前言:
工程实践结题了,研一生活暂告一段落,这两天在整理文档的过程中发现有些感悟可以记录下。工程实践是做一个图像分类模型,模型侧重点在于数据集中包含了医学类的图像,我们的目的就是能够从茫茫图像中找到它。
完整工程代码在这:Github
迁移学习:
出于硬件条件以及数据集来源的限制,我从一开始就想到了迁移学习的方法,利用已经训练成熟的模型去做调整。迁移学习有很多方式,可以大致分为三种:利用模型结构、提取瓶颈特征(bottleneck features )、微调(Fine-tuning)
利用模型结构
这个是最基础的迁移学习,只利用别人的模型框架,所有权重重新训练。但是这种迁移学习并不适合设备条件差的我。。。
提取瓶颈特征(bottleneck features )
简单来说,将图片数据input到已经训练好的模型(本文用的VGG16),但不是为了得到最后一层的output,而是从中间的某一层抽取出来作为bottleneck features。因为深度学习中间过程其实都是在提取特征,我们可以自己选择某一层作为bottleneck features。如下图:
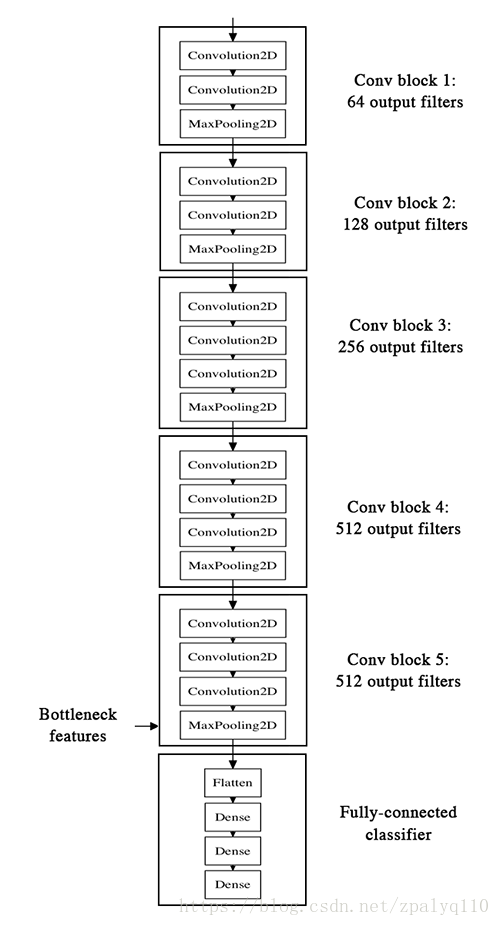
具体步骤:
1:载入去掉top层的model
2:提取bottleneck features,保存到本地
3:搭建小型分类模型,从本地读取bottleneck features,作为输入进行训练
这种迁移学习的方式已经满足了我对准确率的要求,达到80%
微调(Fine-tuning)
与提取瓶颈特征的区别在于,Fine-tuning释放了最后一个卷积层的权重,当然释放那一层都可以,按需释放即可。如下图:
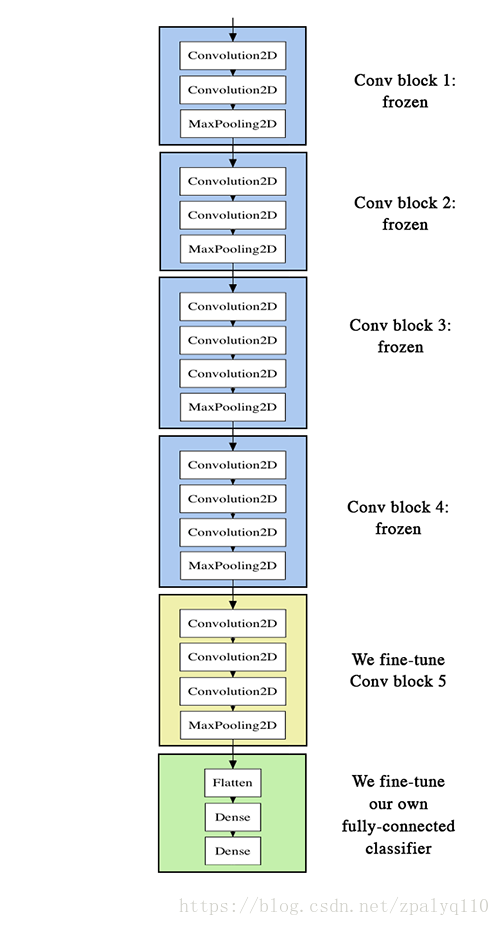
蓝色:权重锁定,不可用训练
黄色:权重释放,可以训练
绿色:最终分类器,可训练
在构建这个迁移学习的模型时遇到了大坑,官网文档是错误的,搜索了很多解决方案没有可行的,最后利用了一个小技巧跑通了模型。具体如下:
1:官网给的例子是用了前面提取瓶颈特征时构建的分类器作为VGG16的top层,代码如下:
# 载入没有top层的VGG16
model = applications.VGG16(weights='imagenet',include_top=False)
# 构建和提取瓶颈方法一样的网络结构
top_model = Sequential()
top_model.add(Flatten(input_shape=model.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(1, activation='sigmoid'))
# 将提取瓶颈方法训练保存的权重加载进去
top_model.load_weights(top_model_weights_path)
# 将刚搭建好的模型连接到VGG16上,这里会报错!!!!!!
model.add(top_model) 为什么要大费周折载入之前训练好的top层的权重,然后再重新训练呢?官网给的解释是这样可以在训练是不用随机初始化权重,不容易过拟合。
然后,将最后一个卷积层的权重释放掉:
for layer in model.layers[:25]:
layer.trainable = False 这个方案看起来很美好,但是它居然报错。。。
最后一句报错,为什么?因为VGG16源码是Model模式的,而我们搭建的是Sequential模式的,所以不兼容导致报错。
2: 既然不兼容那就让它们兼容呗——用Model模式编写,说起来很简单,但是目前为止各大技术论坛上都没有找到靠谱的解决方案。因为用Model写投票层时会用到Flatten层,这一层尝试各种方式都会报错。
3: 既然都不能解决问题,那么就从源头换个角度思考。我们费这么大劲载入top层的权重然后重新训练,不如直接跳过这一步,过拟合什么的解决方案很多,最关键的是能跑通的方案才算得上是一个方案。
下面就是我的解决思路了:
1:将VGG16全部load进来
2:将最后三层pop掉,再加上三层自己需要的Dense层
3:释放掉最后一个卷积块的权重,训练
def vgg16_model(img_rows, img_cols, num_classes=5):
model = VGG16(weights='imagenet', include_top=True)
model.layers.pop()
model.layers.pop()
model.layers.pop()
model.outputs = [model.layers[-1].output]
x=Dense(1024, activation='relu')(model.layers[-1].output)
x=Dense(128, activation='relu')(x)
x=Dense(num_classes, activation='softmax')(x)
model=Model(model.input,x)
for layer in model.layers[:15]:
layer.trainable = False
sgd = SGD(lr=1e-3, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(optimizer=sgd, loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()
return model完整工程代码在这:Github
Github大文件上传:
深度学习的模型存成 H5 文件之后非常大,VGG16有500M+,我迁移学习之后的模型又200M+,如果上传到Github上面会被限制,单文件不得超过100M。
最好用的方法是利用Git LFS工具上传, 从官网https://git-lfs.github.com/ 下载最新版本并安装。在需要push的文件下打开一个git bash命令行
1. 跟踪你要push的大文件的文件类型 (以H5作为例子)
git lfs track "*.h5"
2. 添加 gitattributes文件,这步及其关键,后面步骤和之前一样
git add .gitattributes
3. 添加其他文件并commit,push
git add yourLargeFile.h5
git add test.txt
git commit -m "something"
git push -u origin master
原理:LFS跟踪大文件,临时存储,在需要的时候才会存储复制操作,亲测git clone有效。
可能碰见的坑:github 和 git bash没有保持统一更新,所以保持同步一下就行。