S -> E) x p2(“意” -> E)
- p2(M|“意”) = p1(B) x p2(B -> M) x p2(“意” -> M) + p1(S) x p2(S -> M) x p2(“意” -> M)
- p2(S|“意”) = p1(B) x p2(B -> S) x p2(“意” -> S) + p1(S) x p2(S -> S) x p2(“意” -> S)
- 计算第3个字,也就是“见”分别为BEMS四个隐藏态的概率。方法和第二个字计算方法相同。
- 依次计算后面的每一个字,为BEMS四个隐藏态的概率。
- 选取最后一个字,对应为BEMS中概率最大的状态,作为最终态。然后回溯,依次推导出倒数第二个字,第三个字的BEMS状态。比如上面p2来倒推p1时,如果第二个字为B的概率最大,则可以看到p2(B)由两个概率相加得到的,即p1(B) x p2(B -> B) x p2(“意” -> B)和p1(S) x p2(S -> B) x p2(“意” -> B) ,然后比较这两者的大小,选取大的。如果p1(B) x p2(B -> B) x p2(“意” -> B)大,则可以倒推得到p1应该为B。
- 回溯完成后,就可以得到所有字的BEMS状态了。也就是根据观测序列得到了隐藏序列。
HMM在序列问题,特别是自然语言处理中应用十分广泛。
条件随机场CRF
条件随机场也是解决序列问题的,和HMM隐马尔科夫很相似。不同在于HMM是生成式的,而CRF是判别式的。
3 总结
机器学习算法具有泛化能力强的优点,使得人工智能称为了可能。算法很多,实现也较为复杂。当前,机器学习的一大分支,深度学习十分火热。跟其他算法相比,深度学习具有领域知识门槛低,泛化强,精度高的优点。但同时,他对计算能力和计算数据的要求也特别高。在计算数据规模不够大时,我们可以考虑利用传统的机器学习算法。故掌握机器学习算法也是十分必要的。