
01、文章任务
从提供的金融文本中识别出现的未知金融实体,包括金融平台名、企业名、项目名称及产品名称。持有金融牌照的银行、证券、保险、基金等机构、知名的互联网企业如腾讯、淘宝、京东等和训练集中出现的实体认为是已知实体。
02、任务分析
1、任务本质
使用BERT实体识别微调方法完成任务。
2、数据分析
针对赛题数据集,我们进行了较为详细的统计和分析。数据集中的文本长度分布如图1所示,文本长度0~500的数据有3615条,超过500的则有6390条。大部分数据文本长度较长。其中文本最短长度为4,最大长度为32787,平均长度为1311。在训练集中还存在200多条数据有标签谬误。数据集中出现了部分噪声,包括一些HTML文字和特殊字符。可以看出,数据集存在文本过长,噪声过多等问题。
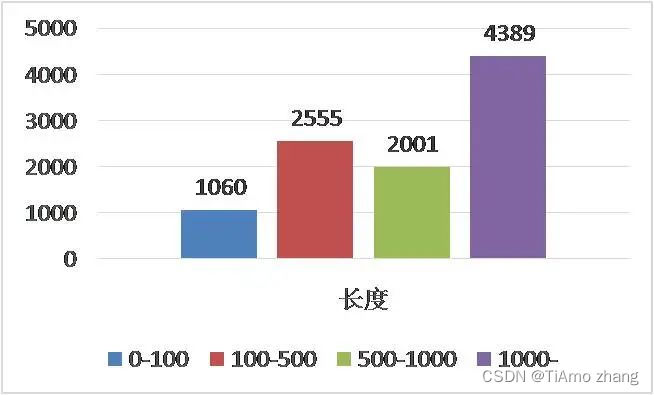
▍图1 文本长度统计
实验流程如图2所示。
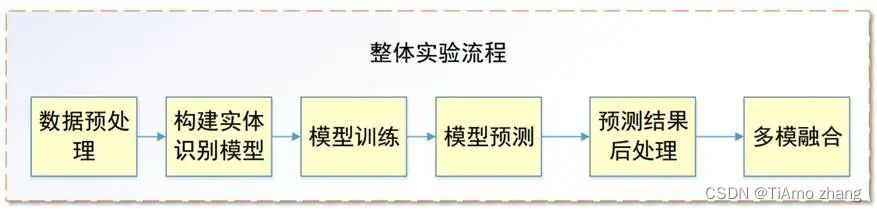
▍图2 实验流程图
03、实验代码
因为整个项目代码比较长,我们将按照顺序给出每一个部分的核心代码。
1、模型构建
我们尝试使用了多种开源的预训练模型(BERT,ERNIE, BERT_WWM, ROBERTA[4]),并分别下接了IDCN-CRF与BILST-CRF两种结构来构建实体抽取模型。本节介绍的单模以预训练模型BERT作为基准模型来举例。
a●BERT-BILSTM-CRF
BILSTM-CRF是目前较为流行的命名实体识别模型。将BERT预训练模型学习到的token向量输入BILSTM模型进行进一步学习,让模型更好的理解文本的上下关系,最终通过CRF层获得每个token的分类结果。BERT-BILSTM-CRF模型图如图3所示。
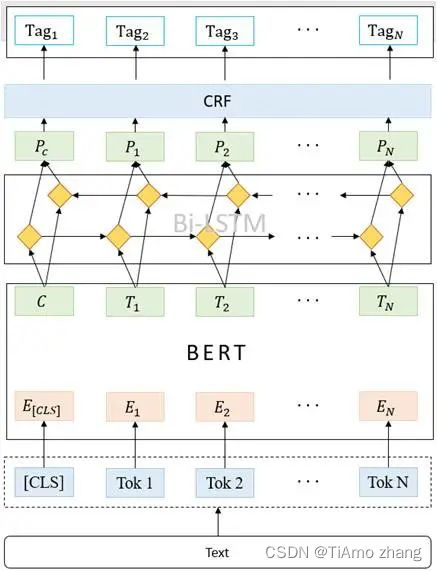
▍图3 BERT-BILSTM-CRF结构图
b●BERT-IDCNN-CRF
EmmaStrubell等人首次将IDCNN用于实体识别。IDCNN通过利用空洞(即补0)来改进CNN结构,在丢失局部信息的情况下,捕获长序列文本的长距离信息,适合当前长文本的数据集。该方法比传统的CNN具有更好的上下文和结构化预测能力。而且与LSTM不同的是,IDCNN即使在并行的情况下,对长度为N的句子的处理顺序也只需要O(n)的时间复杂度。BERT-IDCNN-CRF模型结构如图4所示。该模型的精度与BERT-BILSTM-CRF相当。模型的预测速度提升了将近50%。
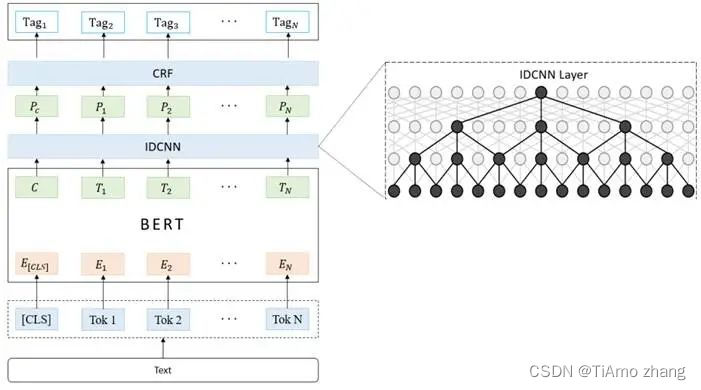
▍图4 BERT-IDCNN-CRF结构图
c●BERT多层表示的动态权重融合
Ganesh Jawahar等人通过实验验证了BERT每一层对文本的理解都有所不同。为此,我们对BERT进行了改写,将BERT的12层transformer生成的表示赋予一个权重,权重的初始化如式(1)所示,而后通过训练来确定权重值,并将每一层生成的表示加权平均,再通过一层全连接层降维至512维如式(2)所示,最后结合之前的IDCNN-CRF和BILSTM-CRF模型来获得多种异构单模。BERT多层表示的动态权重融合结构如图5所示。其中为BERT每一层输出的表示,为权重BERT每一层表示的权重值。

(1)
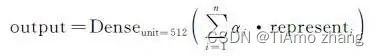
(2)

▍图 5 BERT动态权重融合
对使用动态融合的RoBERTa-BILSTM-CRF和未使用动态融合的相同模型结果进行了对比,结果如表1所示。通过表中的结果,可以看到加入了动态融合的方法使单模成绩提高了1.4%。值得一提的是,我们通过BERT动态权重融合的方法,得到了该赛题得分最高的单模。
表1 两种异构单模结果对比表

d●模型构建
代码在model.py,我们可以通过config.py来控制是否对BERT进行动态权重融合,也可以控制使用哪种模型结构,代码如下:
//获取到StreamController的stream,即出口可以取数据1. # /chapter8/CCF_ner/model.py
2. def __init__(self, config):
3. self.config = config
4. # 喂入模型的数据占位符
5. self.input_x_word = tf.placeholder(tf.int32, [None, None], name="input_x_word")
6. self.input_x_len = tf.placeholder(tf.int32, name='input_x_len')
7. self.input_mask = tf.placeholder(tf.int32, [None, None], name='input_mask')
8. self.input_relation = tf.placeholder(tf.int32, [None, None], name='input_relation') # 实体NER的真实标签
9. self.keep_prob = tf.placeholder(tf.float32, name='dropout_keep_prob')
10. self.is_training = tf.placeholder(tf.bool, None, name='is_training')
11.12. # BERT Embedding
13. self.init_embedding(bert_init=True)
14. output_layer = self.word_embedding
15.16. # 超参数设置
17. self.relation_num = self.config.relation_num
18. self.initializer = initializers.xavier_initializer()
19. self.lstm_dim = self.config.lstm_dim
20. self.embed_dense_dim = self.config.embed_dense_dim
21. self.dropout = self.config.dropout
22. self.model_type = self.config.model_type
23. print('Run Model Type:', self.model_type)
24.25. # idcnn的超参数
26. self.layers = [
27. {'dilation': 1},
28. {'dilation': 1},
29. {'dilation': 2},]
30. self.filter_width = 331. self.num_filter = self.lstm_dim
32. self.embedding_dim = self.embed_dense_dim
33. self.repeat_times = 434. self.cnn_output_width = 035.36. # CRF超参数
37. used = tf.sign(tf.abs(self.input_x_word))
38. length = tf.reduce_sum(used, reduction_indices=1)
39. self.lengths = tf.cast(length, tf.int32)
40. self.batch_size = tf.shape(self.input_x_word)[0]
41. self.num_steps = tf.shape(self.input_x_word)[-1]
42.if self.model_type == 'bilstm':
43. lstm_inputs = tf.nn.dropout(output_layer, self.dropout)
44. lstm_outputs = self.biLSTM_layer(lstm_inputs, self.lstm_dim, self.lengths)
45. self.logits = self.project_layer(lstm_outputs)
46.47. elifself.model_type == 'idcnn':
48. model_inputs = tf.nn.dropout(output_layer, self.dropout)
49. model_outputs = self.IDCNN_layer(model_inputs)
50. self.logits = self.project_layer_idcnn(model_outputs)
51.52.else:
53. raise KeyError
54.55. # 计算损失
56. self.loss = self.loss_layer(self.logits, self.lengths)2、代码框架介绍
我们此次介绍的代码框架复用性与解耦性比较高。我们在这里大致说明一下怎么去使用这个框架。对于一个问题,我们首先想的是解决问题的办法,也就是模型构建部分model.py。当模型确定了,就要构建数据迭代器(utils.py)给模型输入数据了,而utils.py读入的数据是preprocess.py清洗干净的数据。
当构建以上这几部分之后,便是模型训练部分train_fine_tune.py,这个部分包含训练、验证F1和保存每一个epoch训练模型的过程。一开始训练单模得先确定单模是否有效,我们可以通过train_fine_tune.py的main函数将训练集和验证集都用验证集去表示,看一下验证集F1是否接近90%,若接近则说明模型构建部分没有出错,但不保证F1评估公式是否写错。因此,使用刚刚用验证集训练得到的模型,通过predict.py来预测验证集,人工检验预测的结果是否有效,这样子就能保证我们整体的单模流程完全没问题了。
最后就是后处理规则postprocess和融合ensemble两部分,这里的主观性比较强,一般都是根据具体问题具体分析来操作。
其中,utils.py也有main函数,可以用来检验构造的Batch数据是否有误,直接打印出来人工检验一下即可。整个框架的超参数都在config.py处设置,加强框架的解耦性,避免了一处修改,处处修改的情况。
整体的框架也可复用到其他问题上,只需要根据修改的model.py来确定输入的Batch数据格式,其他的代码文件也只是根据问题去修改相应部分,降低了调试成本。
04、源代码
https://www.jianguoyun.com/p/DQR-jOMQ9of0ChjGxv4EIAA
05、文末送书
当今社会,网络结构数据普遍存在于各行各业。如何从这些数据中挖掘出价值,并且解决实际问题,成为学界和业界共同关注的研究方向。本书共七章。第一章主要讲解为什么关心网络结构数据,介绍了R语言及常用的包,同时整理了常用的网络数据集。第二章介绍了网络结构数据的定义及分类。第三章讲解了网络结构数据的可视化,重点介绍了针对大规模网络的可视化方法及网络的动态交互式可视化。第四章介绍了描述网络特征的各种统计量及重要的网络结构。第五章重点介绍了三种经典的网络结构数据模型,第六章主要介绍了网络结构数据中社区发现的相关概念及方法,并整理了常见的评价指标及标准数据集。第七章介绍了网络结构数据分析中的链路预测问题。
本书适合网络结构数据的初学者,相关专业的学生或对网络结构数据感兴趣的读者阅读。

作者简介
潘蕊,中央财经大学统计与数学学院副教授,中央财经大学龙马学者青年学者。北京大学光华管理学院经济学博士。主要研究领域为高维数据分析、网络结构数据分析、数据挖掘与建模等。在Annals of Statistics、Journal of the American Statistical Association、《中国科学:数学》等国内外期刊发表论文多篇。著有《数据思维实践》。
张妍,女,厦门大学在读博士研究生,研究方向为网络结构数据。
高天辰,男,厦门大学在读博士研究生,研究方向为复杂网络分析。
送书规则:文章评论“人生苦短,我用Python”,截至明天中午12点,程序自动抽奖2人中奖,送书技术书籍《从零开始构建网络结构数据体系》*1本